图解RMNet 重参数化新方法
1前言
残差网络的出现允许我们训练更深层的网络,但由于其多分支的推理,使得在推理速度上不如无残差连接的直筒网络(Plain Model)。RepVGG通过重参数的思想,将三个分支融合到一个分支中。然而使用RepVGG是无法重参数化ResNet,因为重参数方法只能应用于Linear Blocks,并且ReLU操作需要放到外面。本文我们提出Reserving和Merging两个操作(RM),在ResBlock基础上去除残差连接。相比ResNet和RepVGG,RMNet在速度精度上更好,同时也对high-ratio的剪枝操作友好。
论文:https://arxiv.org/abs/2111.00687
代码:https://github.com/fxmeng/RMNet
文章中所涉及到的代码笔者已经整理到仓库内,作为Notebook形式,https://github.com/MARD1NO/paper_reading/tree/master/RMNet,球球你们了点个star再白嫖吧
2介绍
我们总结了主要的contribution:
- 我们发现重参数化有其局限性,当非线性操作(如ReLU)放置在residual branch的时候,无法进行重参数化
- 我们提出了RM方法,能够移除残差连接,通过保留输入特征映射(Reserving)并将其与输出特征映射合并(Merging),去除非线性层间的残留连接。
- 通过这种方法我们可以将ResNet转换为一个直筒网络,能够在速度,精度上达到更好的trade off,对剪枝也十分友好
补充材料:可以参考之前写的图解RepVGG:https://zhuanlan.zhihu.com/p/352239591
3RM操作
下图展示了ResNet中的ResBlock如何去除残差连接的操作:
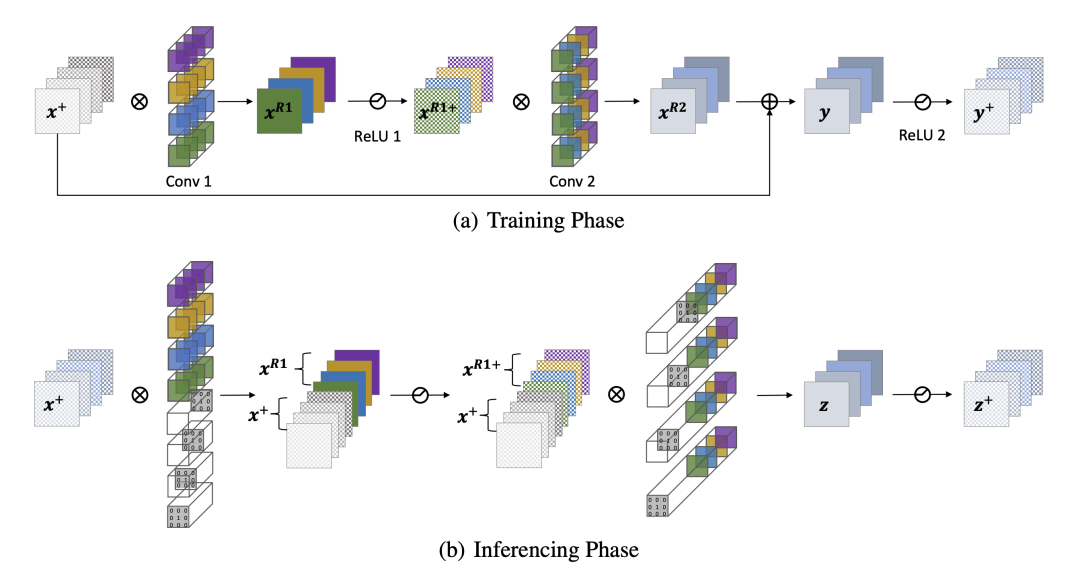
Reserving操作
假设我们的输入的通道数为4,我们在转换的时候,对Conv1插入了相同通道数的,经过Dirac初始化的卷积核,来Reserve输入特征。
关于如何让卷积操作做恒等映射的操作,在RepVGG已经详细剖析过,这里就简单复习下:
identity前后值不变,那么我会想到是用权重等于1的卷积核,并分开通道进行卷积,即1x1的,权重固定为1的Depthwise卷积。这样相当于单独对每个通道的每个元素乘1,然后再输出来,这就是我们想要的identity操作!下面是一个示意图
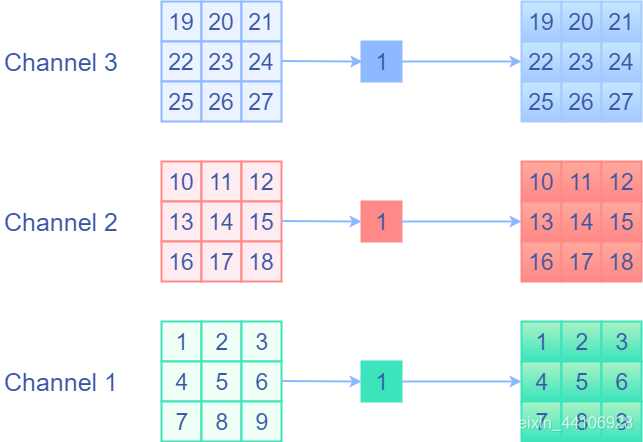 1x1Depthwise卷积等效
1x1Depthwise卷积等效我们再拓展到普通的卷积核,那就是对当前通道的权值设置为1,其他通道的权值设置为0,下面是一个示意图:
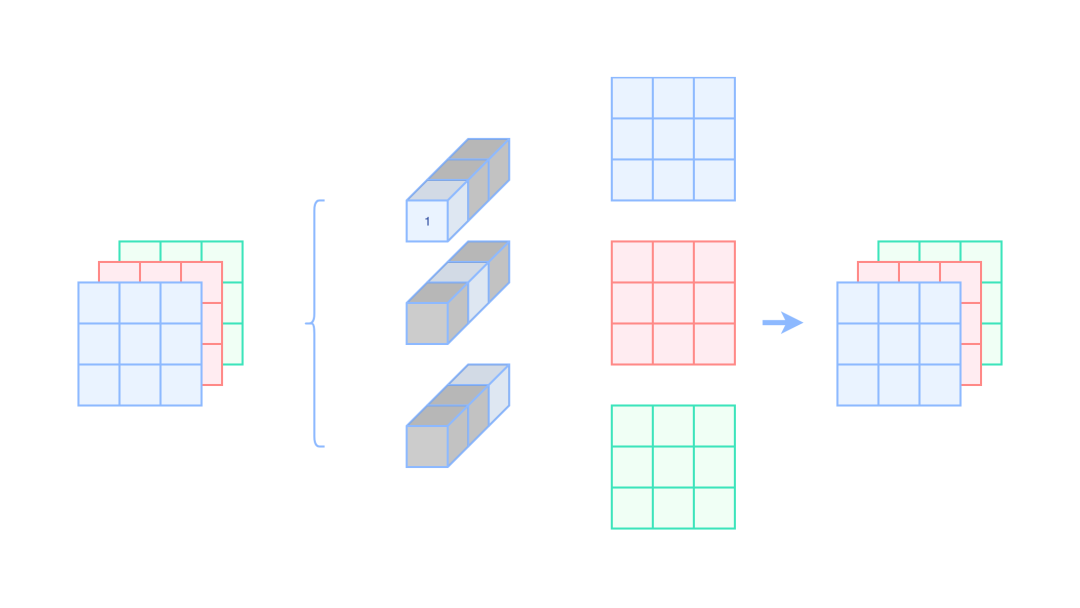 普通1x1卷积等价Identity
普通1x1卷积等价Identity其中灰色的地方均表示0
如果想要变成3x3卷积,那么我们只需要给1x1卷积周围Padding一圈0即可。
在PyTorch,初始化这种卷积核是很容易的,我们只需要调用nn.init.dirac_(your_weight),假设我们的通道数目为2,下面是示例代码:
import torch
import torch.nn as nn
# Outchannel, Inchannel, Kh, Kw
weight = torch.empty(2, 2, 3, 3)
nn.init.dirac_(weight)
"""
tensor([[[[0., 0., 0.],
[0., 1., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]],
[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 1., 0.],
[0., 0., 0.]]]])
"""
对于ReLU操作,具体可以分两种情况:
- 对于ResNet来说,每个Block最后都有一个ReLU操作。这就意味着每次进入到下一个Block的输入一定是正的。那么直接做ReLU操作是可以的,如论文图例所示:
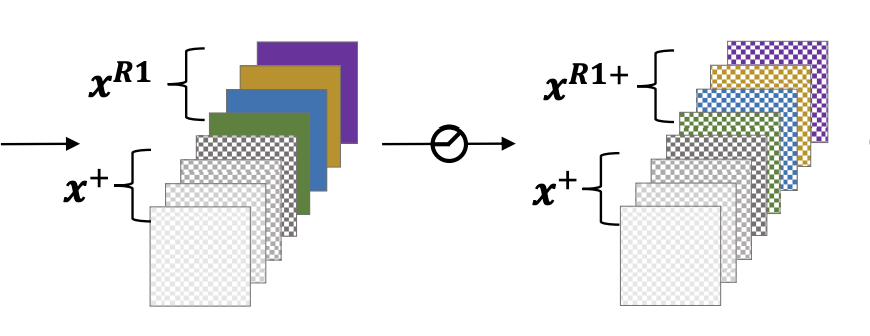
- 而对于像MobileNet2这种网络,它的ReLU操作是放置在Block中间,此时无法保证下一个Block的输入一定是正的。所以此时不能直接做ReLU操作,而是使用一个PReLU,对输入的特征将PReLU的alpha参数设置为1,以保持线性映射。而对于卷积后的特征,将PReLU的alpha参数设置为0,此时等价于ReLU。一个简单的示意图如下:
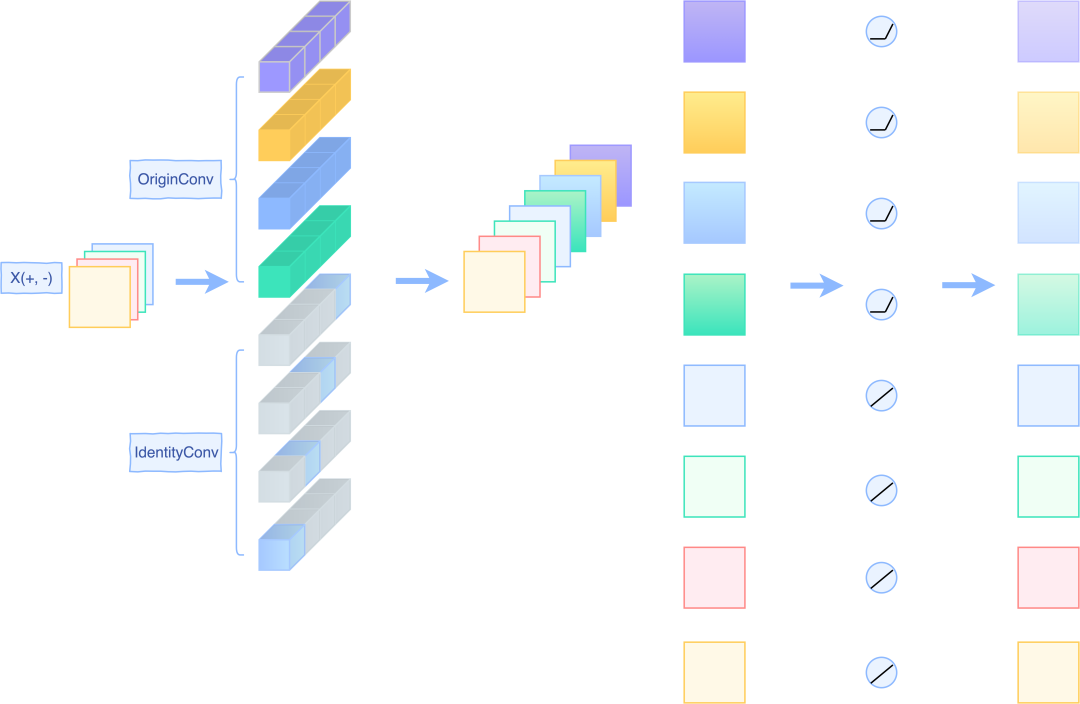 Reserve操作
Reserve操作Merge操作
我们将Dirac初始化的权重给拼接到卷积核进行卷积,这样就能等价替代残差连接了,如下图所示:
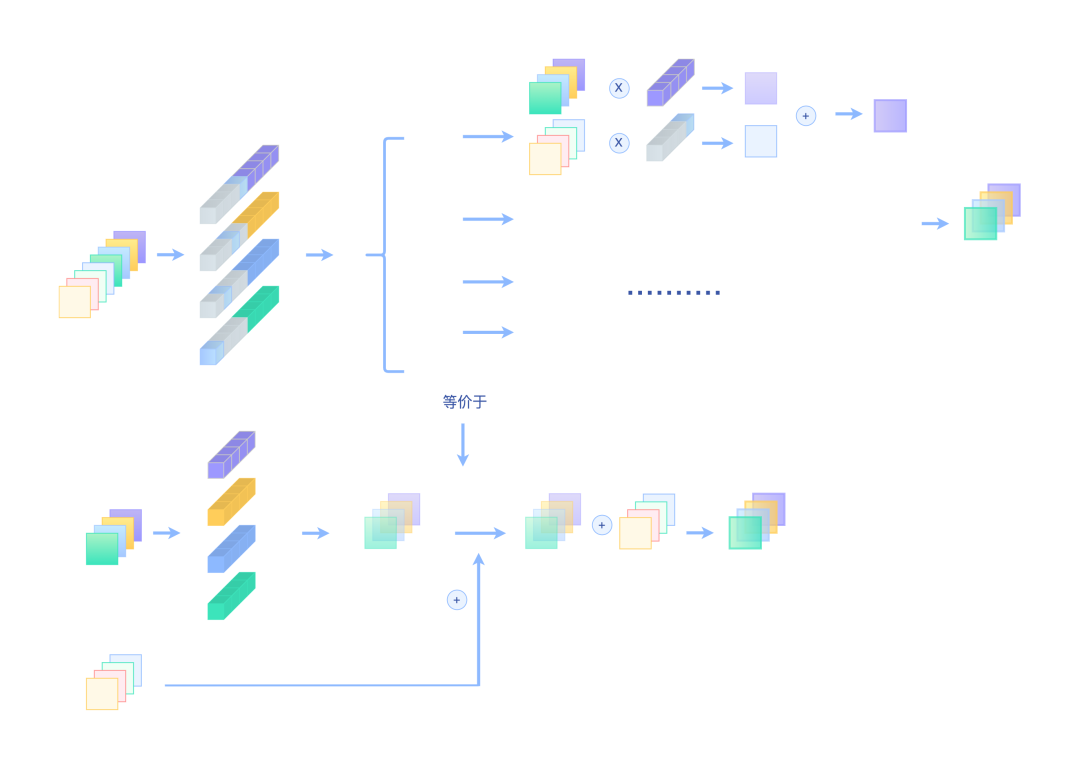 Merge的分解操作
Merge的分解操作上半部分是RMNet的做法,而下部分是一个残差连接操作,除了图示外,我们还可以通过代码来验证等价性
我们以ResBlock作为例子,其输入是个正数
import torch
import torch.nn as nn
import numpy as np
class OriginBlock(nn.Module):
def __init__(self, planes):
super(OriginBlock, self).__init__()
self.conv1 = torch.nn.Conv2d(planes, planes, kernel_size=3, padding=1, bias=False)
self.relu1 = torch.nn.ReLU()
self.conv2 = torch.nn.Conv2d(planes, planes, kernel_size=3, padding=1, bias=False)
def forward(self, x):
y = self.conv1(x)
y = self.relu1(y)
y = self.conv2(y)
return y + x
class RMBlock(nn.Module):
def __init__(self, planes):
super(RMBlock, self).__init__()
self.mid_planes = planes * 2
self.Idenconv = torch.nn.Conv2d(planes, self.mid_planes, kernel_size=1, bias=False)
nn.init.dirac_(self.Idenconv.weight.data[:planes])
nn.init.dirac_(self.Idenconv.weight.data[planes:])
self.conv1 = torch.nn.Conv2d(self.mid_planes, self.mid_planes, kernel_size=3, padding=1, bias=False)
self.relu1 = torch.nn.ReLU()
self.conv2 = torch.nn.Conv2d(self.mid_planes, planes, kernel_size=3, padding=1, bias=False)
def forward(self, x):
y = self.Idenconv(x)
y = self.conv1(y)
y = self.relu1(y)
y = self.conv2(y)
return y
planes = 4
OriginResBlock = OriginBlock(planes)
RMResBlock = RMBlock(planes)
"""
Do some initialization
"""
# For conv1
nn.init.dirac_(RMResBlock.conv1.weight.data[:planes]) # Oc, Ic, K, K
torch.nn.init.zeros_(RMResBlock.conv1.weight.data[planes:][:, :planes])
RMResBlock.conv1.weight.data[planes:][:, planes:] = OriginResBlock.conv1.weight.data
# For conv2
nn.init.dirac_(RMResBlock.conv2.weight.data[:, :planes]) # Oc, Ic, K, K
RMResBlock.conv2.weight.data[:, planes:] = OriginResBlock.conv2.weight.data
# Insure the Input is positive.
x = torch.Tensor(np.random.uniform(low=0.0, high=1, size=(1, planes, 4, 4)))
original_res_output = OriginResBlock(x)
rmblock_output = RMResBlock(x)
print("RM output is equal?: ", np.allclose(original_res_output.detach().numpy(), rmblock_output.detach().numpy(), atol=1e-3))
将ResNet转换为VGG
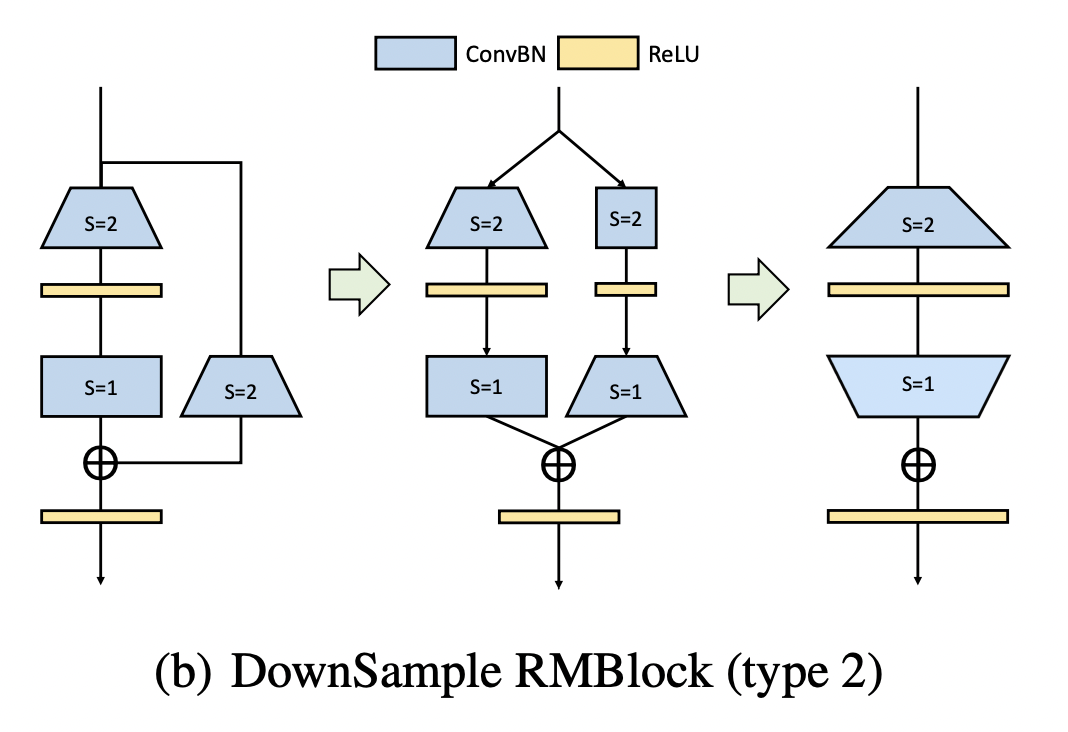
前面我们通过图示和代码,将残差连接给去除了。而ResNet中还存在下采样操作,在旁路分支会加入一个stride=2的卷积进行下采样。
针对下采样操作的转换,我们提出了两种方案:
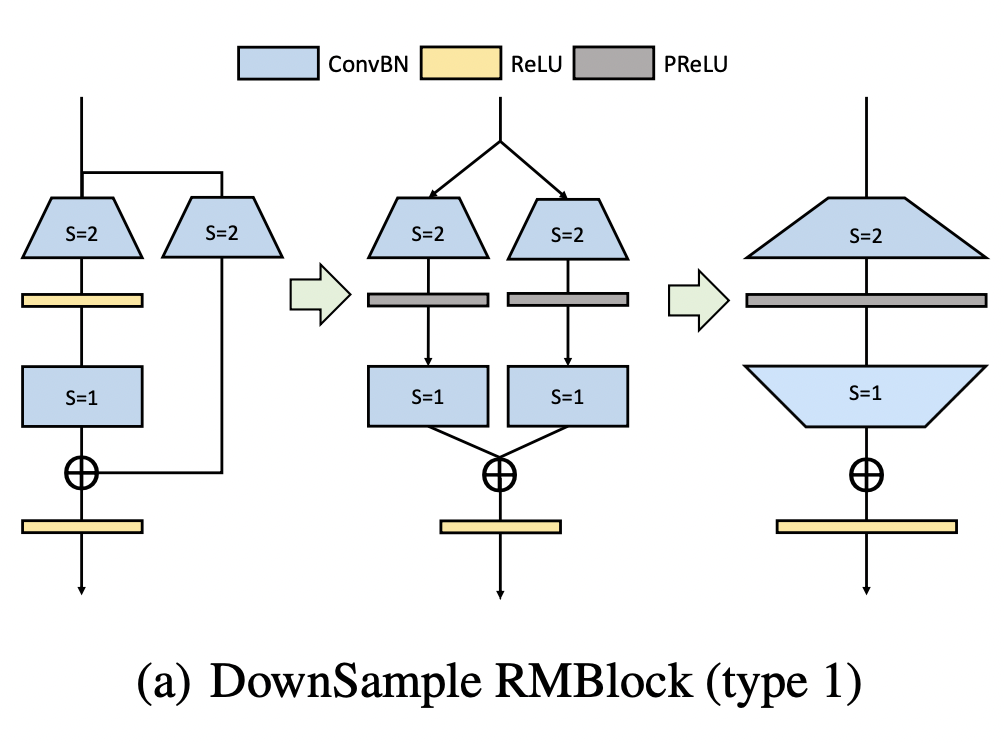 下采样操作V1
下采样操作V1第一种方案,我们将旁路分支中stride=2的1x1卷积经过pad补0填充为3x3卷积,扩张通道数。
此时卷积出来的结果有正有负(跟前面讨论的Mobilenetv2的情况类似),为了保证恒等映射,我们这里采用的是PReLU(残差分支即左边的,alpha权重为0等价于ReLU,旁路分支的alpha权重为1,等价于恒等映射)。
然后我们再接入一个Dirac初始化的3x3卷积来保证恒等映射。最后我们能融合成最右边图的情况,这三个步骤对应的代码如下:
import torch
import torch.nn as nn
import numpy as np
class OriginDownSample(nn.Module):
def __init__(self, planes):
super(OriginDownSample, self).__init__()
self.conv1 = nn.Conv2d(planes, planes * 2, kernel_size=3, stride=2, padding=1, bias=False)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(planes * 2, planes * 2, kernel_size=3, stride=1, padding=1, bias=False)
self.down_sample = nn.Conv2d(planes, planes * 2, kernel_size=1, stride=2, bias=False)
def forward(self, x):
y = self.conv1(x)
y = self.relu1(y)
y = self.conv2(y)
return y + self.down_sample(x)
class RMDownSampleStage1(nn.Module):
def __init__(self, planes):
super(RMDownSampleStage1, self).__init__()
self.conv1 = nn.Conv2d(planes, planes * 2, kernel_size=3, stride=2, padding=1, bias=False)
# Equals to ReLU.
self.prelu1 = nn.PReLU(planes*2)
nn.init.zeros_(self.prelu1.weight)
self.conv2 = nn.Conv2d(planes * 2, planes * 2, kernel_size=3, stride=1, padding=1, bias=False)
self.down_sample1 = nn.Conv2d(planes, planes * 2, kernel_size=3, stride=2, padding=1, bias=False)
# Linear Activation.
self.prelu2 = nn.PReLU(planes*2)
nn.init.ones_(self.prelu2.weight)
self.down_sample2 = nn.Conv2d(planes * 2, planes * 2, kernel_size=3, stride=1, padding=1, bias=False)
nn.init.dirac_(self.down_sample2.weight)
def forward(self, x):
branchA = self.conv1(x)
branchA = self.prelu1(branchA)
branchA = self.conv2(branchA)
branchB = self.down_sample1(x)
branchB = self.prelu2(branchB)
branchB = self.down_sample2(branchB)
return branchA + branchB
class RMDownSampleStage2(nn.Module):
def __init__(self, planes):
super(RMDownSampleStage2, self).__init__()
self.conv1 = nn.Conv2d(planes, planes * 4, kernel_size=3, stride=2, padding=1, bias=False)
self.prelu1 = nn.PReLU(planes*4)
self.conv2 = nn.Conv2d(planes * 4, planes * 2, kernel_size=3, stride=1, padding=1, bias=False)
def forward(self, x):
y = self.conv1(x)
y = self.prelu1(y)
y = self.conv2(y)
return y
planes = 2
OriginResDownSample = OriginDownSample(planes)
RMDownSample1 = RMDownSampleStage1(planes)
RMDownSample2 = RMDownSampleStage2(planes)
"""
Do Some Initialization
"""
RMDownSample1.conv1.weight = OriginResDownSample.conv1.weight
RMDownSample1.conv2.weight = OriginResDownSample.conv2.weight
# Padding from zero value to convert 1x1 to 3x3 kernel
RMDownSample1.down_sample1.weight = torch.nn.Parameter(
torch.nn.functional.pad(
OriginResDownSample.down_sample.weight.data, [1, 1, 1, 1], value=0.0)
)
x = torch.Tensor(np.random.uniform(low=0.0, high=1, size=(1, planes, 4, 4)))
original_res_output = OriginResDownSample(x)
rmblock_output = RMDownSample1(x)
print("RM output is equal?: ", np.allclose(original_res_output.detach().numpy(),
rmblock_output.detach().numpy(),
atol=1e-4))
RMDownSample2.conv1.weight = torch.nn.Parameter(
torch.cat(
[RMDownSample1.conv1.weight, RMDownSample1.down_sample1.weight], dim=0)
)
RMDownSample2.prelu1.weight = torch.nn.Parameter(
torch.cat(
[RMDownSample1.prelu1.weight, RMDownSample1.prelu2.weight], dim=0)
)
RMDownSample2.conv2.weight = torch.nn.Parameter(
torch.cat(
[RMDownSample1.conv2.weight, RMDownSample1.down_sample2.weight], dim=1)
)
rmblock_outputv2 = RMDownSample2(x)
print("RM output is equal?: ", np.allclose(rmblock_outputv2.detach().numpy(),
rmblock_output.detach().numpy(),
atol=1e-4))
 下采样操作V2
下采样操作V2第二种方案,先采用大小3x3,stride=2的恒等映射卷积,降低分辨率。再用stride=1的3x3卷积扩张通道数,对应代码:
import torch
import torch.nn as nn
import numpy as np
class OriginDownSample(nn.Module):
def __init__(self, planes):
super(OriginDownSample, self).__init__()
self.conv1 = nn.Conv2d(planes, planes * 2, kernel_size=3, stride=2, padding=1, bias=False)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(planes * 2, planes * 2, kernel_size=3, stride=1, padding=1, bias=False)
self.down_sample = nn.Conv2d(planes, planes * 2, kernel_size=1, stride=2, bias=False)
def forward(self, x):
y = self.conv1(x)
y = self.relu1(y)
y = self.conv2(y)
return y + self.down_sample(x)
class RMDownSampleV2Stage1(nn.Module):
def __init__(self, planes):
super(RMDownSampleV2Stage1, self).__init__()
self.conv1 = nn.Conv2d(planes, planes * 2, kernel_size=3, stride=2, padding=1, bias=False)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(planes * 2, planes * 2, kernel_size=3, stride=1, padding=1, bias=False)
self.identity_down_sample = nn.Conv2d(planes, planes, kernel_size=3, stride=2, padding=1, bias=False)
nn.init.dirac_(self.identity_down_sample.weight)
self.relu2 = nn.ReLU()
self.down_sample2 = nn.Conv2d(planes, planes * 2, kernel_size=3, stride=1, padding=1, bias=False)
def forward(self, x):
branchA = self.conv1(x)
branchA = self.relu1(branchA)
branchA = self.conv2(branchA)
branchB = self.identity_down_sample(x)
branchB = self.relu2(branchB)
branchB = self.down_sample2(branchB)
return branchA + branchB
class RMDownSampleV2Stage2(nn.Module):
def __init__(self, planes):
super(RMDownSampleV2Stage2, self).__init__()
self.conv1 = nn.Conv2d(planes, planes * 3, kernel_size=3, stride=2, padding=1, bias=False)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(planes * 3, planes * 2, kernel_size=3, stride=1, padding=1, bias=False)
def forward(self, x):
y = self.conv1(x)
y = self.relu1(y)
y = self.conv2(y)
return y
planes = 2
OriginResDownSample = OriginDownSample(planes)
RMDownSample1 = RMDownSampleV2Stage1(planes)
RMDownSample2 = RMDownSampleV2Stage2(planes)
"""
Do Some Initialization
"""
RMDownSample1.conv1.weight = OriginResDownSample.conv1.weight
RMDownSample1.conv2.weight = OriginResDownSample.conv2.weight
# Padding from zero value to convert 1x1 to 3x3 kernel
RMDownSample1.down_sample2.weight = torch.nn.Parameter(
torch.nn.functional.pad(
OriginResDownSample.down_sample.weight.data, [1, 1, 1, 1], value=0.0)
)
x = torch.Tensor(np.random.uniform(low=0.0, high=1, size=(1, planes, 4, 4)))
original_res_output = OriginResDownSample(x)
rmblock_output = RMDownSample1(x)
print("RM output is equal?: ", np.allclose(original_res_output.detach().numpy(),
rmblock_output.detach().numpy(),
atol=1e-4))
RMDownSample2.conv1.weight = torch.nn.Parameter(
torch.cat(
[RMDownSample1.conv1.weight, RMDownSample1.identity_down_sample.weight], dim=0)
)
RMDownSample2.conv2.weight = torch.nn.Parameter(
torch.cat(
[RMDownSample1.conv2.weight, RMDownSample1.down_sample2.weight], dim=1)
)
rmblock_outputv2 = RMDownSample2(x)
print("RM output is equal?: ", np.allclose(rmblock_output.detach().numpy(),
rmblock_outputv2.detach().numpy(),
atol=1e-4))
这两种方案参数量分别为
- 方案1:
Conv1(C*4C*3*3) + PReLU(4C) + Conv2(4C*2C*3*3) = 108C^2 + 4C - 方案2:
Conv1(C*3C*3*3) + Conv2(3C*2C*3*3) = 81C^2
方案2的参数量仅为方案1的75%,因此我们选用的是方案2
将MobileNetV2转换为MobileNetV1
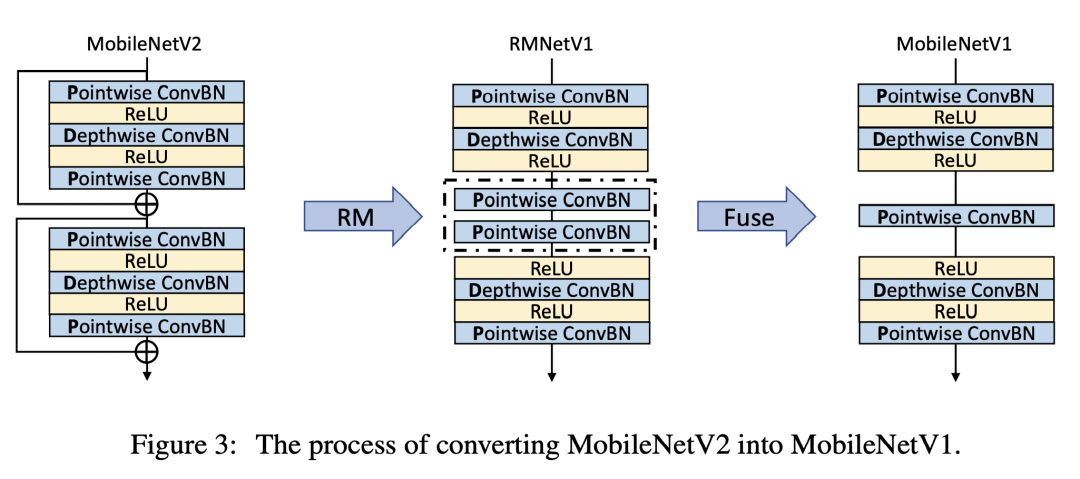 转换为MobileNetV1
转换为MobileNetV1这部分思想和前面的类似,笔者这里仅简单描述下,首先通过RM操作去除残差分支。然后中间的两个卷积层,可以融合为一个卷积层,对应公式如下:
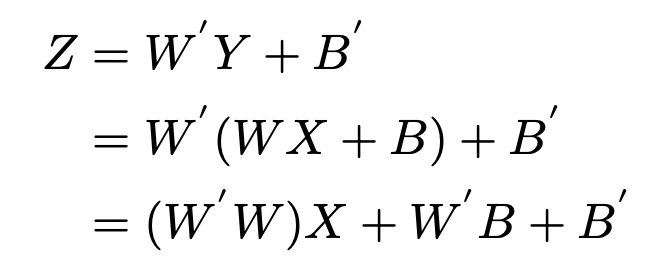 融合卷积层公式
融合卷积层公式剪枝
当我们移除残差操作后,对剪枝操作也是很友好的,RMNet能以更高的比例去剪枝: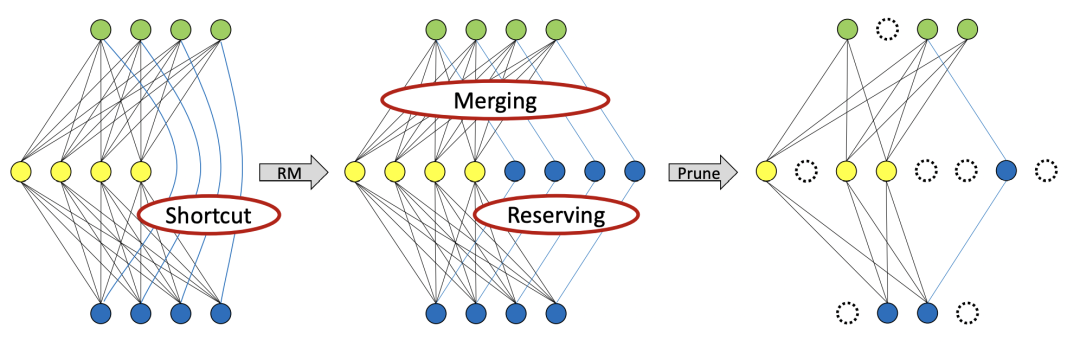
4实验
实验部分笔者也简单介绍,有兴趣的读者可以翻看原文。
首先作者展示了在深度加深的情况下,RepVGG和RMNet的结果。由于RepVGG没有跨层残差连接,在网络加深的情况下,反而出现精度下降,而RMNet的精度一直在线:
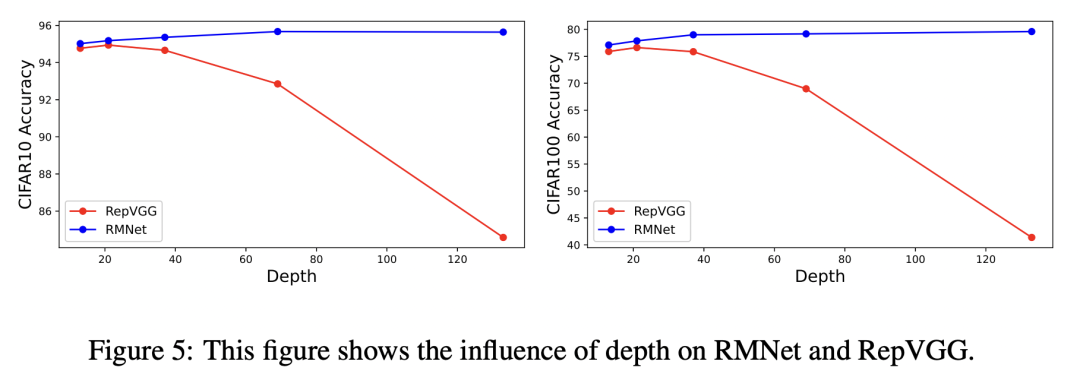 网络加深的影响
网络加深的影响通过设置分组卷积通道数以及合适的扩张宽度,RMNet也能在精度和速度上达到一个很好的Trade-off。其中RMNet 50x6_32 表示深度为50层,6代表width ratio,而32代表每个分组的卷积通道数。在和RepVGG相同的实验条件下进行比较:
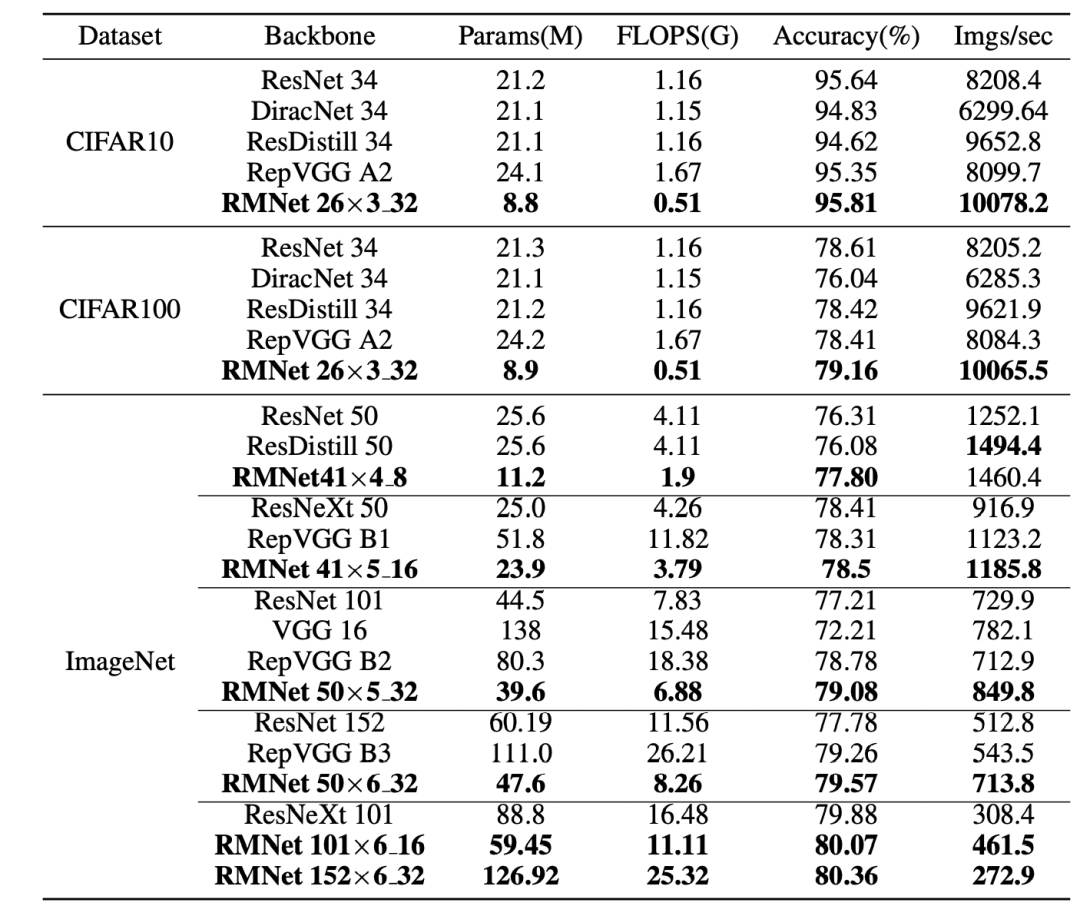 各数据集比较
各数据集比较最后是一个剪枝的实验:
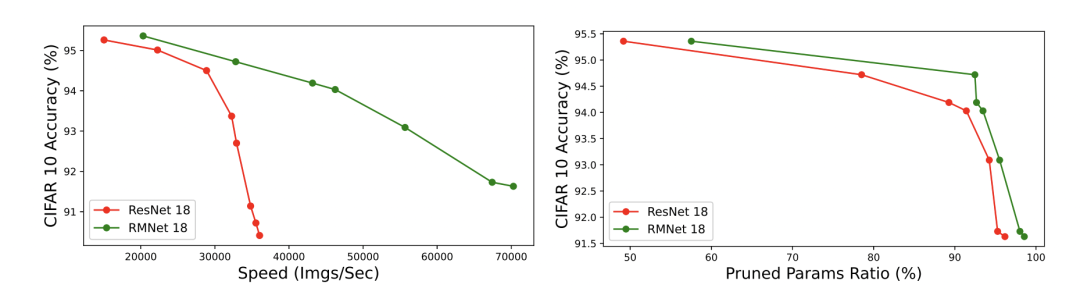 剪枝实验
剪枝实验5结论
在笔者看来,这是一篇诚意满满的工作。作者提出的RM操作,在原始的重参数思想发展,去除了让人又爱又恨的残差连接。虽然这种操作会让网络通道数翻倍,但是可以应用高ratio的剪枝操作来弥补了这一缺陷。十分推荐各位去阅读其代码~