
通道注意力新突破!从频域角度出发,浙大提出FcaNet:仅需修改一行代码,简洁又高效
新智元推荐
新智元推荐
来源:极市平台
作者:Happy
【新智元导读】本文介绍了一种非常巧妙的通道注意力机制,从频域角度分析,采用DCT对SE进行了扩展,所提方法简单有效仅需更改一行代码即可实现比SENet50提升1.8%的性能。

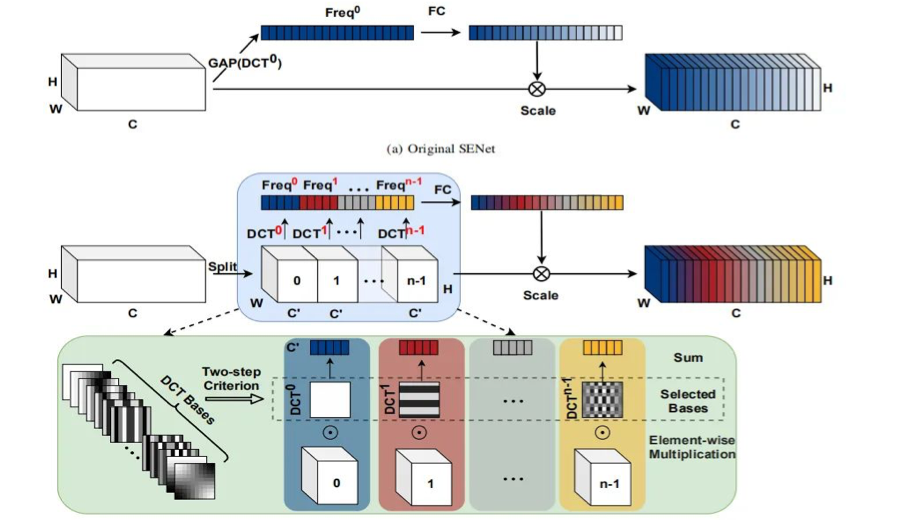
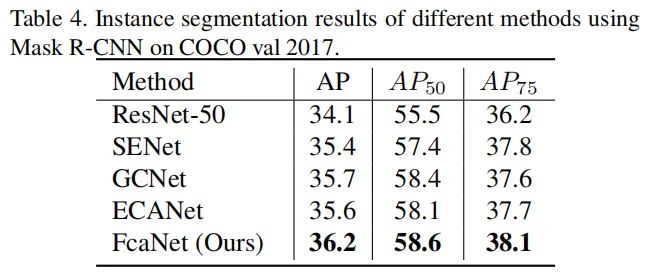
该文是浙江大学提出一种的新颖的通道注意力机制,它将通道注意力机制与DCT进行了巧妙的结合,并在常规的通道注意力机制上进行了扩展得到了本文所提出的多谱通道注意力机制:FcaLayer。作者在图像分类、目标检测以及实例分割等任务上验证了所提方案的有效性:在ImageNet分类任务上,相比SENet50,所提方法可以取得1.8%的性能提升。
从频域角度进行分析
基于频域分析,作者得出:GAP是频域特征分解的一种特例。

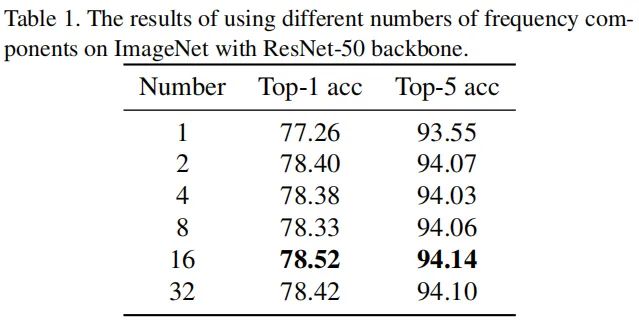
证实GAP是DCT的一种特例,基于该分析对通道注意力机制在频域进行了扩展并提出了带多谱通道注意力的FcaNet; 通过探索不同数量频域成分的有效性提出了一种“two-step”准则选择频域成分; 通过实验证实了所提方法的有效性,在ImageNet与COCO数据集上均取得了优于SENet的性能; 所提方法简洁有效,仅需在现有通道注意力机制的基础上修改一行code即可实现。
方法介绍
Revisiting Channels Attention and DCT
Discrete Cosine Transform
DCT的定义如下:
其中,表示2D-DCT频谱。对应的2D-IDCT的定义如下:
Multi-Spectral Channel Attention

为简单起见,我们采用B表示2D-DCT的基函数:



实验
COCO


import mathimport torchimport torch.nn as nndef get_ld_dct(i, freq, L):result = math.cos(math.pi * freq * (i + 0.5) / L)if freq == 0:return resultelse:return result * math.sqrt(2)def get_dct_weights(width, height, channel, fidx_u, fidx_v):dct_weights = torch.zeros(1, channel, width, height)# split channel for multi-spectral attentionc_part = channel // len(fidx_u)for i, (u_x, v_y) in enumerate(zip(fidx_u, fidx_v)):for t_x in range(width):for t_y in range(height):val = get_ld_dct(t_x, u_x, width) * get_ld_dct(t_y, v_y, height)dct_weights[:, i * c_part: (i+1) * c_part, t_x, t_y] = valreturn dct_weightsclass FcaLayer(nn.Module):def __init__(self, channels, reduction=16):super(FcaLayer, self).__init__()self.register_buffer("precomputed_dct_weights", get_dct_weights(...))self.fc = nn.Sequential(nn.Linear(channels, channels//reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channels//reduction, channels, bias=False),nn.Sigmoid())def forward(self, x):n,c,_,_ = x.size()y = torch.sum(x * self.pre_computed_dct_weights, dim=[2,3])y = self.fc(y).view(n,c,1,1)return x * y.expand_as(
论文链接:
https://arxiv.org/abs/2012.11879


评论