
如何从频域的角度解释CNN(卷积神经网络)?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者丨若羽
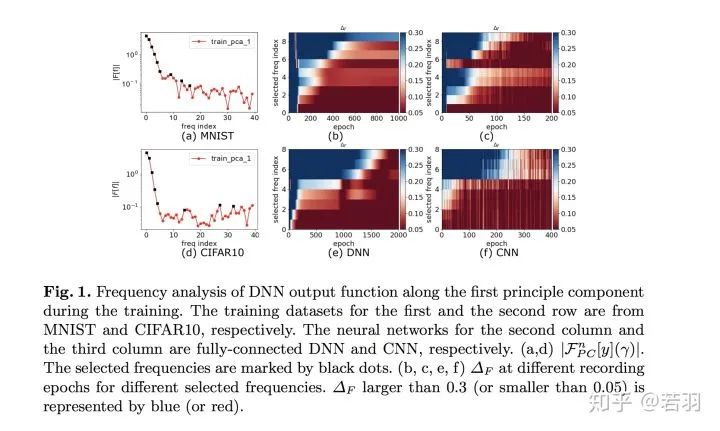
其次,与统计物理类似,LFP 模型只与网络参数的一些宏观统计量有关,而与单个参数的具体行为无关。这种统计刻画可以帮助我们准确理解在参数极多的情况下 DNN 的学习过程,从而解释 DNN 在参数远多于训练样本数时较好的泛化能力。
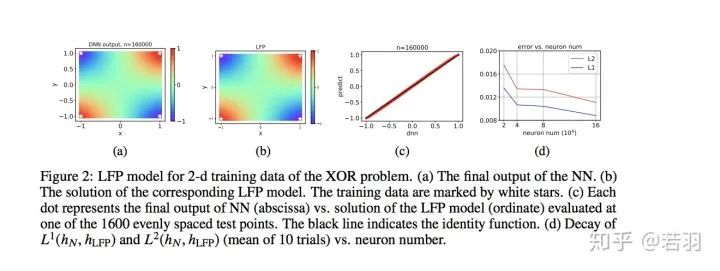
在该工作中,我们通过一个等价的优化问题来分析该 LFP 动力学的演化结果,并且给出了网络泛化误差的一个先验估计。我们发现网络的泛化误差能够被目标函数f本身的一种 F-principle 范数(定义为
 ,γ(ξ) 是一个随频率衰减的权重函数)所控制。
,γ(ξ) 是一个随频率衰减的权重函数)所控制。值得注意的是, 我们的误差估计针对神经网络本身的学习过程,并不需要在损失函数中添加额外的正则项。关于该误差估计我们将在之后的介绍文章中作进一步说明。


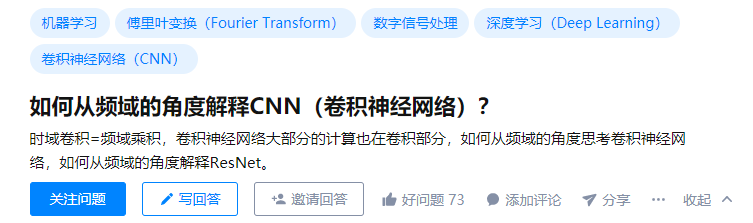
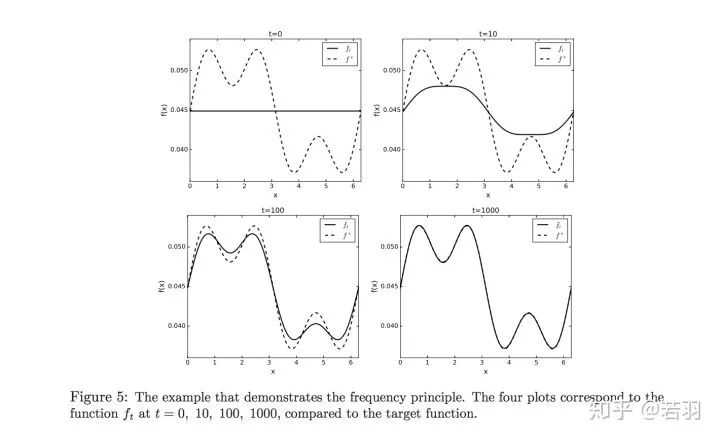
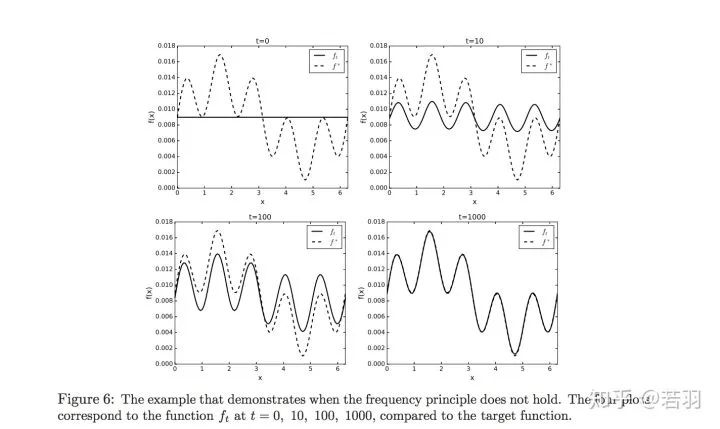
对函数做实验: 
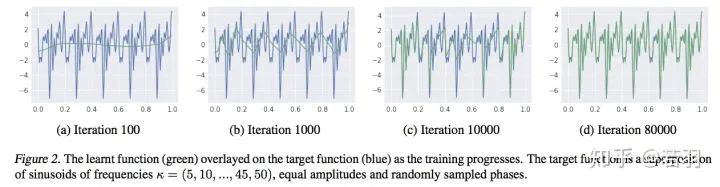
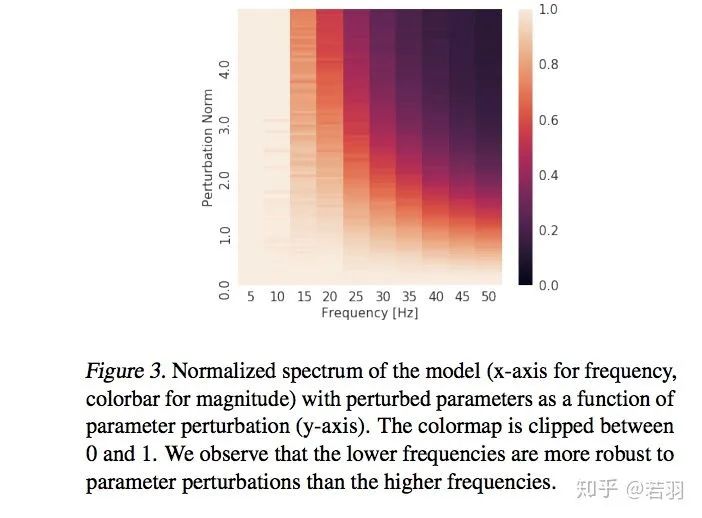
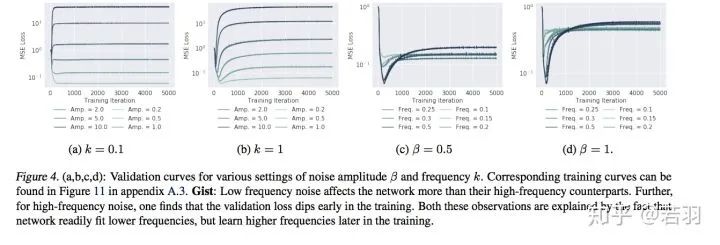
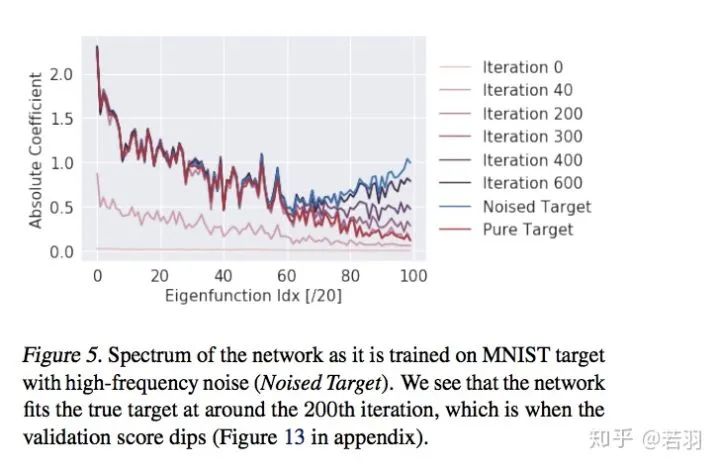


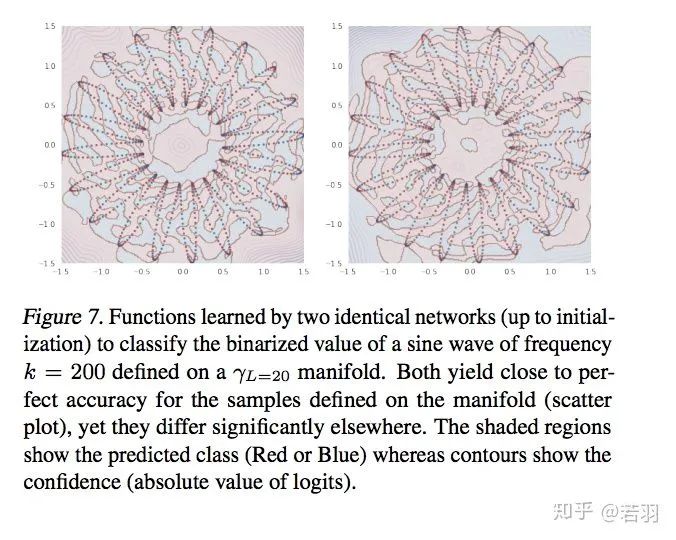
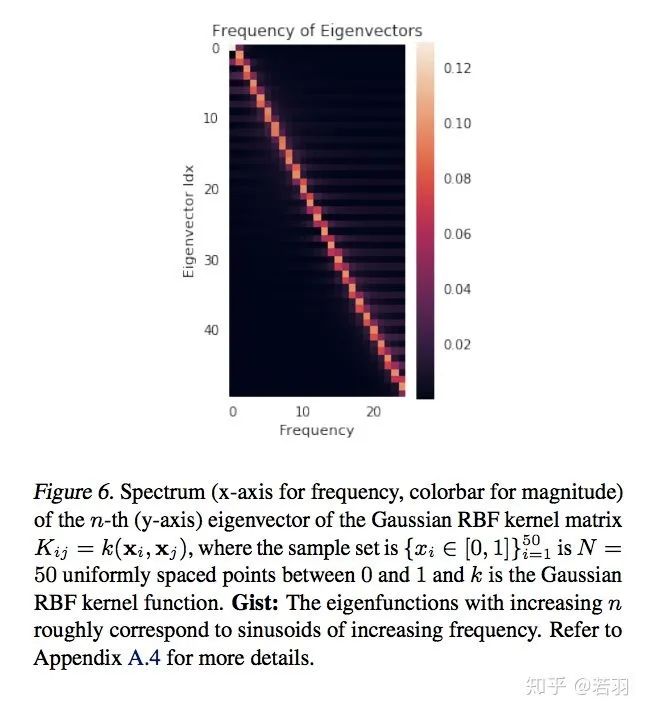
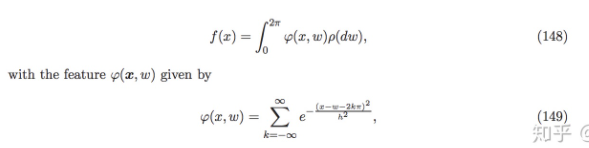
 概率测度
概率测度






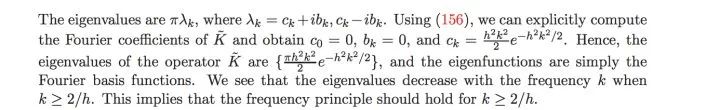
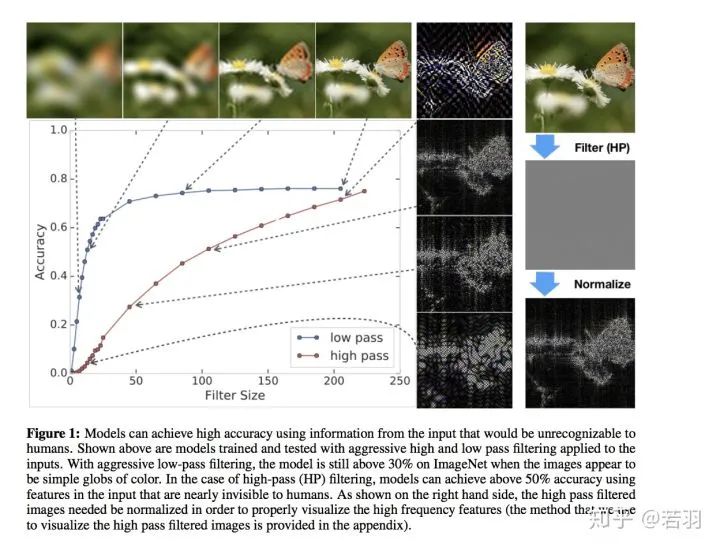
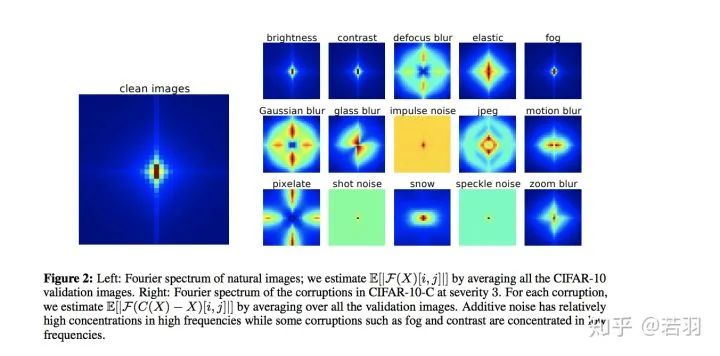
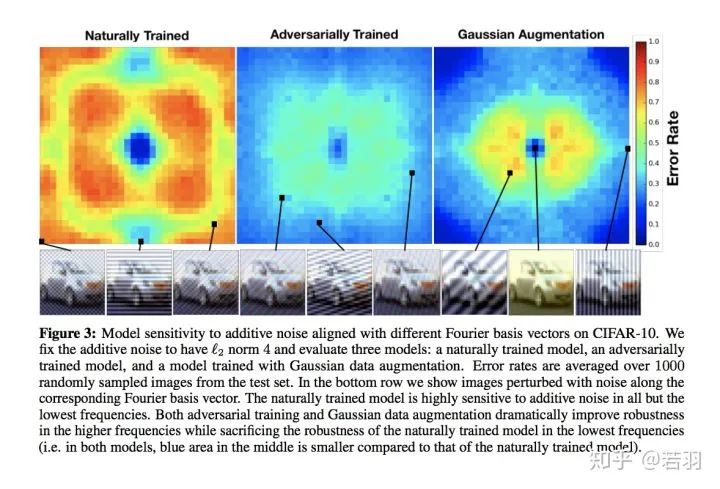
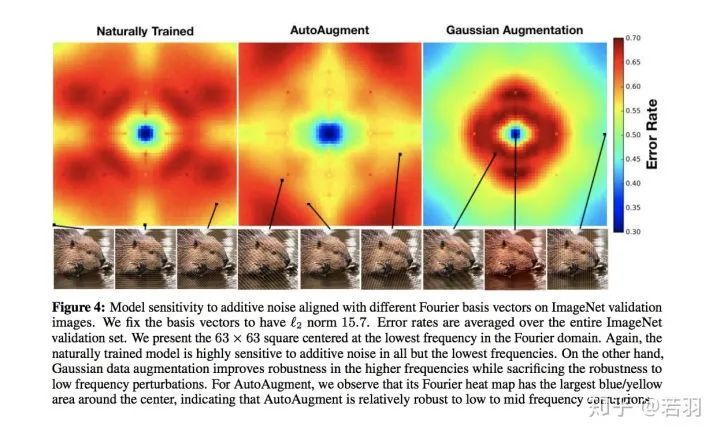
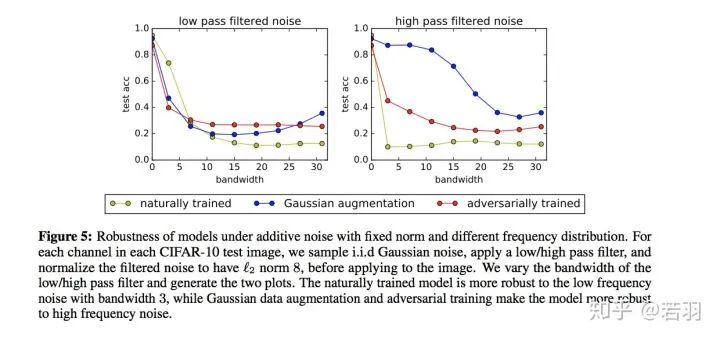
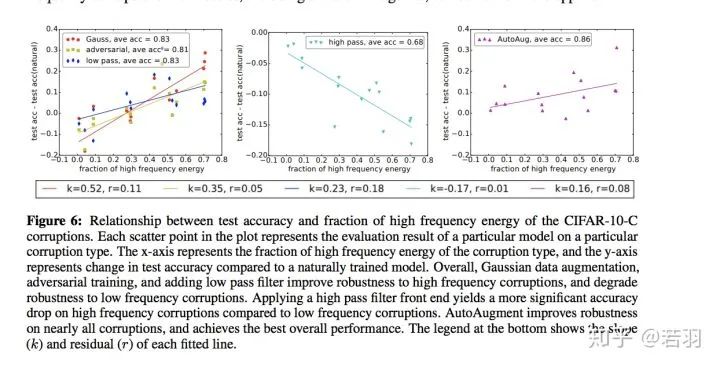
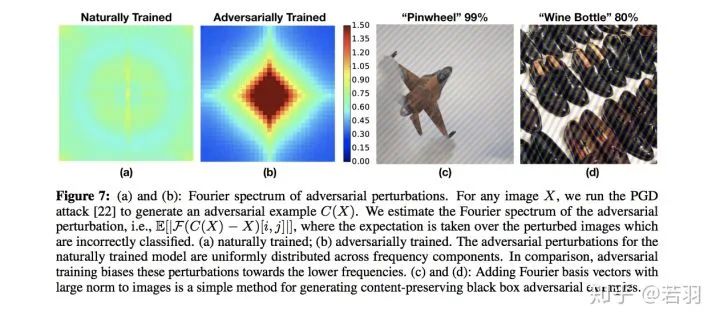
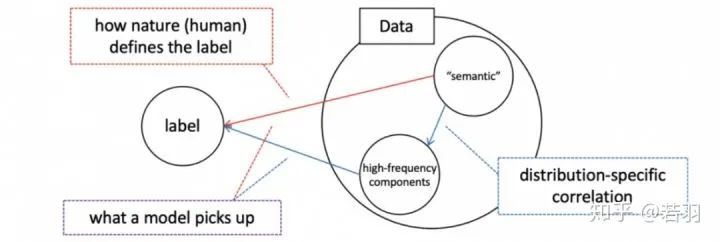

对于一个训练好的模型,我们调整其权重,使卷积核变得更加平滑;
直接在训练好的卷积核上将高频信息过滤掉;
在训练卷积神经网络的过程中增加正则化,使得相邻位置的权重更加接近。
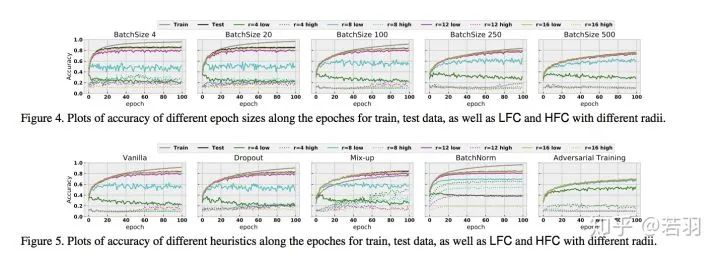
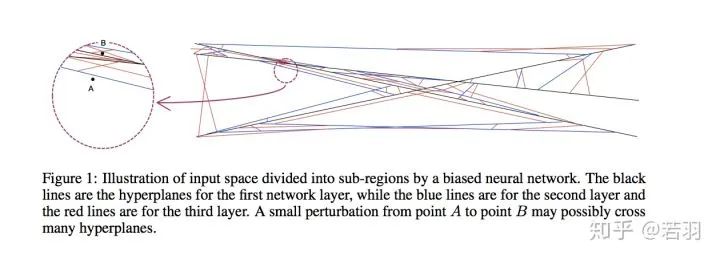


作者丨心似风往
评论