
通道注意力新突破!从频域角度出发,浙大提出FcaNet:仅需修改一行代码,简洁又高效
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
本文介绍了一种非常巧妙的通道注意力机制,从频域角度分析,采用DCT对SE进行了扩展。所提方法简单有效仅需更改一行代码即可实现比SENet50提升1.8%的性能。

该文是浙江大学提出一种的新颖的通道注意力机制,它将通道注意力机制与DCT进行了巧妙的结合,并在常规的通道注意力机制上进行了扩展得到了本文所提出的多谱通道注意力机制:FcaLayer。作者在图像分类、目标检测以及实例分割等任务上验证了所提方案的有效性:在ImageNet分类任务上,相比SENet50,所提方法可以取得1.8%的性能提升。
从频域角度进行分析
注意力机制(尤其是通道注意力)在CV领域取得了极大的成功,然这些工作往往聚焦于如何设计有效的通道注意力机制同时采用GAP(全局均值池化)作为预处理方法。本文从另一个角度出发:从频域角度分析通道注意力机制。基于频域分析,作者得出:GAP是频域特征分解的一种特例。
基于前述分析,作者对通道注意力机制的预处理部分进行了扩展并提出了带多谱通道注意力的FcaNet,所提方法具有简单&有效性。在现有通道注意力机制的实现基础上,仅需更改一行code即可实现所提的注意力机制。
更进一步,在图像分类、目标检测以及实例分割任务上,相比其他注意力机制,所提方法取得了更好的性能。比如在ImageNet数据集上,所提方法比SE-ResNet50的Top1指标高1.8%,且两者具有相同的参数量与计算量。
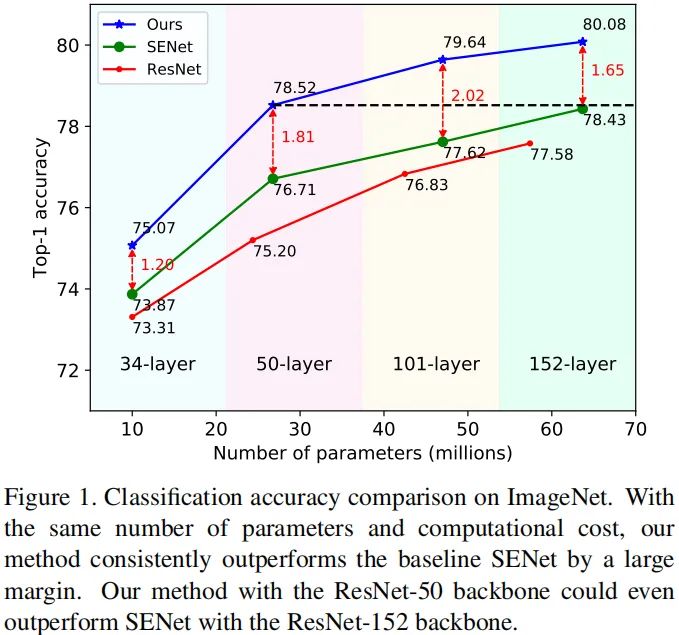
上图给出了所提方法与ResNet、SE-ResNet在ImageNet数据集上的指标对比。本文的主要贡献包含以下几点:
证实GAP是DCT的一种特例,基于该分析对通道注意力机制在频域进行了扩展并提出了带多谱通道注意力的FcaNet; 通过探索不同数量频域成分的有效性提出了一种“two-step”准则选择频域成分; 通过实验证实了所提方法的有效性,在ImageNet与COCO数据集上均取得了优于SENet的性能; 所提方法简洁有效,仅需在现有通道注意力机制的基础上修改一行code即可实现。
方法介绍
接下来,我们将重新研究一下通道注意力的架构以及DCT频域分析;基于前述分析推导多谱通道注意力网络;与此同时,提出一种“two-step”准则选择频域成分;最后给出了关于有效性、复杂度的讨论与code实现。
Revisiting Channels Attention and DCT
我们先来看一下通道注意力与DCT的定义,然后在总结对比一下两者的属性。
Channel Attention
通道注意力机制已被广泛应用到CNN网络架构中,它采用一个可学习的网络预测每个通道的重要。其定义如下:
Discrete Cosine Transform
DCT的定义如下:
其中表示DCT的频谱。2D-DCT的定义如下:
其中,表示2D-DCT频谱。对应的2D-IDCT的定义如下:
注:在上述两个公式中常数项被移除掉了。
基于上述通道注意力与DCT的定义,我们可以总结得到以下两点关键属性:(1) 现有的通道注意力方案采用GAP作为预处理;(2) DCT可以视作输入与其cosine部分的加权。GAP可以视作输入的最低频信息,而在通道注意力中仅仅采用GAP是不够充分的。基于此,作者引入了本文的多谱通道注意力方案。
Multi-Spectral Channel Attention
在正式引出多谱通道注意力之前,作者首先给出了一个定理,如下所示。其中表示D2-DCT的最低频成分。

上述定理意味着:通道注意力机制中可以引入其他频域成分。与此同时,作者也解释了为什么有必要引入其他频率成分。
为简单起见,我们采用B表示2D-DCT的基函数:
那么,2D-DCT可以重写成如下形式:
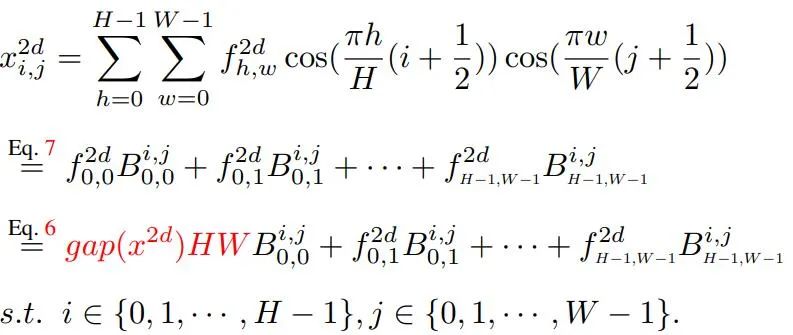
自然地,我们可以看到:图像/特征可以表示为不同频率成分的线性组合。再来看通道注意力的公式:,即通道注意力仅仅依赖于GAP结果。而X的信息却不仅仅由GAP构成:
从上述公式可以看到:仅有一小部分信息在通道注意力中得以应用,而其他频域成分则被忽略了。
Multi-Spectral Attention Module
基于上述分析,作者很自然的将GAP扩展为2D-DCT的更多频率成分的组合,即引入更多的信息解决通道注意力中的信息不充分问题。
首先,输入X沿通道维划分为多个部分;对于每个部分,计算其2D-DCT频率成分并作为通道注意力的预处理结果。此时有:
将上述频域成分通过concat进行组合,
真个多谱通道注意力机制与描述如下:
下图给出了通道注意力与多谱通道注意力之间的网络架构对比示意图。
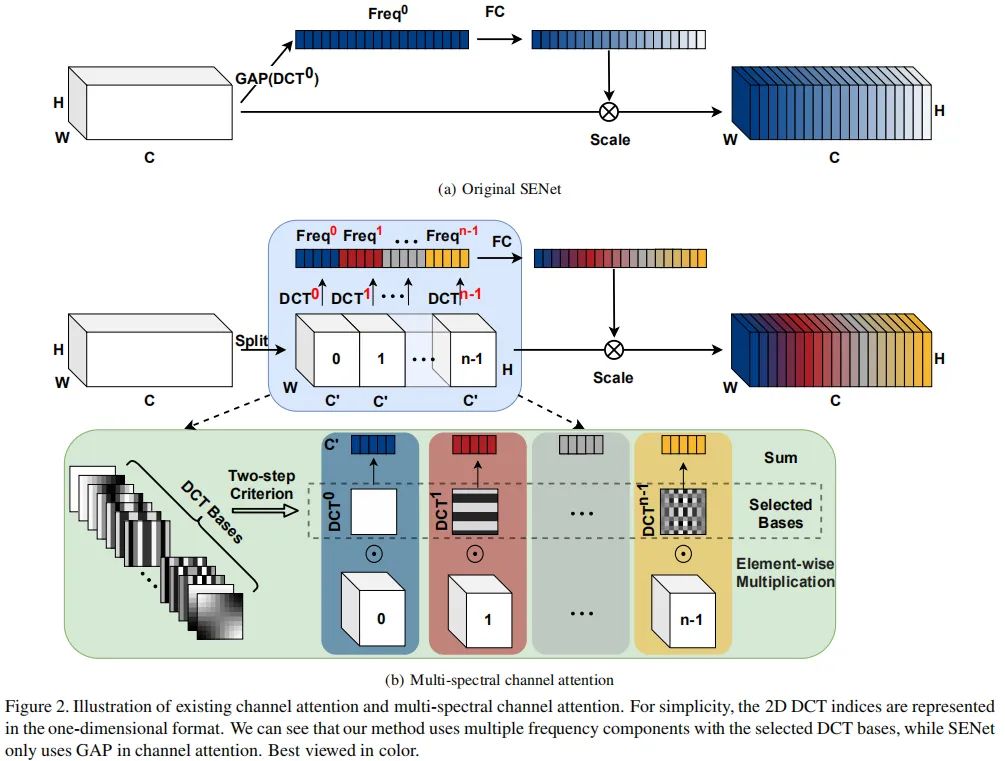
Criterion for choosing frequence components
从前述定义可以看到:2D-DCT有多个频率成分,那么如何选择合适的频率成分呢?作者提出一种“two-step”准则选择多谱注意力中的频率成分。
选择的主旨在于:首先确定每个频率成分的重要性,然后确定不同数量频率成分的影响性。首先,独立的确认每个通道的不同频率成分的结果,然后选择Top-k高性能频率成分。
最后,作者提供了本文所提多谱通道注意力的实现code,如下所示。可以看到:仅需在forward部分修改一行code即可。

实验
ImageNet
作者选用了四个广泛采用的CNN作为骨干网络,即ResNet34,ResNet50,ResNet101,ResNet152。采用了类似ResNet的数据增强与超参配置:输入分辨率为,SGD优化器,Batch=128,合计训练100epoch,cosine学习率。注:采用Apex混合精度训练工具。
COCO
作者选用了Faster RNN与Mask RCNN作为基准,并采用了MMDetection工具进行实现。SGD优化器,每个GPU的batch=2。训练12个epoch,学习率为0.01,在第8和11epoch时学习率衰减。
作者首先给出了不同频率成分下的通道注意力的性能对比,见下图。可以看到:(1) 多谱注意力以较大优势超越仅采用GAP的通道注意力;(2) 包含16个频率成分的注意力取得最佳性能。

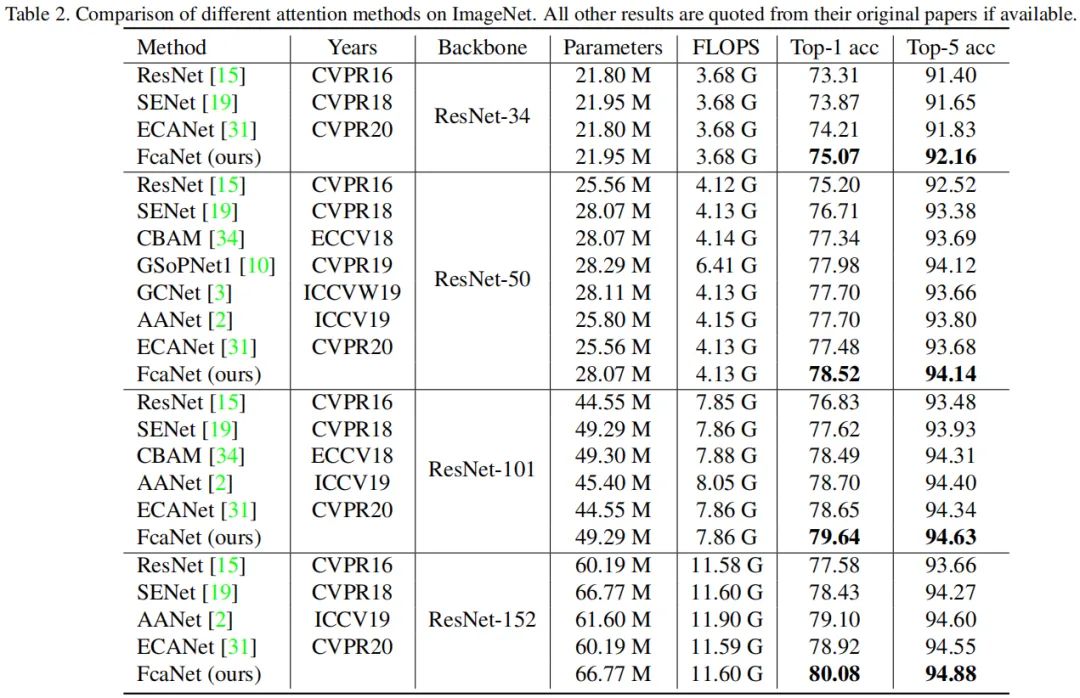
下表给出了所提方法在ImageNet数据集上与其他方法的性能对比。可以看到:所提方案FcaNet取得了最佳的性能。在相同参数&计算量下,所提方法以较大优化超过SENet,分别高出1.20%、1.81%、2.02%、1.65%;与此同时,FcaNet取得了超过GSoPNet的性能,而GSopNet的计算量比FcaNet更高。
下图给出了COCO目标检测任务上的性能对比,可以看到:所提方法取得了更佳的性能。FcaNet以较大的性能优势超过了SENet;相比ECANet,FcaNet仍能以0.9-1.3%指标胜出。

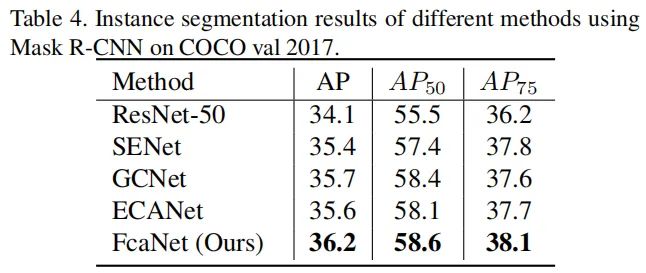
下图给出了COCO实例分割任务上的性能对比,可以看到:所提方法以较大优势胜出。比如,FcaNet以0.5%AMP指标优于GCNet。
全文到此结束,更多消融实验分析建议查看原文。最后附上多谱通道注意力code。注:get_dct_weights仅用于初始化dct权值,而不会参与训练和测试。很明显,这里的多谱通道注意力是一种与特征宽高相关的通道注意力机制,这有可能导致其在尺寸可变任务(比如图像复原中的训练数据-测试数据的尺寸不一致)上的不适用性。
import mathimport torchimport torch.nn as nndef get_ld_dct(i, freq, L):result = math.cos(math.pi * freq * (i + 0.5) / L)if freq == 0:return resultelse:return result * math.sqrt(2)def get_dct_weights(width, height, channel, fidx_u, fidx_v):dct_weights = torch.zeros(1, channel, width, height)# split channel for multi-spectral attentionc_part = channel // len(fidx_u)for i, (u_x, v_y) in enumerate(zip(fidx_u, fidx_v)):for t_x in range(width):for t_y in range(height):val = get_ld_dct(t_x, u_x, width) * get_ld_dct(t_y, v_y, height)dct_weights[:, i * c_part: (i+1) * c_part, t_x, t_y] = valreturn dct_weightsclass FcaLayer(nn.Module):def __init__(self, channels, reduction=16):super(FcaLayer, self).__init__()self.register_buffer("precomputed_dct_weights", get_dct_weights(...))self.fc = nn.Sequential(nn.Linear(channels, channels//reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channels//reduction, channels, bias=False),nn.Sigmoid())def forward(self, x):n,c,_,_ = x.size()y = torch.sum(x * self.pre_computed_dct_weights, dim=[2,3])y = self.fc(y).view(n,c,1,1)return x * y.expand_as(x)
传递门
论文链接:
https://arxiv.org/abs/2012.11879
网盘下载链接:
链接:https://pan.baidu.com/s/1JsWYvvRJ11lmM0yjrPfqRQ
密码:l01x
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载3 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得不错就点亮在看吧
