
基于转移学习的图像识别
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

01.前言
我们希望编写一个简单的算法用来识别狗狗的品种,假设我们想知道这只狗是什么品种。

算法该如何分辨这只狗可能属于哪个品种?当然小伙伴们可以训练自己的卷积神经网络来对这张图片进行分类,但是通常情况下我们既没有GPU的计算能力,也没有时间去训练自己的神经网络。但是,全世界的各个研究团队(例如牛津,谷歌,微软)都拥有足够的计算能力,时间和金钱,而且以前可能已经解决过一些类似的问题。我们该如何利用他们已经完成的工作呢?现在来让我们了解一个重要的概念——转移学习。
02.卷积神经网络
在此之前我们先简要介绍一下什么是卷积神经网络。

卷积神经网络(CNN)是一种用于图像分类的神经网络架构,通常包含卷积层和池化层两种类型。卷积层接受输入图像并将其抽象为简单的特征图,池化层则是为了降低特征图的维数。这两层的目的是简化寻找特征的过程,并减少过度拟合的数量。典型的CNN架构如下所示:
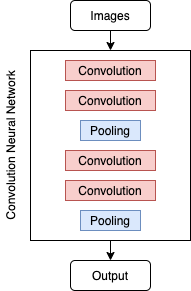
03.训练自己的CNN模型
如果我们要使用预训练的模型,那么知道什么是卷积层和池化层有什么意义呢?让我们先看看训练CNN需要做什么。
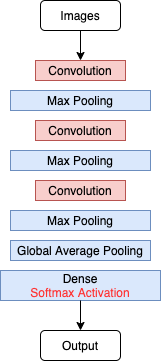
我们首先将添加了几个卷积层和池化层,并在最后加上了一个全连接层。选择softmax作为激活函数激活。我们希望该网络可以判断出图片中狗狗最有可能的品种,但不幸的是它只有5%的测试集准确度,可以说非常不准确了。此外,经过20次迭代后在验证集上的平均损失约为4.5,已经很高了。
04.使用转移学习逻辑
这就是为什么要使用转移学习,我们应该尽可能多地使用迁移学习,而不是构建自己的体系结构。转移学习实际上是采用预先训练的神经网络,对其进行定义,并将其用于自己的预测任务。
如果我们要构建一种预测狗的品种的算法一般会按照一下逻辑进行:所有图片、所有动物、所有的狗以及特定犬种进行。因此如果我们已经找到可以正确识别狗的模型,只需要在其之上添加一层来预测狗的品种就可以了,那我们该
怎么操作呢?
为了最大程度地利用转移学习,我们需要仔细考虑转移到模型中的“学习”。
从预先训练的模型中转移学习Keras是一个基于Python的深度学习库,已经为我们编译了多个训练好了的模型。在本练习中,我们将研究两种常见的预训练模型:VGG16和Resnet50。我们可以将这些经过预先训练的模型导入环境,然后在该模型之上添加一层对133个犬种进行分类。总结一下,我们需要做的包括:
1.选择一个有很多狗狗的数据库
2.找到预先训练过的模型对狗进行分类(例如VGG16和Resnet50)
3.添加我们自己的自定义图层以对狗的品种进行分类
用于转移学习的自定义层
我们将使用三种基本架构,以对预训练的模型进行微调。
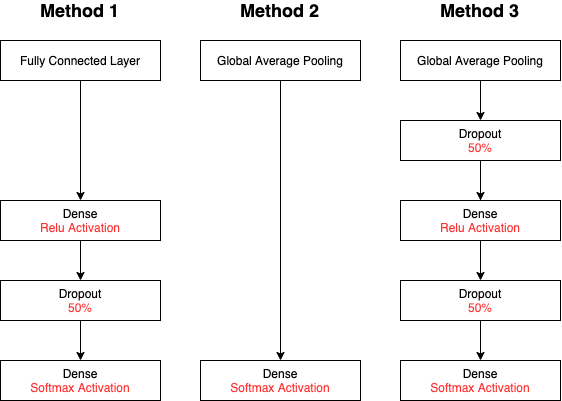
与所有这三种方法一样,我们以全连接层和softmax激活函数结束。保证我们能够预测133个犬种。
方法1:具有损失的完全连接的层
通过完全连接层,所有先前的节点(或感知)都连接到该层中的所有节点。这种类型的体系结构用于典型的神经网络体系结构(而不是CNN)。我们添加了额外的损失和密集层,以减少过度拟合。CNN首先使用卷积层的部分原因是为了避免这种过度拟合。
方法2:全局平均池层
全局平均池化层(GAP层)是一个池化层,通过它可以获取上一层中连接的所有节点的平均值。这是减少网络尺寸的标准CNN技术。
方法3:具有损失的全局平均池
在方法二之上,我们还希望添加退出层和密集层,以进一步减少过度拟合。
评估预训练模型和自定义层的性能
为此,让我们尝试VGG16和Resnet50预先训练的模型,并在顶部添加方法2的架构,看看会发生什么。我们将在每种CNN架构的测试集上报告损失函数和准确性。损失函数——预测与实际结果相差多远,预测值越大,模型拟合数据点的准确性越差。测试集的准确性——模型对测试集数据预测的准确性。
VGG16 + GAP
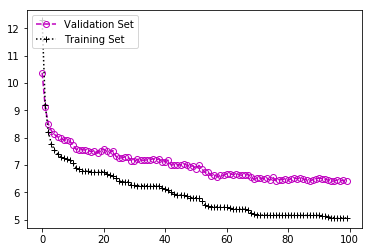
通过这种体系结构,我们发现测试集精度为55.0%,经过60次迭代后平均损失约为7。此架构比我们的训练模型准确得多,但损失也更高。损耗较高时,这意味着该模型体系结构的某些功能无法很好地捕获,即高偏差。
Resnet50 + GAP
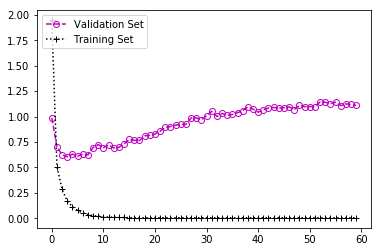
使用这种架构,我们发现测试集的准确度为81.9%,经过50次迭代后平均损失约为1.0。这是对VGG16 + GAP的重大改进。但是,训练和验证集损失之间的差距更大,这意味着该模型可能会更多地拟合数据,即高方差。我们之前提出了一个全连接层来进行测试。但是,看到所有模型的差异都很大。因此,让我们尝试进一步扩大尺寸,以减少过度拟合。
Resnet50 + GAP + Dropout
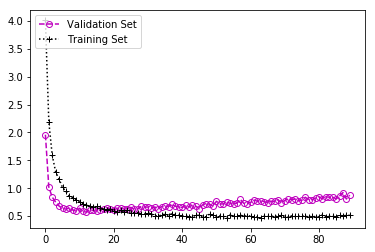
使用这种架构,我们发现测试集的准确度为81.7%,经过50次迭代后平均损失约为0.8。这与以前的体系结构大致相同。
回顾与展望
通过转移学习,我们在CNN架构上的准确度从5%提高到82%。最重要的是,我们花费了很少的时间来构建CNN架构,并且使用的GPU功能也很少。
使用预先训练的模型大大的节省我们的时间。在此过程中,改进了识别狗狗的分类模型。但是,该模型仍然有过拟合的趋势。
代码链接:https://github.com/kendricng/udacity-ds-capstone
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~