
爬虫实战 | 用Python爬取指定关键词的微博~

前几天学校一个老师在做微博的舆情分析找我帮她搞一个用关键字爬取微博的爬虫,再加上最近很多读者问微博爬虫的问题,今天小编来跟大家分享一下。
01
分析页面
我们此次选择的是从移动端来对微博进行爬取。移动端的反爬就是信息校验反爬虫的cookie反爬虫,所以我们首先要登陆获取cookie。
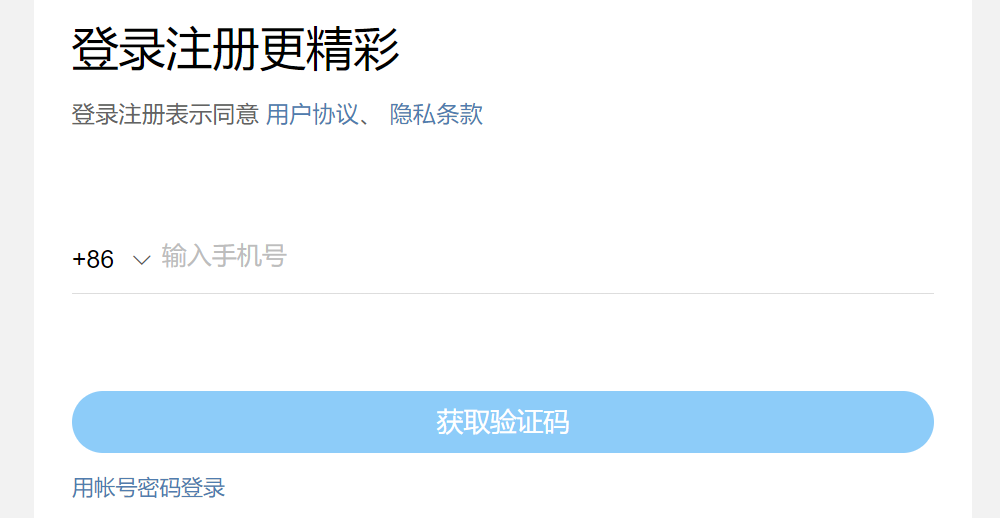
登陆过后我们就可以获取到自己的cookie了,有不懂的小伙伴可以看这篇文章学会Cookie,解决登录爬取的困扰!。然后我们来观察用户是如何搜索微博内容的。
平时我们都是在这个地方输入关键字,来进行搜索微博。

我通过在开发者模式下对这个页面观察发现,它每次对关键字发起请求后,就会返回一个XHR响应。
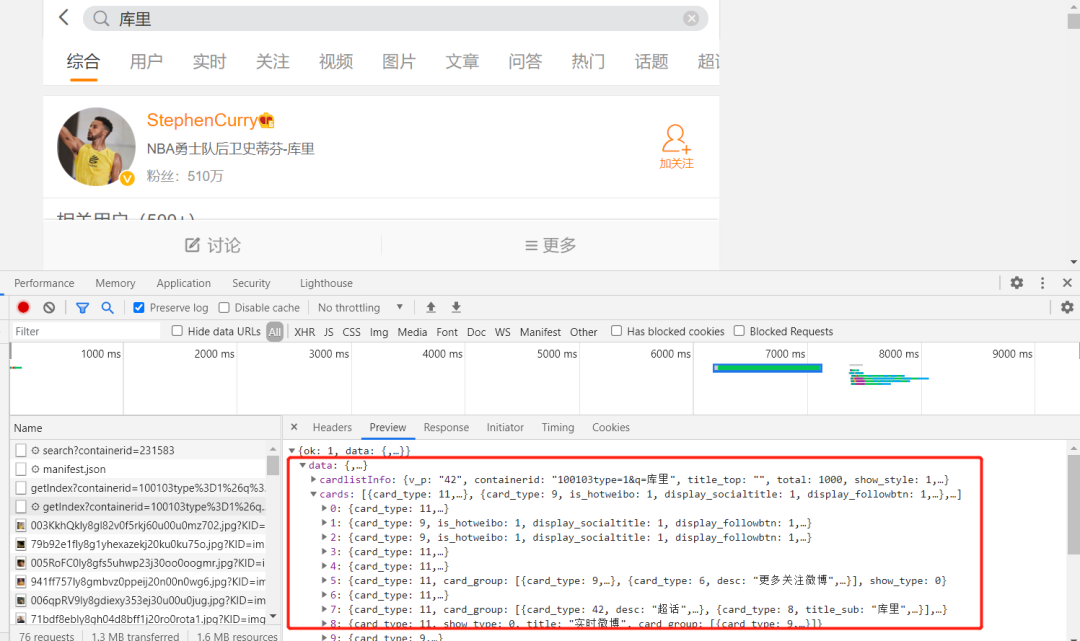
我们现在已经找到数据真实存在的页面了,那就可以进行爬虫的常规操作了。
02
数据采集
在上面我们已经找到了数据存储的真实网页,现在我们只需对该网页发起请求,然后提取数据即可。
01
发起请求
通过对请求头进行观察,我们不难构造出请求代码。
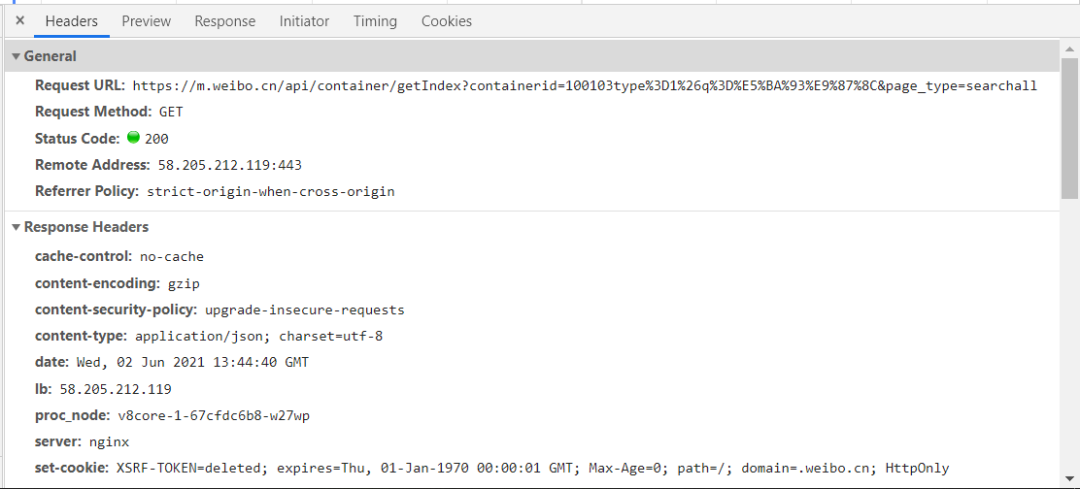
代码如下:
key = input("请输入爬取关键字:")
for page in range(1,10):
params = (
('containerid', f'100103type=1&q={key}'),
('page_type', 'searchall'),
('page', str(page)),
)
response = requests.get('https://m.weibo.cn/api/container/getIndex', headers=headers, params=params)
02
提取数据
从上面我们观察发现这个数据可以转化成字典来进行爬取,但是经过我实际测试发现,用正则来提取是最为简单方便的,所以这里展示的是正则提取的方式,有兴趣的读者可以尝试用字典方式来提取数据。代码如下:
r = response.text
title = re.findall('"page_title":"(.*?)"',r)
comments_count = re.findall('"comments_count":(.*?),',r)
attitudes_count = re.findall('"attitudes_count":(.*?),',r)
for i in range(len(title)):
print(eval(f"'{title[i]}'"),comments_count[i],attitudes_count[i])
在这里有一个小问题要注意,微博的标题是用Unicode编码的,如果直接爬取存储,将存储的是Unicode编码,在这里要感谢大佬—小明哥的帮助,小编在网上搜了好多解决方法都没有成功,最后一个简单的函数就给解决了,实在是佩服!
解决方案:用eval()来输出标题,就可以将Unicode转换成汉字了。
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|
年度爆款文案
点阅读原文,领廖雪峰视频资料!

