从头来看关系抽取



关系抽取是信息抽取的基本任务之一,在近些年来一直备受关注,其目的是识别文本中实体的目标关系。关系抽取对于知识库的构建以及文本的理解十分重要,特别有利于自然语言处理的一些任务,如问答,文本理解等,而且,关系抽取作为知识图谱构建的核心关键,是必不可少的步骤。
从去年开始关注这个任务以来,一直关注的都是近期的文章和方法,但是没有一个完整的脉络梳理,想要更好的了解关系抽取的近些年发展,打算从头开始审视一些关系抽取的论文,做到心中有数。因此,在看一些文章的过程中,也记录下来,分享给大家。
这篇文章主要是介绍了几篇关系抽取中和卷积神经网络(CNN)、循环神经网络(RNN)相关的顶会文章。
1、CNN-2014-COLING
论文题目:Relation Classification via Convolutional Deep Neural Network 论文地址:https://www.aclweb.org/anthology/C14-1220.pdf 这篇文章是最早的将深度神经网络模型应用于关系抽取任务上,并取得比传统特征工程效果好的工作之一,来自中科院自动化所赵军老师和刘康老师团队,获得COLING 2014年的最佳论文奖。
这一篇是关系抽取中一个比较经典的模型,该论文将关系抽取问题定义为:给定一个句子 和名词对 和 ,判断 和 在句子中的关系,将关系抽取问题等价为关系分类问题。模型的整体结构如图 左, 网络结构很简单,其实就是一个卷积神经网络(CNN),输入由 sentence level features 和 lexical level features 两部分特征构成。输出是该句子中包含的实体 和 之间的关系。
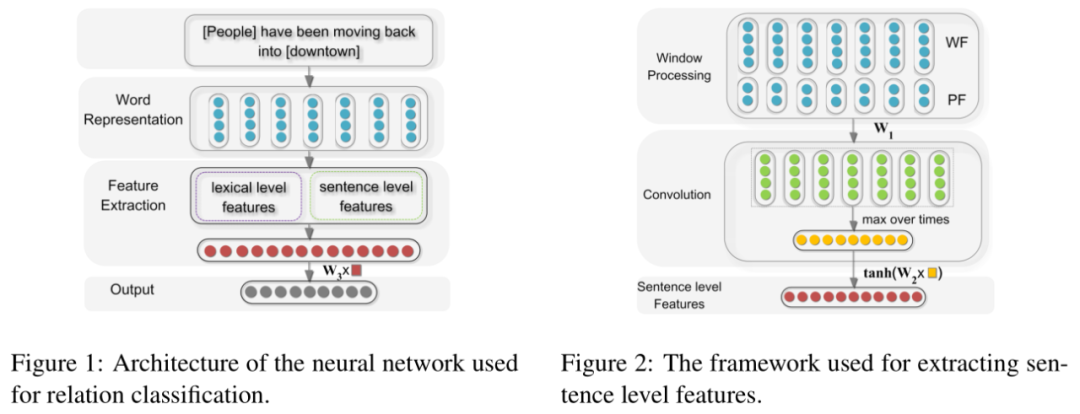
Lexical level features:即词汇级别特征,这部分的特征向量其实分为五部分;
L1:实体 本身的向量 L2:实体 本身的向量 L3:实体 左右两个词的向量 L4:实体 左右两个词的向量 L5:WordNet中两个实体的上位词
将几部分的词汇特征信息拼接作为词汇级别的特征信息,论文实验结果也表明,这部分信息对模型有很明显的效果。
Sentence level feature:句子级别特征的提取如上右图,采用卷积神经网络以及最大池化结合抽取句子级别的特征信息,输入特征是词向量信息(WF)以及位置向量信息(PF)的拼接结果。
Word Features:词向量这部分没有简单的使用这个词的embedding,而是采用滑动窗口的方式,取当前词的前后词拼接作为当前词的特征信息。 Position Features:考虑到 CNN 没有时序特征,所以特意增加了位置信息来弥补这一部分,每个词都距离两个实体有相对位置信息,将相对位置信息映射为向量表示。
2、CNN-2015-ACL
论文题目:Classifying Relations by Ranking with Convolutional Neural Networks 论文地址:https://www.aclweb.org/anthology/P15-1061.pdf
这篇文章也是基于CNN的网络模型,模型结构上面与第一篇文章类似,其中主要是在损失函数上面进行研究工作,模型的结构如下图所示:
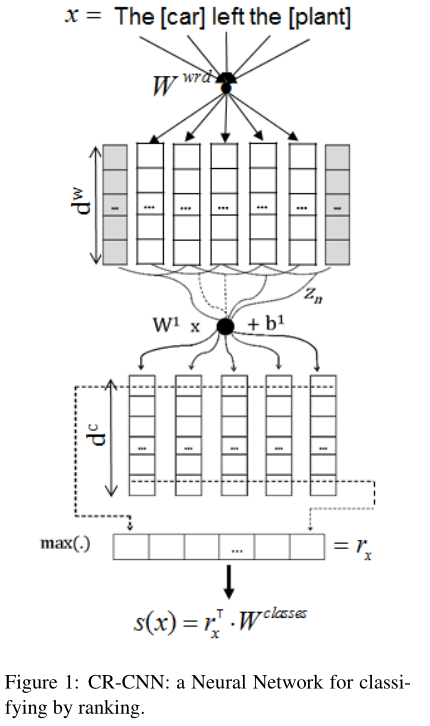
(1) 模型的输入特征包含词向量和词的位置向量,两者与第一篇文章获取方式相同,但没有词汇级别的特征。
(2) 句子向量获取是采用卷积神经网络 + 最大池化。
(3) 计算类别概率使用的不在是常用的softmax,而是采用下面的计算公式,其中 为经过池化层的句子向量,shape为[1, D], 代表的是关系类别向量矩阵,维度必须与池化层后的句子向量维度一致,跟随网络更新训练, 代表其中一个关系类别的向量,shape为[1,D],从而计算某一关系类别的概率。
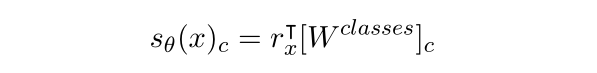
(4) 损失函数采用的是 pairwise ranking,公式如下, 和 为 margin 参数, 为缩放因子,有助于惩罚更多的预测错误。 为正确标签类别, 为错误标签类别(注:特意选取所有错误类别中得分最高的),训练目标是最小化损失 。
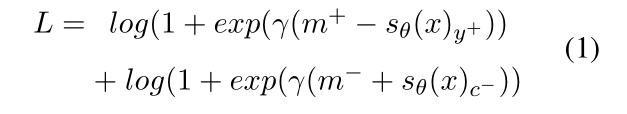
3、CNN-2015-NAACL
论文题目:Relation Extraction Perspective from Convolutional Neural Networks 论文地址:https://www.aclweb.org/anthology/W15-1506.pdf
这篇文章的基本结构也是基于卷积神经网络 + 最大池化层来做关系抽取任务,与之前采用卷积神经网络的最大不同之处在于使用的不在是单一的卷积核,而是采用 2014 年kim做情感分类时提出的模型结构,可以多个卷积核,不同宽度,更加多粒度获取句子信息,模型结构如下图:
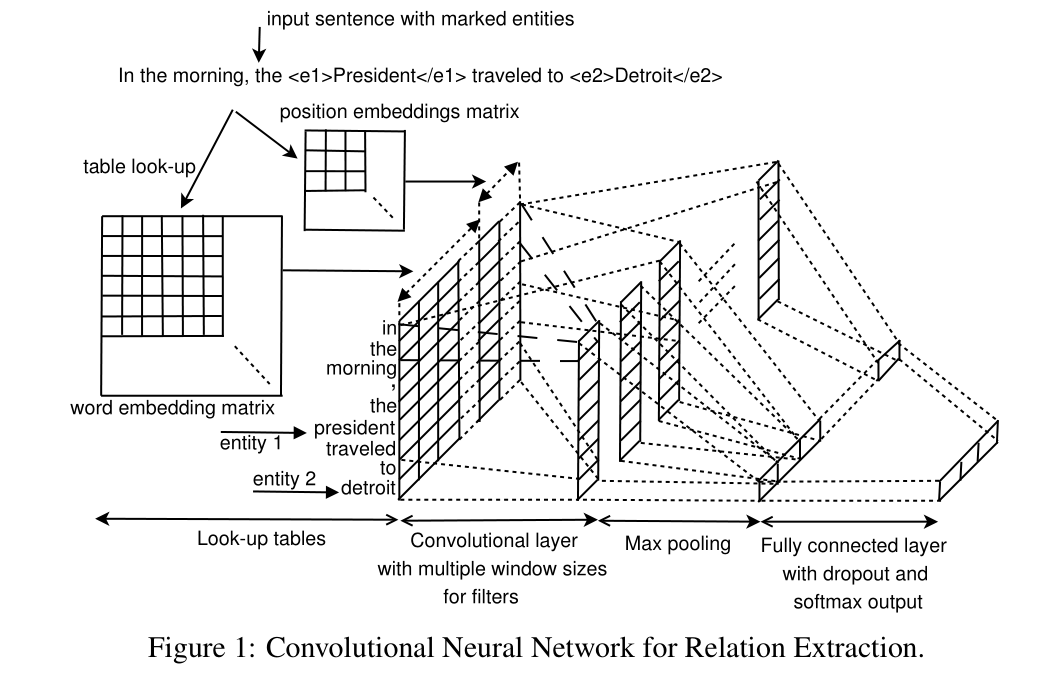
(1) 模型输入部分也是延续上述两个模型的方法,词向量和位置向量特征拼接,其中词向量采用的是预训练的方法,位置向量是当前词与两个实体的相对位置距离,映射为位置向量,与前面类似。
(2) 卷积神经网络部分采用的是多个卷积核,通过利用多个不同宽度的卷积核来抽取多粒度的特征。
(3) 最后也是最大池化 + softmax,其中还应用了dropout和l2正则化等策略。
4、CNN-2016-ACL
论文题目:Relation Classification via Multi-Level Attention CNNs 论文地址:http://people.iiis.tsinghua.edu.cn/~weblt/papers/relation-classification.pdf 这篇文章是出自清华大学刘知远老师的团队
这篇文章主要提出了卷积神经网络模型与注意力机制(Attention)结合的关系抽取方法,其中attention机制加了两层,一层是输入层的,一层是池化层的,模型网络结构如下图:
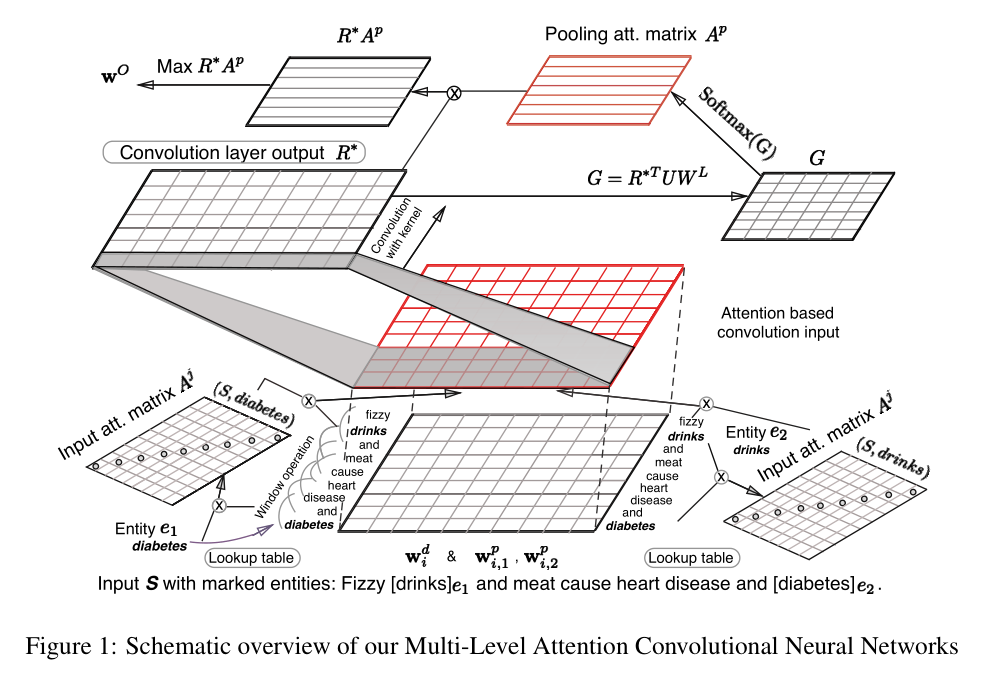
Input Representation:这里也是使用了词向量和位置向量拼接的方式,其中位置向量与上面模型一样,都是当前词到两个实体的相对距离转换为向量表示,为了获取更加更加丰富的信息,对拼接后的特征采用滑动窗口。
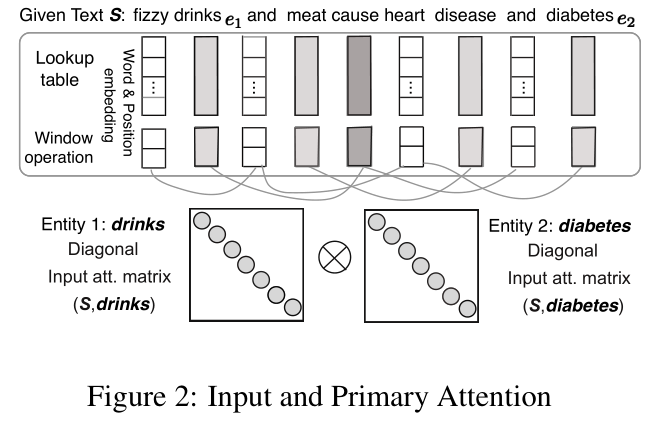
Input Attention Mechanism:这是文中的第一个attention层,主要目的是计算句子中的词语与实体之间的相关性权重,这部分的结构图如下图,如图中所示,建立了与实体对应的两个对角矩阵,对角矩阵中的各个元素是该位置的词语与实体的相关程度,具体是通过该词语实体之间的向量内积而来。对于两个对角矩阵有三种处理方式,分别是对应位置平均,拼接以及求对应位置向量之间的距离,结果乘上输入向量,作为输入层的输出,此处便考虑了实体对词的相关权重。
Secondary Attention:经过上面的处理之后,经过卷积神经网络,此后未经过常规的最大池化层,而是采用第二个注意力机制(attention-Based Pooling),作者认为利用这个方法能够获取有意义的n-gram信息,文中构建了一个相关性特征矩阵,其目的是捕捉卷积层的输出与实体关系矩阵之间的密切联系。将该相关性特征矩阵经过softmax转为混合层的注意力机制特征矩阵,并用该矩阵与卷积层的输出相乘,然后和常规的最大池化一样获取每一维度的最大值。
5、CNN-2016-COLING
论文题目:Attention-Based Convolutional Neural Network for Semantic Relation Extraction
论文地址:https://www.aclweb.org/anthology/C16-1238.pdf
这篇文章提出了一种基于注意力机制的卷积神经网络模型结构,该模型利用了词、词性和位置等信息,词级别的注意力机制能够更好地确定句子中对两个实体影响最大的部分,模型结构如下图。
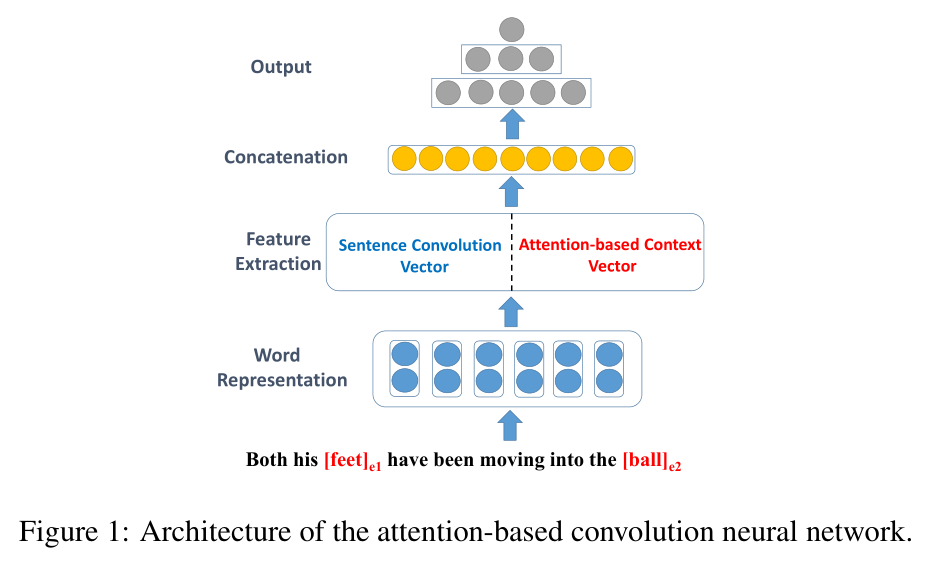
Sentence Convolution:这部分是通过卷积神经网络获取句子的特征向量,和上面几篇文章类似,输入特征包含预训练的词向量以及词相对实体的相对位置向量,初次之外,与之前不同的是加入了词的词性特征向量,三部分的特征向量拼接,作为模型的输入,之后经过卷积神经网络与最大池化层获取句子向量。
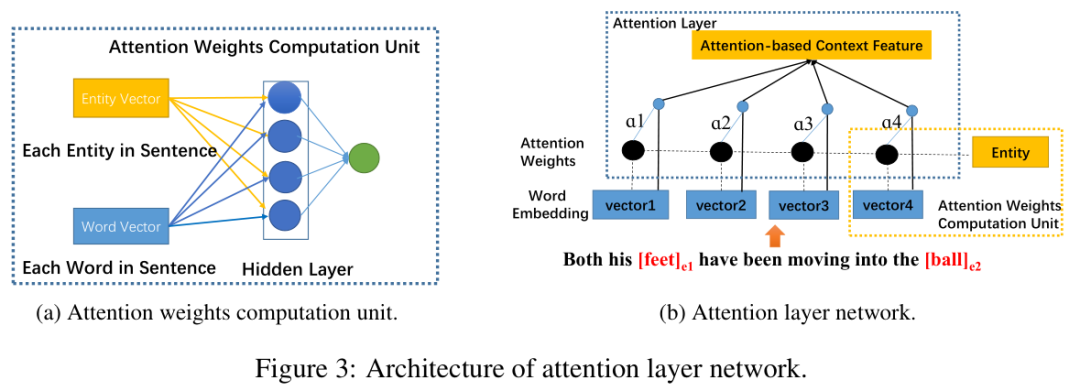
Attention-based Context Selection:第二部分是文章主要应用了注意力机制,目的是为了获取与句子中那部分对实体更加重要,这部分的模型结构如下图,主要思路是利用多层感知器网络层以及softmax计算句子中实体与每个词的相关程度,然后与正常的注意力机制一样,乘以每个词的向量表示,获取这部分的句子表示。
6、RNN-2015
论文题目:Relation Classification via Recurrent Neural Network
论文地址:https://arxiv.org/abs/1508.01006
这篇文章考虑到文本序列信息,采用RNN对文本建模,模型的整体结构也非常易懂,模型结构如下图所示。
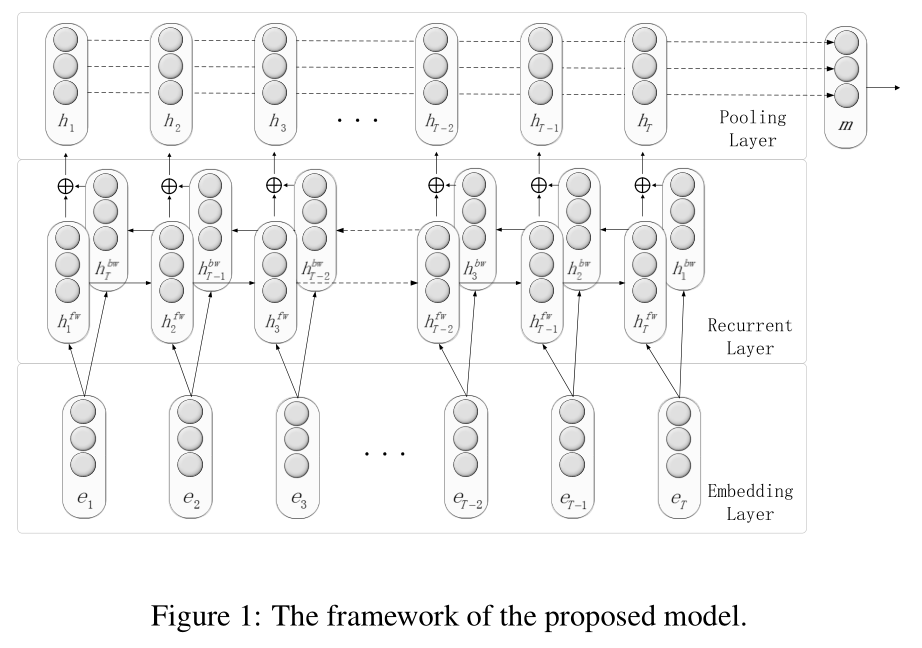
这篇文章的主要部分还是词嵌入层、RNN网络层、最大池化层,然后做关系类别的预测。这里面要注意的一点是RNN采用的是双向RNN网络,两个方向的信息不是拼接,而是相加。
另外,在我们之前看到的和CNN相关的一些方法中,都不约而同的选择加入位置向量信息,目的是刻画词与之间的距离信息,而在RNN网络中,句子的序列信息已经被编码在内,但是我们并不知道句子中的实体是哪部分,因此文中给出的方法是加入四个特殊token作为指示器(PI),分别是、、、,这四个特殊的token可以被看做单词,分别放在实体前后的位置,和文本一样经过RNN网络,用于标志实体的开始和结束。
7、RNN-2015-PACLIC
论文题目:Bidirectional Long Short-Term Memory Networks for Relation Classification 论文地址:https://www.aclweb.org/anthology/Y15-1009.pdf
这篇文章的主体网络是BiLSTM网络,但是读完paper之后,会明显感觉重心在特征构造上面,主要有以下两方面。
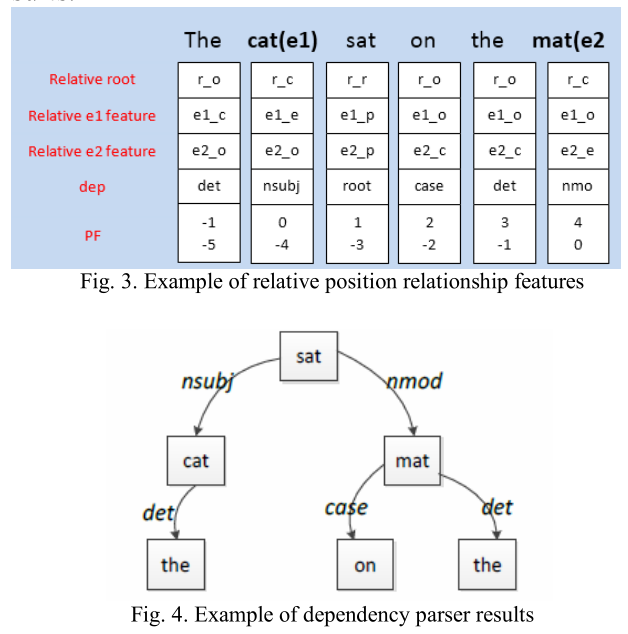
其一:输入特征构造,输入特征上面选择了6中词典特征,POS, NER, hypernyms, PF, dependency feature (Dep), relative-dependency feature(Relative-Dep),部分结构如下图,将这六种词典特征和当前词向量拼接作为输入特征。
其二:构造分类特征:以上输入特征拼接经过bilstm网络结构,然后分为又两部分特征,其中一部分主要其中在实体上面,将两个实体的输入特征和bilstm输出拼接作为这部分的特征,另外还有句子级特征,句子级别的特征也是采用bilstm之后的最大池化,但有所不同的是,根据两个实体的位置将句子分为ABC三部分,拼接max-pool(AB) 和 max-pool(BC),图形所示如下。
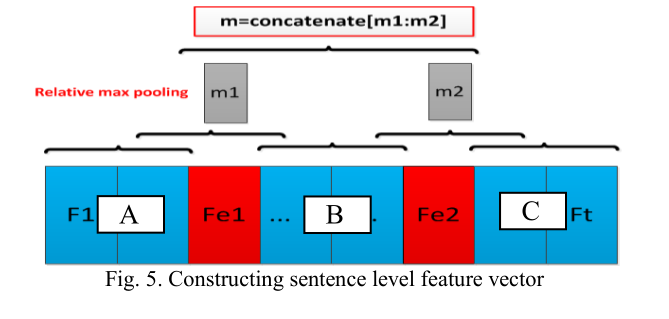
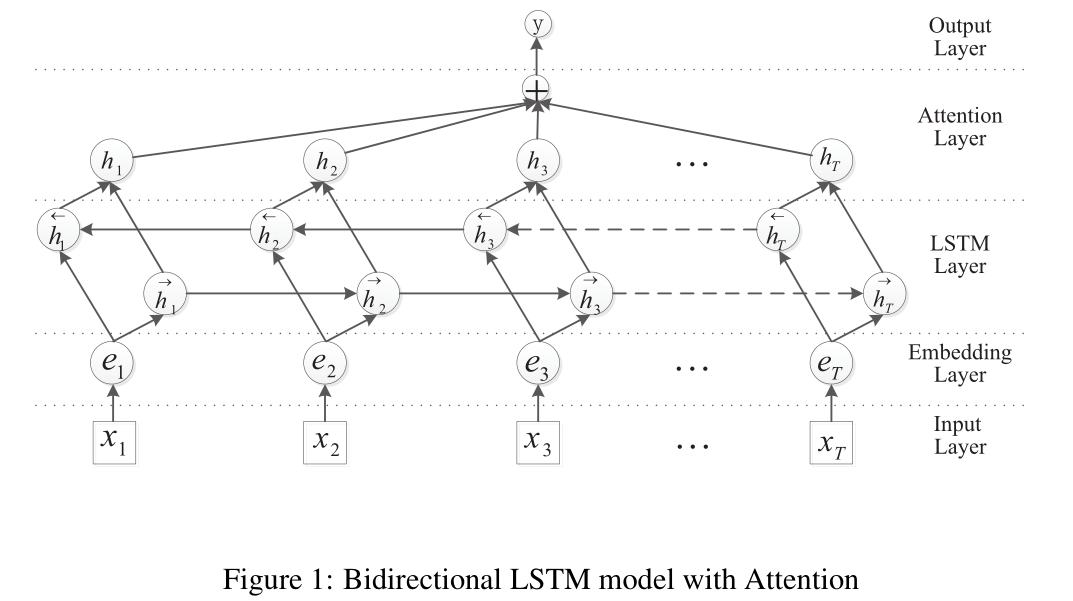
8、RNN-2016-ACL
论文题目:Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification 论文地址:https://www.aclweb.org/anthology/P16-2034.pdf
这篇文章的模型结构中规中矩,就是BiLSTM + Attention。
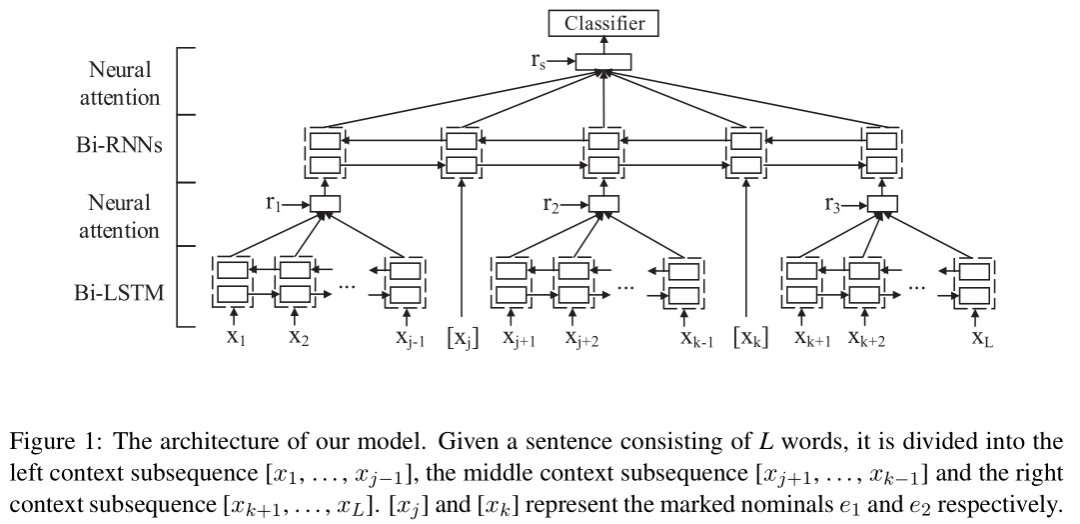
9、RNN-2016-COLING
论文题目:Semantic Relation Classification via Hierarchical Recurrent Neural Network with Attention 论文地址:https://www.aclweb.org/anthology/C16-1119.pdf
这篇文章采用了BiLSTM、BiRNN、Attention网络结构,采用分层的思想根据句子中两个实体的位置将句子分为五部分,分别是左边、实体1、中间、实体2、右边,因为左中右三部分的可能是由多个词组成,因此对这三部分采用BiLSTM + Attention获取这部分的特征,然后和两个实体拼接,得到五部分的特征,再经过BiRNN + Attention做关系分类,分层的思想体现在bilstm和RNN,模型的结构图如下图。
10、RNN-2016-ACL
论文题目:End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures 论文地址:https://www.aclweb.org/anthology/P16-1105.pdf
这篇文章应该是采用端到端的联合方法来做关系抽取的第一篇论文,文中虽然做法还是先做实体识别再做关系抽取的pipline的方式,但是其中两部分蕴含了参数共享,任务之间相互影响,下面是模型结构图:
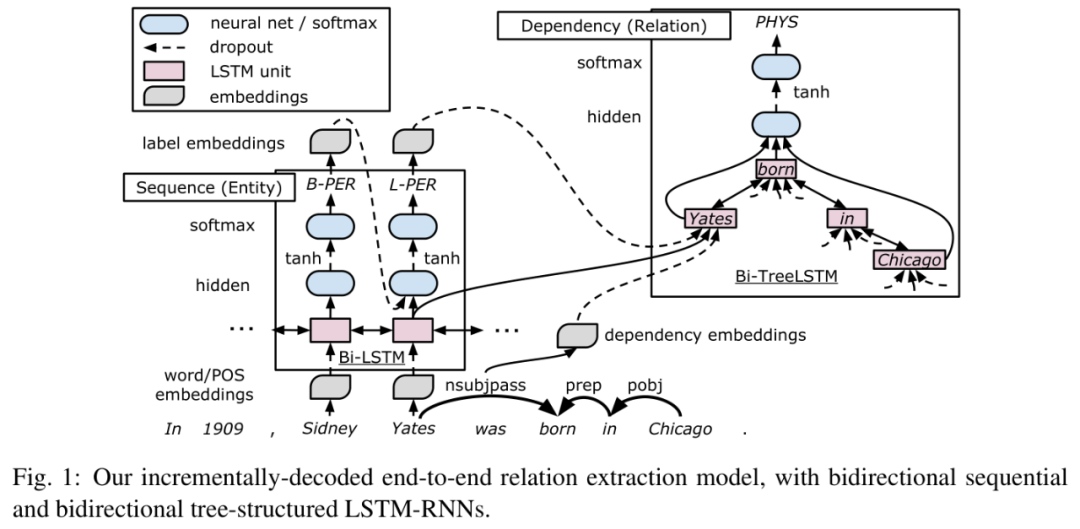
Embedding layer:有词向量、词性标签、依赖类型、实体标签,分别用 v(w), v(p), v(d), v(e)来表示。
Sequence layer:该层利用 embedding layer 的信息,获取文本的上下文信息和实体,主要是采用词向量和词性向量,经过BiLSTM网络层,识别每个单词的实体类别(标签体系采用了BILOU, Begin, Inside, Last, Outside, Unit), 采用一种贪婪的、从左到右的方式为单词分配实体标签,在解码过程中,使用一个单词的预测标签来预测下一个单 词的标签,从而考虑标签相关性。
Dependency Layer:根据依存关系,构建出关于两个实体的最短路径依存句法树。这一层用于捕捉依存树中实体对之间的关系,文中采用了双向树结构的LSTM-RNN来捕捉目标实体词对周围的依存结构信息,信息可以从根节点传到叶节点,也可从叶节点传到跟节点。文中主要是将树型LSTM叠加在序列LSTM上, 树型LSTM中每个节点都融入了三种特征,一个是依存类型、一个是序列双向LSTM的输出、还有一个是预测的标签向量。这也是文章的关键,看似仍然是pipeline的方式,但是由于部分参数是共享的,所以实体识别和关系抽取是互相影响的,但与真正的联合抽取还是有所不同的,因为还是先识别实体,然后得到实体对间的关系。
总结
以上是几篇关系抽取在过往几年和卷积神经网络或者循环神经网络相关的顶会论文,以现在的眼光来看,CNN部分围绕的主要工作还是基本的卷积神经网络、注意力机制以及在特征输入上面,特征上面在慢慢的去除人工构造特征,在逐步采用深度学习等方法自动获取特征信息。在RNN部分围绕的主要是RNN/LSTM/Attention、以及依存句法等特征。其中有很多观点和想法虽然现在看来并没有那么复杂,不过在当时神经网络模型、注意力机制等刚刚兴起的时候,能有这样的开山之作和新颖的想法是非常值得学习的。
参考资料
Relation Classification via Convolutional Deep Neural Network Classifying Relations by Ranking with Convolutional Neural Networks Relation Extraction Perspective from Convolutional Neural Networks Relation Classification via Multi-Level Attention CNNs Attention-Based Convolutional Neural Network for Semantic Relation Extraction Relation Classification via Recurrent Neural Network Bidirectional Long Short-Term Memory Networks for Relation Classification Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification Semantic Relation Classification via Hierarchical Recurrent Neural Network with Attention End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures https://github.com/roomylee/awesome-relation-extraction