
结构重参数化:利用参数转换解耦训练和推理结构

极市导读
作者从自己CVPR中关于结构重参数化的实验经验出发,介绍了参数化的结构及应用,并解释了他们提出的结构重参数化的构造方法及其用途。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本届CVPR收成不错,在旷视实习期间的工作RepVGG和Diverse Branch Block(也可以称之为ACNet v2)都中了。前者是VGG类极简架构,3x3卷积一卷到底,连分支结构都没有,ImageNet上可达80.5%正确率,跟SOTA架构如RegNet比都有可见的性能提升。代码和模型全都放出了,Git上已经1400+ star了。之前写了个稿子在这里:丁霄汉:RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大(CVPR-2021)
https://zhuanlan.zhihu.com/p/344324470
后者是一个通用building block,可以用一个很像Inception的block(其中包括average pooling,1x1-BN-3x3-BN连续卷积)来替换通常的卷积,极大地丰富模型的微观结构,提升多种架构的性能。有意思的点在于,这样一个复杂的block可以在训练结束后等价转换为一个卷积,因此模型的最终大小和速度(相对于使用普通卷积的模型)完全不变!
这两个工作的共同点在于用了结构重参数化技术,“重参数化宇宙”已经初具雏形:结构A对应一组参数X,结构B对应一组参数Y,如果我们能将X等价转换为Y,就能将结构A等价转换为B。同样思想的还有ACNet(ICCV-2019)和ResRep(去年做的一个剪枝方法,Res50无损压缩超过50%,也就是说从76.15%的标准模型压到76.15%,真正意义的无损)。
总的来说,我相信重参数化是很有搞头的,既可暴力提性能,也可无损搞压缩,还能简单搭架构,肯定还有很多东西可以挖掘。
论文链接:
RepVGG:https://arxiv.org/abs/2101.03697
DiverseBranchBlock:https://arxiv.org/abs/2103.13425
ACNet:https://arxiv.org/abs/1908.03930
ResRep:https://arxiv.org/abs/2007.03260
代码全都在:https://github.com/DingXiaoH
下面介绍一下重参数化思想及其应用。
结构与参数
模型中的一个卷积层、一个block等都可以称为一个结构。我们所说的参数主要指的是
(1) 学得的参数(learnable params)。
(2) 其他在训练过程中得到的参数,如batch norm(BN)累积得到的均值和标准差。
我们主要考虑那些带参数的结构,并从参数的视角来看待这些结构。例如,一个input_channels=C, output_channels=O, kernel_size=KxK的卷积层,参数为一个OxCxKxK的四阶张量,记这个张量为W。这样我们就将W和这个卷积层建立了一一对应的关系。
既然一组参数和一个结构是一一对应的,我们就可以通过将一组参数转换为另一组参数来将一个结构转换为另一个结构。例如,如果我们通过某种办法把W变成了一个(O/2)xCxKxK的张量,那这个卷积层自然就变成了一个输出通道为O/2的卷积层。
再举个最简单的例子,两个全连接层之间如果没有非线性的话就可以转换为一个全连接层。设这两个全连接层的参数为矩阵A和B,输入为x,则输出为y=B(Ax)。我们可以构造C=BA,则有y=B(Ax)=Cx。那么C就是我们得到的全连接层的参数。
结构重参数化
我们所提出的概念结构重参数化(structural re-parameterization)指的是首先构造一系列结构(一般用于训练),并将其参数等价转换为另一组参数(一般用于推理),从而将这一系列结构等价转换为另一系列结构。在现实场景中,训练资源一般是相对丰富的,我们更在意推理时的开销和性能,因此我们想要训练时的结构较大,具备好的某种性质(更高的精度或其他有用的性质,如稀疏性),转换得到的推理时结构较小且保留这种性质(相同的精度或其他有用的性质)。换句话说,“结构重参数化”这个词的本意就是:用一个结构的一组参数转换为另一组参数,并用转换得到的参数来参数化(parameterize)另一个结构。只要参数的转换是等价的,这两个结构的替换就是等价的。
下面介绍几个我们提出的构造方法及其用途。每种构造方法所对应的转换方法都只涉及非常简单的代数运算,代码也都已经开源了。
ACNet (ICCV-2019):Reparam(KxK) = KxK-BN + 1xK-BN + Kx1-BN。这一记法表示用三个平行分支(KxK,1xK,Kx1)的加和来替换一个KxK卷积。注意三个分支各跟一个BN,三个分支分别过BN之后再相加。这样做可以提升卷积网络的性能。
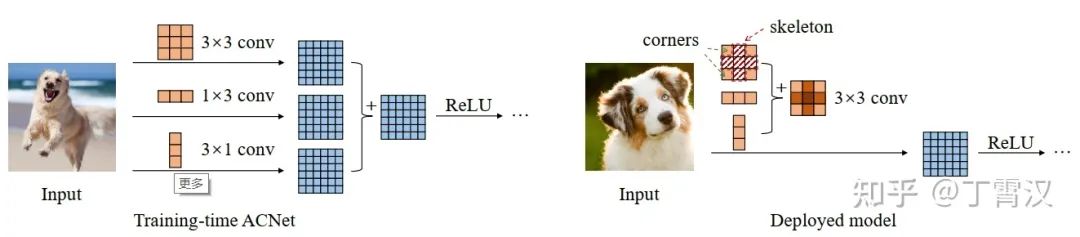
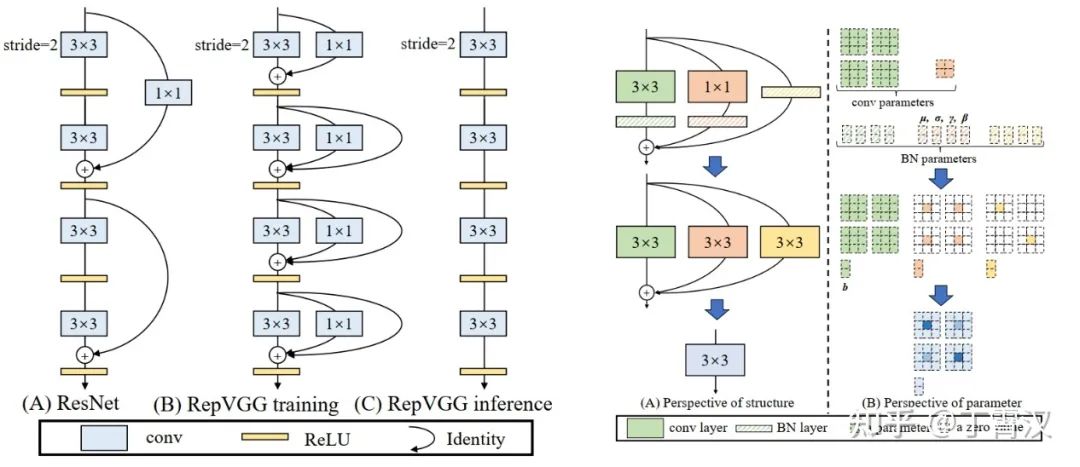
RepVGG (CVPR-2021):Reparam(3x3) = 3x3-BN + 1x1-BN + BN。对每个3x3卷积,在训练时给它构造并行的恒等和1x1卷积分支,并各自过BN后相加。我们简单堆叠这样的结构得到形成了一个VGG式的直筒型架构。推理时的这个架构仅有一路3x3卷积夹ReLU,连分支结构都没有,可以说“一卷到底”,效率很高。这样简单的结构在ImageNet上可以达到超过80%的准确率,比较精度和速度可以超过或打平RegNet等SOTA模型。
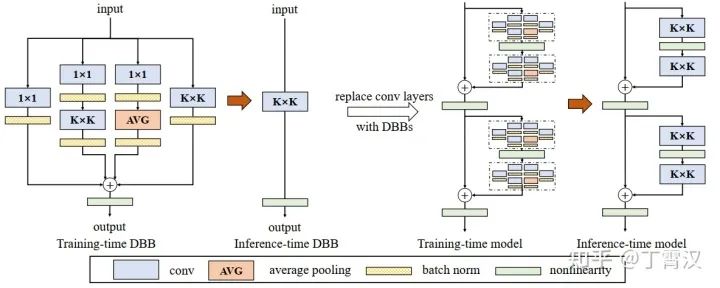
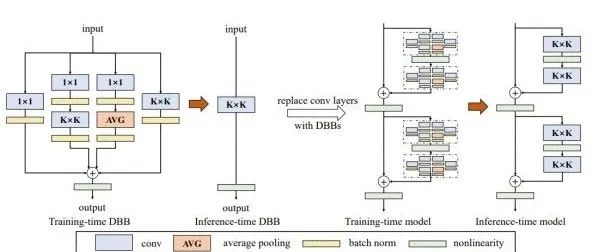
Diverse Branch Block (DBB) (CVPR-2021) :Reparam(KxK) = KxK-BN + 1x1-BN + 1x1-BN-AVG-BN + 1x1-BN-KxK-BN。本届CVPR接收的另一篇文章。跟ACNet的相似点在于都是通用的卷积网络基本模块,都可以用来替换常规卷积层。采用了更为复杂的连续卷积(1x1-BN-KxK-BN表示先过1x1卷积,再过BN,再过KxK卷积,再过另一个BN)和average pooling(记作AVG),效果超过ACNet。在这篇文章里也探索了reparam之所以work的原因,给出了一些解释。
ResRep: Reparam(KxK) = KxK-BN-1x1。这是一个剪枝(channel pruning)方法。1x1卷积初始化为单位矩阵,因而不改变模型原本的输出。然后我们通过一套特殊设计的更新规则将这个单位矩阵变得行数少于列数(即output_channels<input_channels),然后将整个KxK-BN-1x1序列转换为一个KxK卷积,从而将原本的KxK卷积的output_channels减少。这一方法能在ResNet-50上实现超过50%压缩率的情况下精度完全不掉(从76.15%的torchvision标准模型压缩到还是76.15%),据我所知这是第一个实现如此高无损压缩率的传统(结构化,非动态,非NAS)剪枝方法。
为什么会work
很多同学会有疑问,既然上面这几种方法构造出来的一套东西都可以等价转换为一个卷积,那为什么不从一开始就只训这一个卷积呢?最后的效果为什么会不一样呢?我们认为主要有以下几点原因。
(1) 推理时的等价性不代表训练时的等价性。以RepVGG为例,3x3-BN + 1x1-BN + BN最后得到的结构就是一个3x3卷积。也就是说,最终得到那一组参数是OxCx3x3,直接训一个3x3卷积最终得到的也是OxCx3x3。但这两组参数只是形状相同而已,并不代表后者的性能跟前者一样。再举个最简单的例子,一个带BN的卷积就可以等价转换为一个带bias的卷积(即工业界常说的“吸BN”),总不能说训练时前者也等价于后者嘛。至于为什么前者比后者更好,这就是一个本质上非常复杂的训练动力学(training dynamics)问题了。这个问题的解决恐怕要依赖更多“打开深度学习的黑箱”之类的工作。
(2) 大就是猛,多就是好,大力出奇迹,越多越work。一般来说,加参数总是有好处的。但是既然不能不考虑推理开销,我们就希望加一些能在推理阶段去掉的参数,事实证明这样也是有好处的。
(3) 构造的结构提供了模型本身所缺乏的某种性质,为某些花式操作提供了空间。例如,VGG式直筒模型缺乏分支结构和短的路径,我们就构造shortcut,给它加上分支和短的路径,只不过这些结构只在训练时存在而已;通道剪枝问题中“记忆”(保持模型精度不降低)和“遗忘”(制造稀疏性)耦合在一起(同一组参数同时参与记忆和遗忘有关的损失函数),我们就引入额外的1x1卷积,让这些额外的结构去“遗忘”,避免这种耦合。
(4) 构造的结构增加了“多样化的链接”和更多的“训练时非线性”。在Diverse Branch Block的实验中,我们报告了一些有意思的发现。按理说1x1卷积的表征能力弱于3x3卷积,因为前者可以看作一个有很多参数为0的3x3卷积,但是1x1 + 3x3的性能却明显好于3x3 + 3x3,也就是说一个强结构加一个弱结构好于两个强结构相加;BN虽然推理时是线性的,但训练时是非线性的,在DBB的各个分支里去掉BN则效果减弱很多。
常见问题
Q:怎样能把一个训好的ResNet-50重参数化成VGG一样的单路结构?
A:恐怕不可能,这样的转换是不存在的。应该首先确定“我想要模型具有什么性质”,进而“我想要什么样的最终结构”,然后倒推“我需要构造的训练时结构是什么样的”,以及“这样的转换是否可行,如何实现”。所以不存在“怎样把ResNet-50重参数化成VGG”这样的问题,只有“应该把推理时的VGG构造成训练时的什么样子”这样的问题。
Q:所以RepVGG/DBB/ACNet推理的时候是先算出等效的kernel和bias,然后再卷积?
A:并不是。训练完之后,我们只进行一次转换,然后只保存转换后的模型。原模型完全可以扔掉了。
Q:除了ImageNet以外,用在其他任务上效果如何?
A:ACNet的相当一部分引用量来自于去噪、去模糊等比赛的战报。RepVGG报告了Cityscapes上80.5% mIoU的结果。DBB在Cityscapes和COCO detection上也有明显提升。
推荐阅读
2021-03-01
2021-03-31
2020-04-16

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
