
基于表征学习的行人重实别

在本节中,我们使用表征学习进行行人的重识别。具体的流程如下:在训练时,我们输入数据进入深度神经网络,提取出特征向量,然后连接一个FC层进行softmax分类。这就称为ID损失,在训练集中行人的ID数为网络的类别数。而在测试时,我们一般使用到倒数第二层的特征向量进行检索,将FC层丢弃。
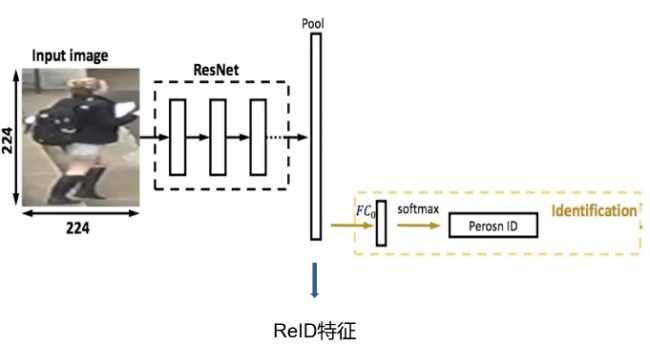
#1 数据集
DukeMTMC-reID
在数据集方面,我们使用了DukeMTMC-reID数据集,这是在杜克大学内采集的,图像来自8个不同的摄像头。该数据集提供训练集和测试集。训练集包含16522张图像,测试集包含1761张图像。训练集几乎共有702人,平均每个人有23.5张训练数据。是目前最大的行人重识别数据集,并且提供了行人属性,如性别,长短袖,是否有背包等标注。

接下来,我们进行数据处理,首先,我们先观察数据的命名格式,发现数据的命名是00xx_**_**.jpg。后面的不用管,我们的目的是提取对应行人的索引。所以可以对_前的数值进行提取,新建一个data2txt.py写入如下代码:
import osdata_path=r'E:\DataSets\DukeMTMC-reID\DukeMTMC-reID\bounding_box_train'image_paths=[os.path.join(data_path,p)for p in os.listdir(data_path)]nameid=[]for image_path in image_paths:name=image_path.split('\\')[-1].split('_')[0]if name+'\n' not in nameid:nameid.append(name+'\n')with open('name.txt','w',encoding='utf8') as f:f.writelines(nameid)
运行程序,我们会发现多了一个name.txt文件,里面存放着我们的标签数据,接着,我们新建一个load_data.py文件,写入如下代码,用来组合文件路径以及打乱数据集:
import osimport randomimport cv2import numpy as np# 加载文件路径def load_data():path=r'E:\DataSets\DukeMTMC-reID\DukeMTMC-reID\bounding_box_train'image_names=os.listdir(path)with open('name.txt','r',encoding='utf8') as f:names=f.readlines()data=[]label=[]# 组合路径for index,name in enumerate(names):n=name.strip('\n')image_paths=[os.path.join(path,i) for i in image_names if i.startswith((n))]for image_path in image_paths:data.append(image_path)label.append(index)# 随机打乱random_seed=random.randint(1,1000)random.seed(random_seed)random.shuffle(data)random.seed(random_seed)random.shuffle(label)return data,label
接着,我们需要将数据集制作成生成器的形式:
def gan_data(data,label,batch_size,n_classes=702):while True:x=[]y=[]for index,value in enumerate(data):image=cv2.imread(value)# 使用cv2缩放图片,由于图片是长方形,cv2.resize的参数是(宽,高)# 而后续的reshape的参数是(高,宽),所以是相反的image=cv2.resize(image,(60,200))x.append(image)lb=label[index]y_=np.zeros((n_classes,))=1.y.append(y_)# 当数据量等于一个批次是放回数据if len(x)==batch_size:x=np.array(x).reshape(-1,200,60,3)/255.y=np.array(y)# print(y.shape)yield x,yx=[]y=[]
#2 模型搭建
DarkNet
在本节中,我们使用的模型是DarkNet,事实上,DarkNet还是一个小众的深度学习框架,但是我们这里所说的DarkNet是一个名为DarkNet53的深度神经网络。它实际上是有名的yolov3目标检测宽框架的backbone。
完整的yolov3的网络结构如下,这里我们只取backbone的部分网络,也就是虚线中的部分作为我们的神经网络结构。
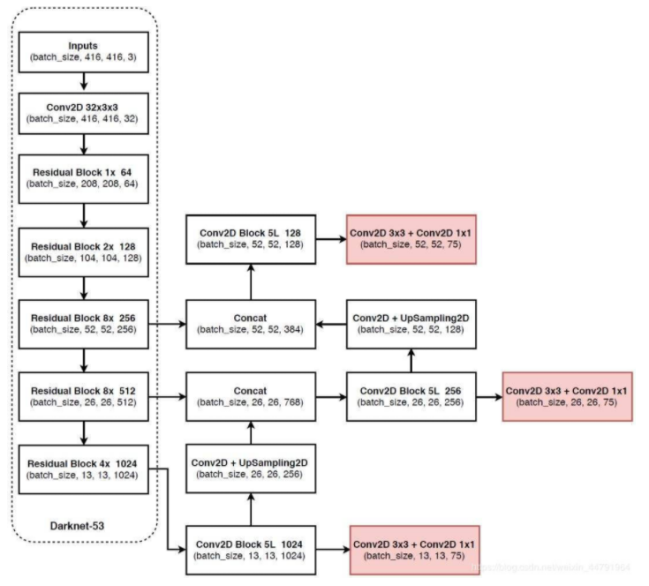
事实上,DarkNet53的网络结构和ResNet很相似,同样是拥有残差连接的结构,基础的卷积方式同样是Conv+BN+激活函数,只不过激活函数换成了LeakyReLu,并且残差的位置发生了改变。以下是DarkNet53的网络结构图,我们可以根据这一结构图编写我们的代码。
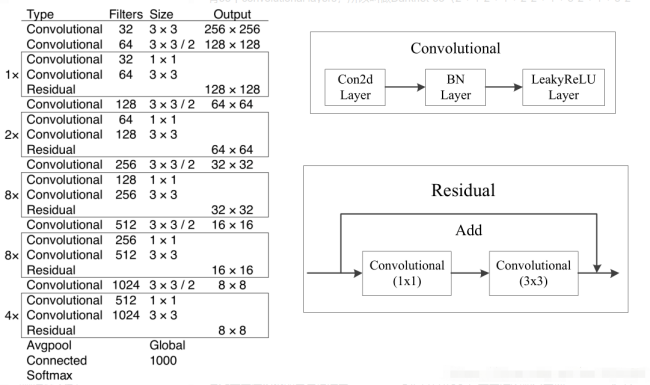
新建一个model.py文件,先导入依赖库,然后定义一个compose()函数:
from tensorflow.keras.layers import *from tensorflow.keras.regularizers import l2from functools import reduceimport tensorflow.keras as kfrom image_recognition.DarkNet.load_data import load_data,gan_datadef compose(*funcs):if funcs:return reduce(lambda f,g:lambda *a, **kw:g(f(*a,**kw)),funcs)else:raise ValueError('Composition of empty sequence not supported.')
这个函数的作用是对输入进来的一个数据集合或元组中的所有数据进行叠加操作,例如下面的代码中:
# 单个卷积def conv2D(filter,kernel_size,stride=2,l2_=True,bise=False):padding='valid' if stride==2 else 'same'return Conv2D(filters=filter,kernel_size=kernel_size,padding=padding,kernel_regularizer=l2(5e-4),strides=stride,use_bias=bise)# 卷积+标准化+激活def Conv2D_BN_Leaky(filter,kernel_size,stride=2,l2=True,bise=False):return compose(conv2D(filter,kernel_size,stride,l2,bise),BatchNormalization(),LeakyReLU(alpha=0.1))
Conv2D_BN_Leaky()函数中的代码一般情况下我们是这么写的,使用reduce的话,可以使用和keras类似的函数式的方式搭建网络。
def Conv2D_BN_Leaky(x,filter,kernel_size,stride=2,l2=True,bise=False):x=conv2D(x,filter,kernel_size,stride,l2,bise)x=BatchNormalization()(x)x=LeakyReLU(alpha=0.1)(x)return x
接着是 残差网络,DarkNet的残差结构并不是和ResNet相同,而是和DenseNet类似,下采样放到了残差连接的外面,但连接处又使用add操作区别于DenseNet的concatenate操作。
# 残差块def res_block(x,filters,num_res_blocks):x=ZeroPadding2D(((1,0),(1,0)))(x)# 下采样x=Conv2D_BN_Leaky(filters,kernel_size=3)(x)# 多个残差块for i in range(num_res_blocks):y=Conv2D_BN_Leaky(filters//2,kernel_size=1,stride=1)(x)y=Conv2D_BN_Leaky(filters,kernel_size=3,stride=1)(y)x=Add()([x,y])return x
接着,是主干网络的搭建,这一部分比较简单,直接写入模型结构中的参数,然后调用前面的函数即可,再这里我们进行了32倍下采样,再最后使用全局平均池化展平特征向量,并在最后连接一个输出层,是我们数据集的类别数。
def dreaknet53_output(inpt):# 200*60x=Conv2D_BN_Leaky(32,3,stride=1)(inpt)# 100*30x = res_block(x, 64, 1)# 50*15x = res_block(x,128 ,2)# 25*7x = res_block(x ,256, 8)# 12*3x = res_block(x ,512, 8)# 6*1x = res_block(x ,1024, 4)x=GlobalAveragePooling2D()(x)x=Dense(702,activation='softmax')(x)model=k.models.Model(inpt,x)return model
最后,在mian函数中创建模型结构,编译模型,加载数据,进行训练,这里我们使用了一个回调函数用来保存最优模型。
if __name__ == '__main__':model=dreaknet53_output(k.Input((200,60,3)))model.summary()#batch_size=4=load_data()m=k.callbacks.ModelCheckpoint('darknet_reid_{loss:.4f}.h5',monitor='loss',save_best_only=True)='categorical_crossentropy',optimizer=k.optimizers.Adam(lr=3e-5),metrics=['acc'])model.fit(gan_data(data,label,batch_size),steps_per_epoch=len(data)//batch_size,epochs=100,callbacks=[m])model.save('darknet_reid.h5')
#3 康康结果
Grain Rain
由于篇幅的原因,模型使用以及预测的代码将在下一篇中放出,先康康最终效果咯。点个关注能够第一时间收到更新哈!
