
ChatGPT数据集之谜

半个月以来,ChatGPT这把火越烧越旺。国内很多大厂相继声称要做中文版ChatGPT,还公布了上线时间表,不少科技圈已功成名就的大佬也按捺不住,携巨资下场,要创建“中国版OpenAI“。
不过,看看过去半个月在群众眼里稍显窘迫的Meta的Galactica,以及Google紧急发布的Bard,就知道在短期内打造一个比肩甚至超越ChatGPT效果的模型没那么简单。
让很多人不免感到诧异的是,ChatGPT的核心算法Transformer最初是由Google提出的,并且在大模型技术上的积累可以说不弱于OpenAI,当然他们也不缺算力和数据,但为什么依然会被ChatGPT打的措手不及?
Meta首席AI科学家Yann LeCun最近抨击ChatGPT的名言实际上解释了背后的门道。他说,ChatGPT“只是巧妙的组合而已”,这句话恰恰道出了一种无形的技术壁垒。
简单来说,即使其他团队的算法、数据、算力都准备的与OpenAI相差无几,但就是没想到以一种精巧的方式把这些元素组装起来,没有OpenAI,全行业不知道还需要去趟多少坑。
即使OpenAI给出了算法上的一条路径,后来者想复现ChatGPT,算力、工程、数据,每一个要素都需要非常深的积累。七龙珠之中,算力是自由流通的商品,花钱可以买到,工程上有OneFlow这样的开源项目和团队,因此,对互联网大厂之外的团队来说,剩下最大的挑战在于高质量训练数据集。
至今,OpenAI并没有公开训练ChatGPT的相关数据集来源和具体细节,一定程度上也暂时卡了追赶者的脖子,更何况,业界公认中文互联网数据质量堪忧。
好在,互联网上总有热心的牛人分析技术的细枝末节,从杂乱的资料中串联起蛛丝马迹,从而归纳出非常有价值的信息。
此前,OneFlow发布了《ChatGPT背后的经济账》,其作者从经济学视角推导了训练大型语言模型的成本。本文作者则整理分析了2018年到2022年初从GPT-1到Gopher的相关大型语言模型的所有数据集相关信息,希望帮助有志于开发“类ChatGPT”模型的团队少走一步弯路。
1 概述
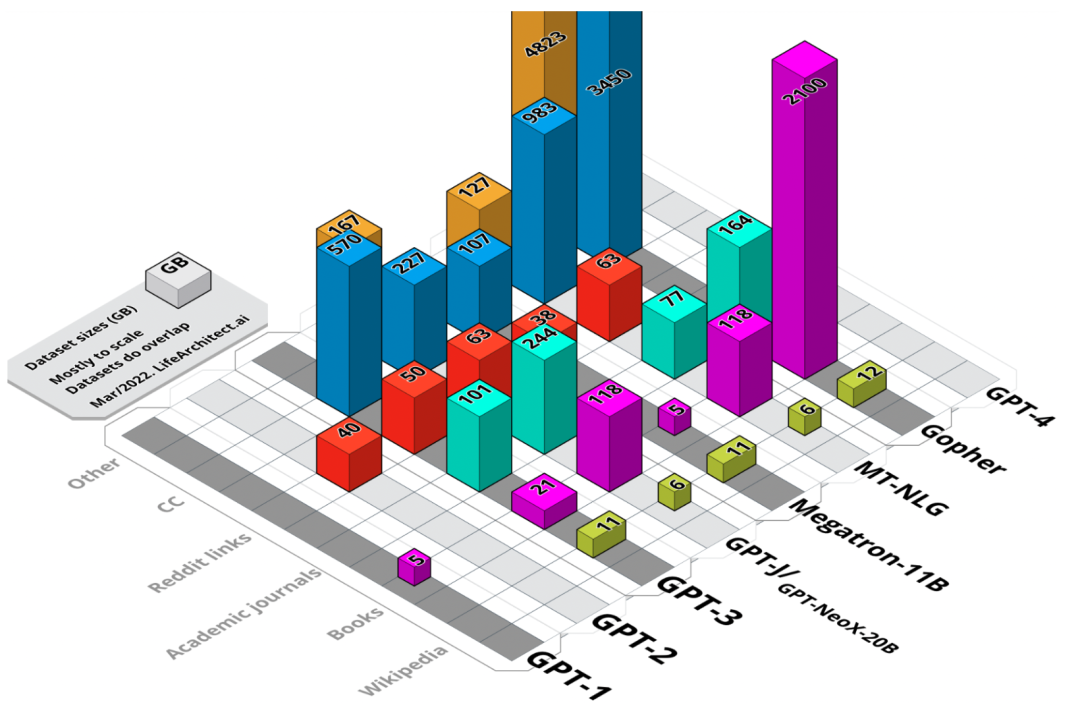
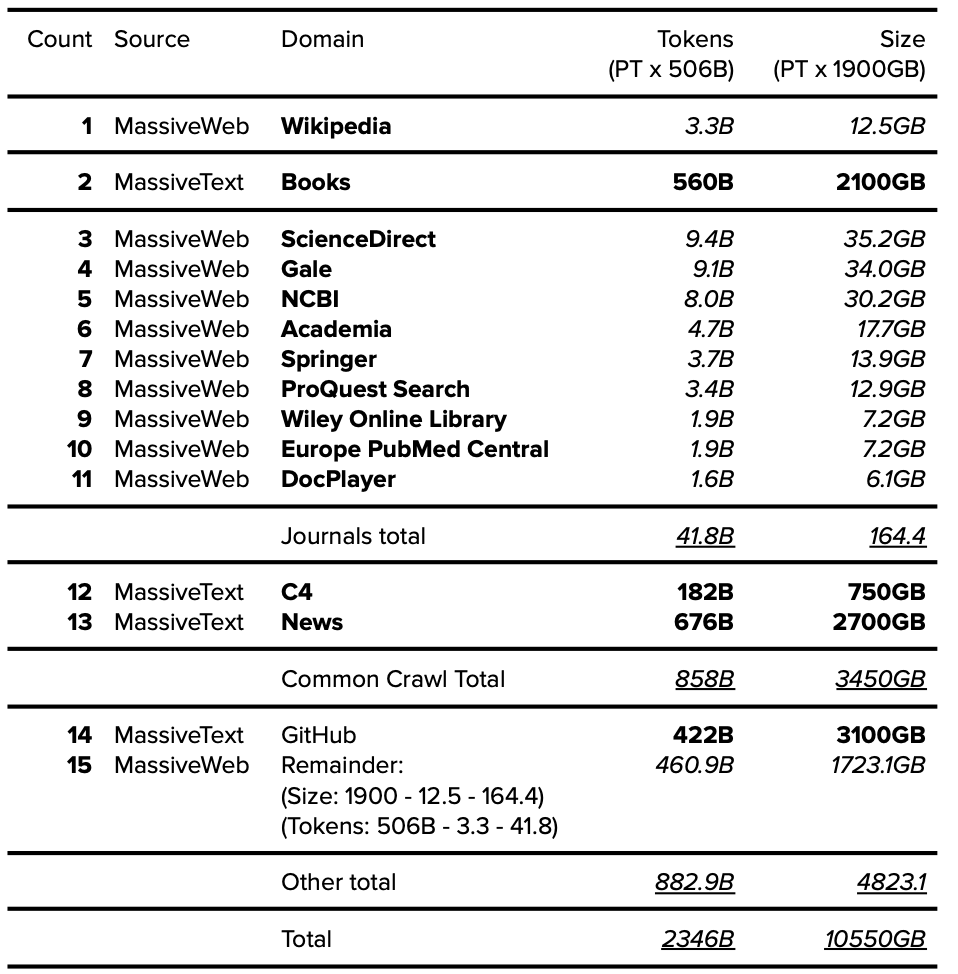
1.5. Common Crawl
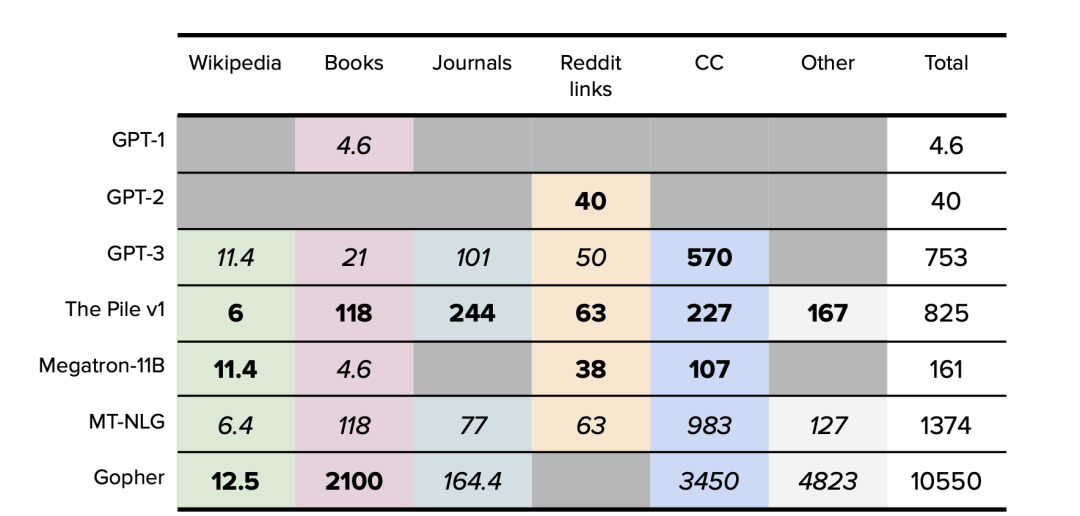
2
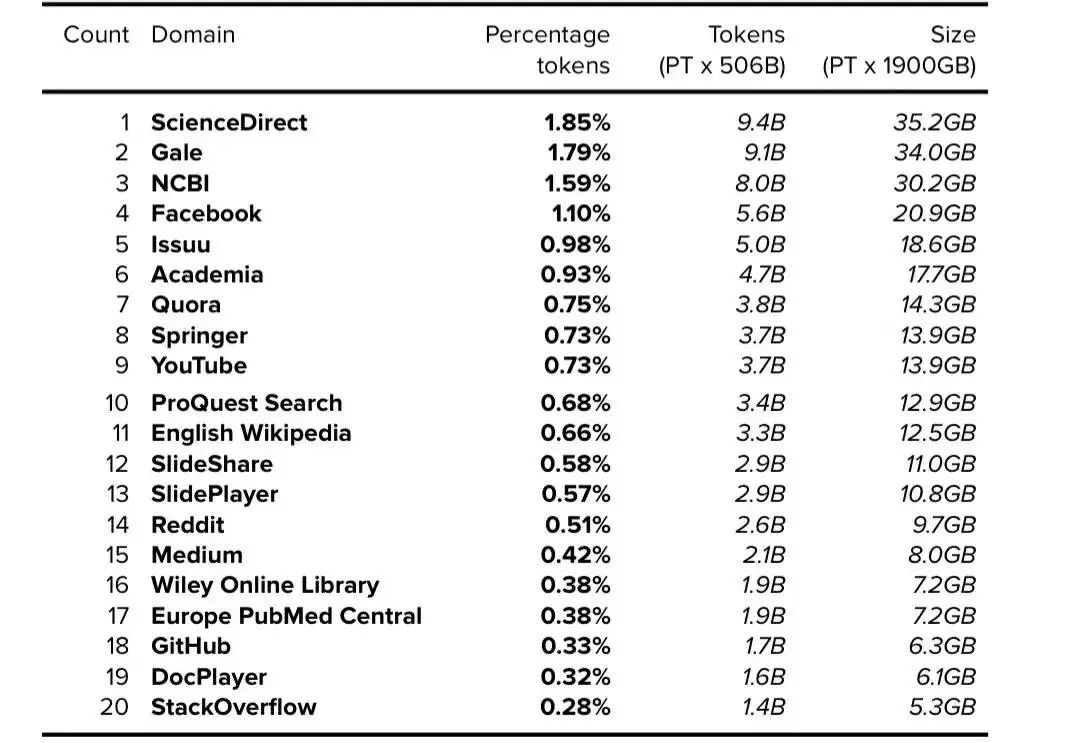
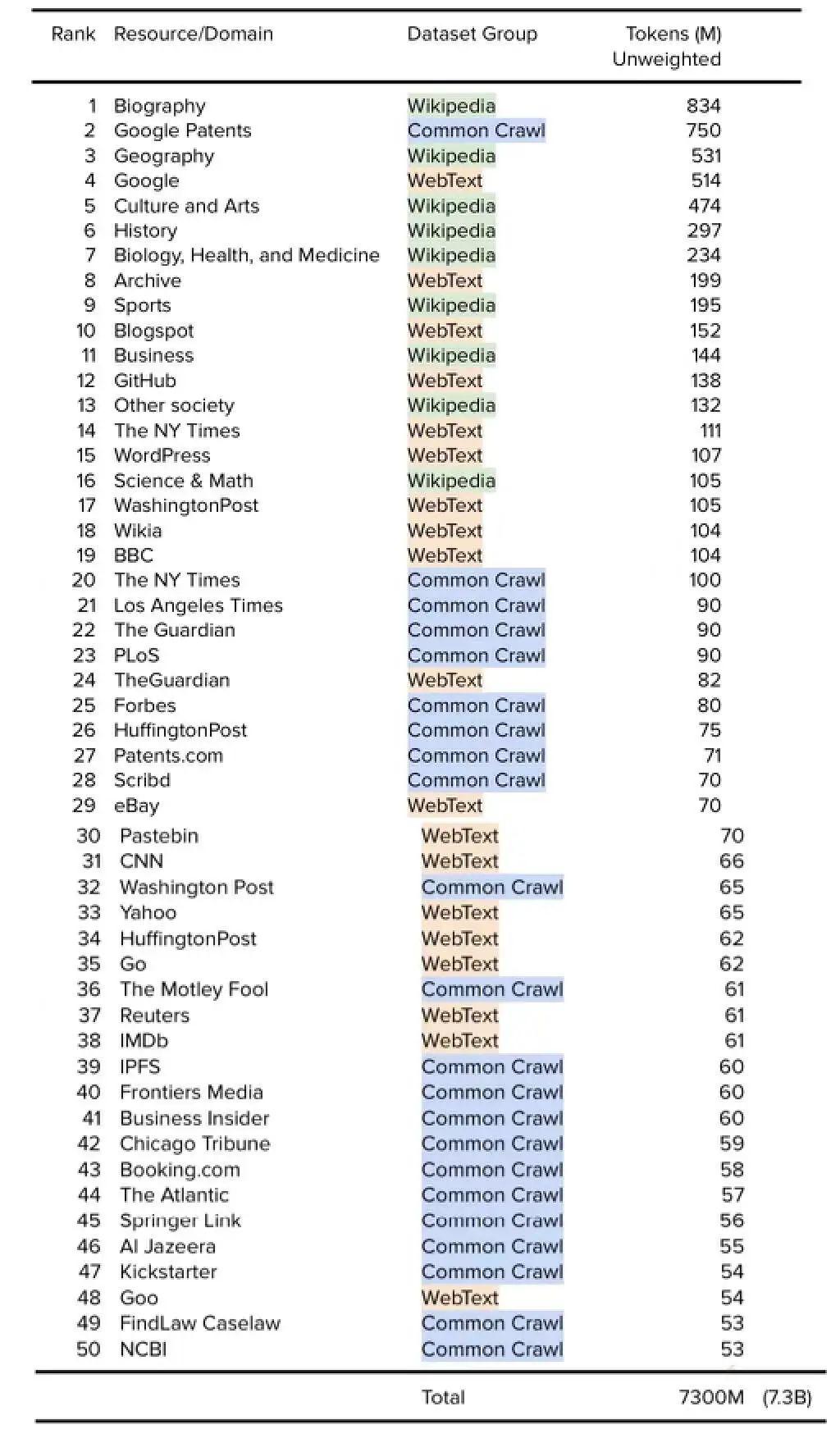
常用数据集


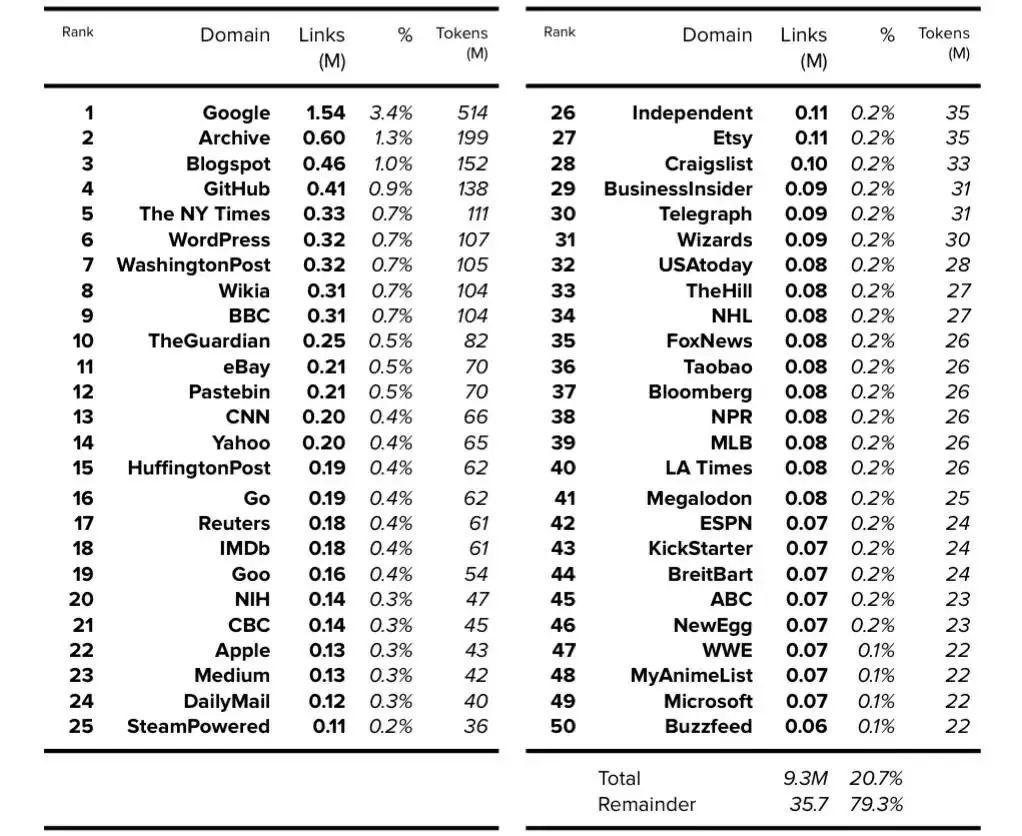
表3. C4:前23个域(不包括维基百科)。公开的数据以粗体表示,确定的数据以斜体表示。
3
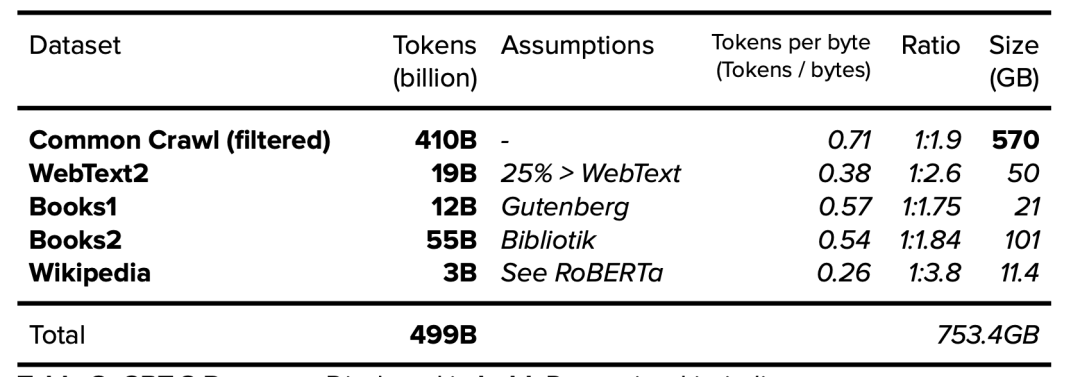
GPT-1数据集


4

5

6
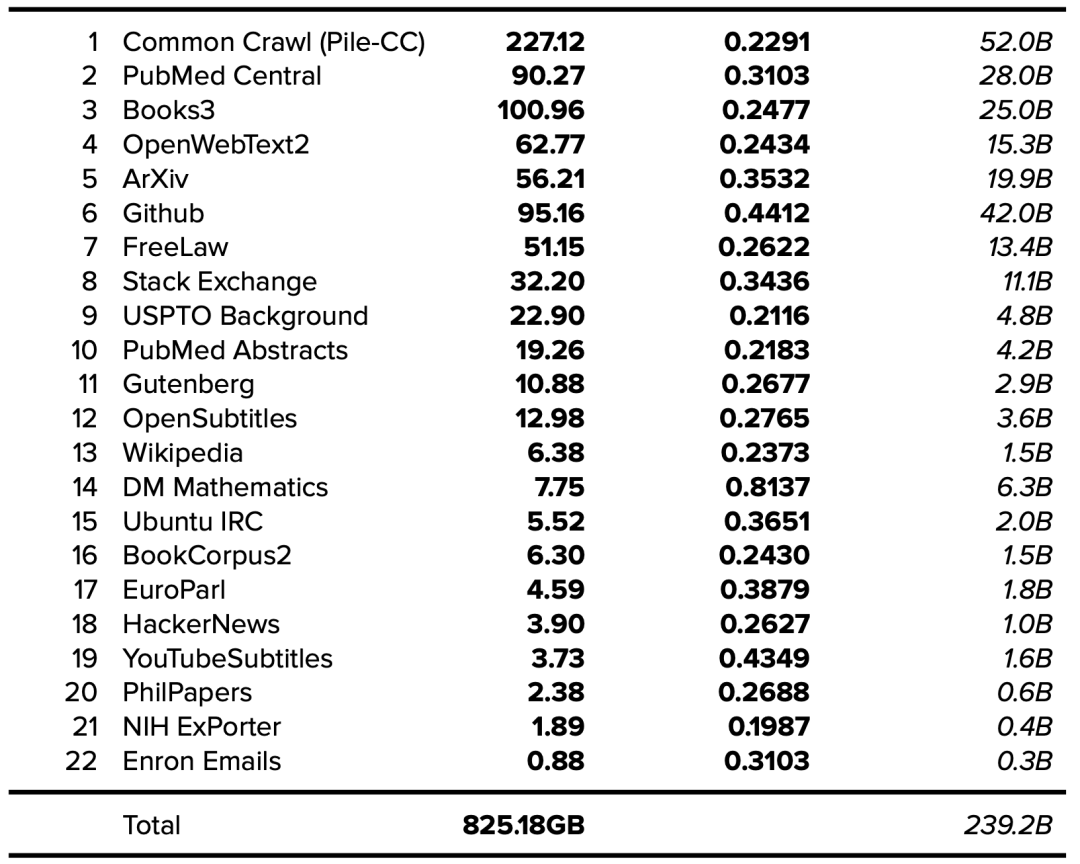
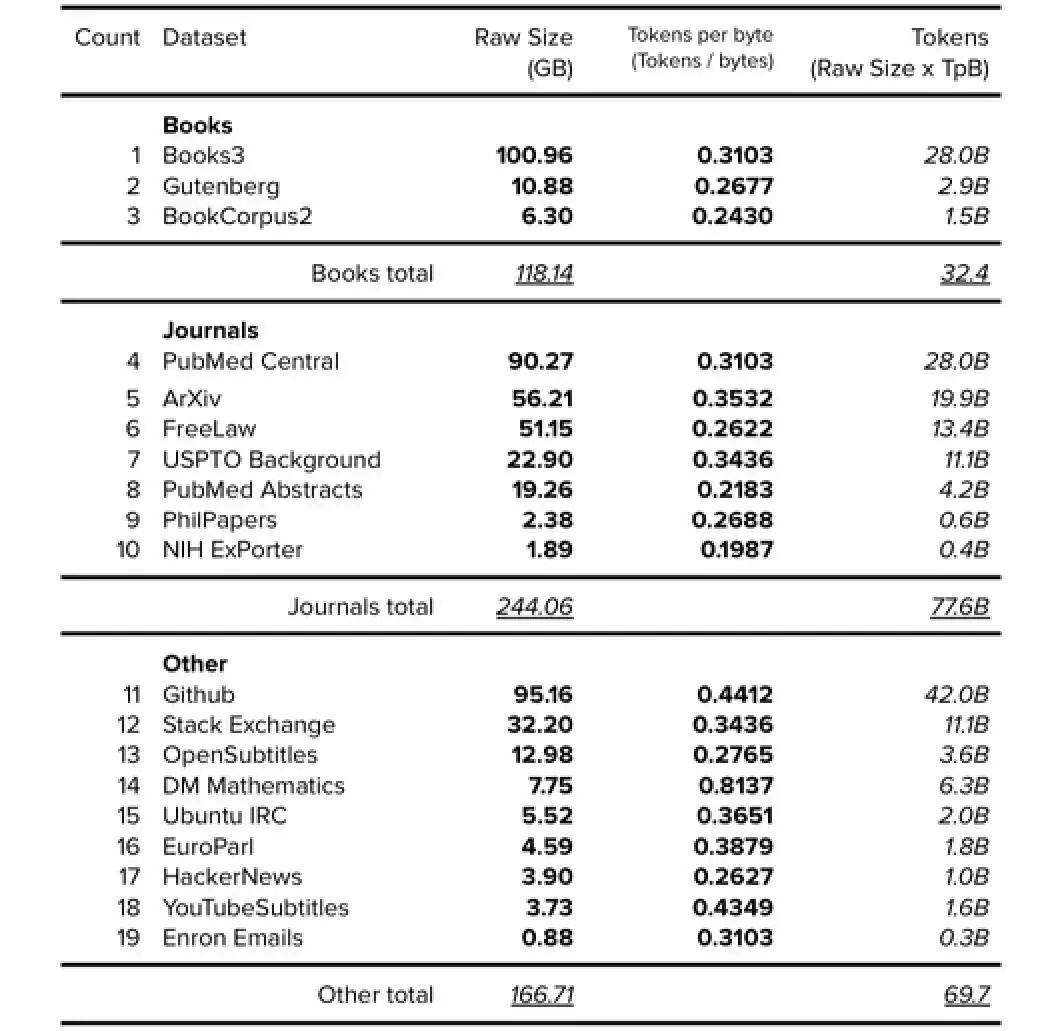

7

8
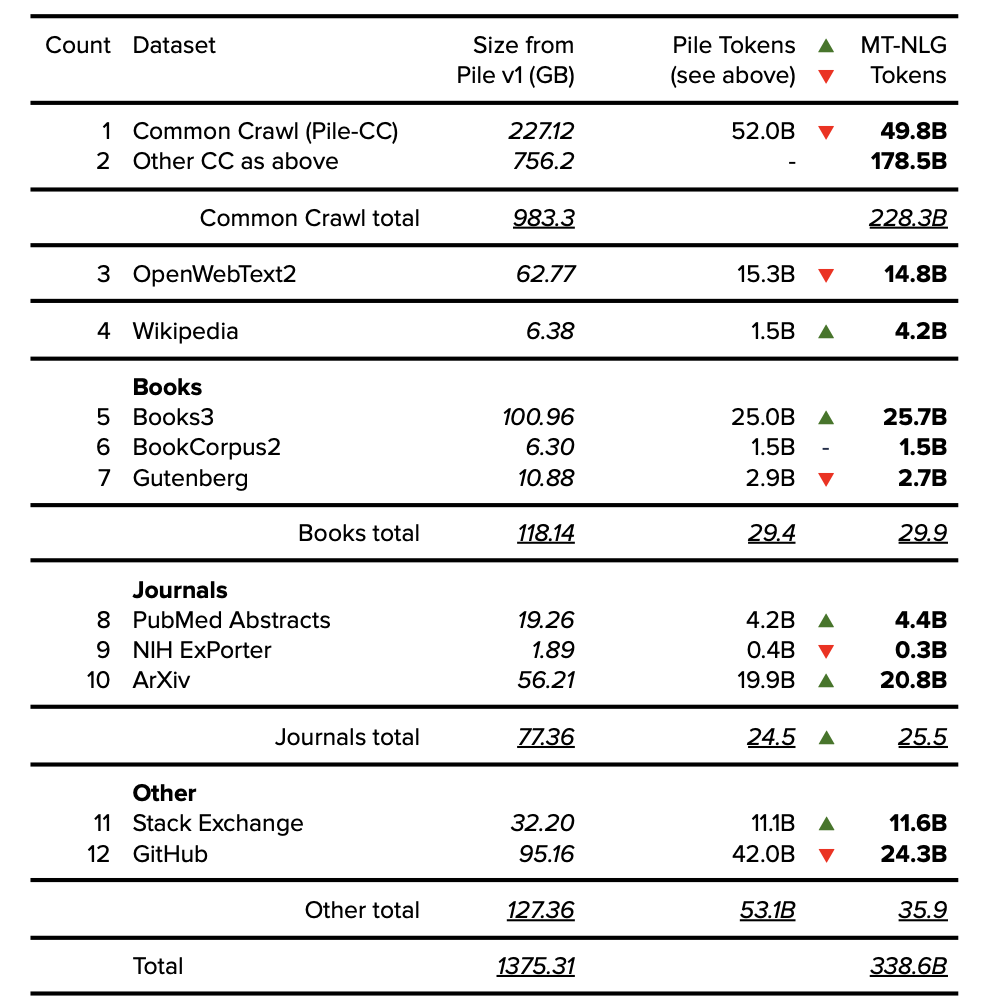

9
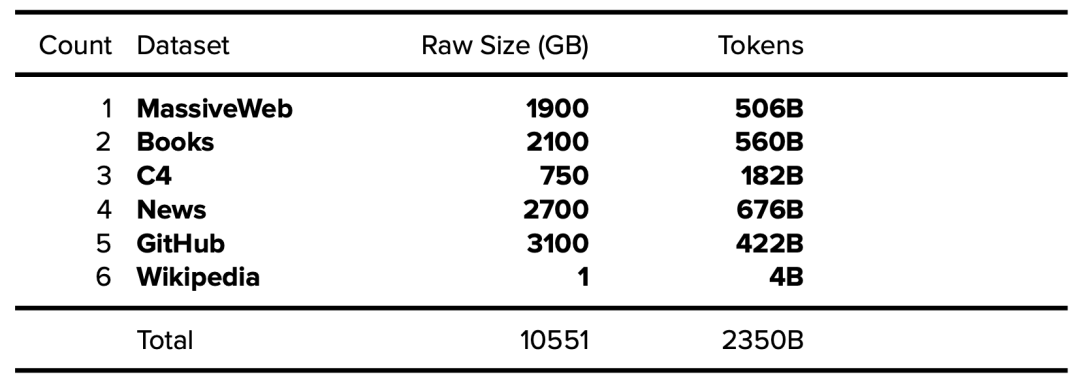

10
扩展阅读及脚注(请上下滑动)
关于作者
Alan D. Thompson博士是人工智能专家、顾问。在2021年8月的世界人才大会(World Gifted Conference)上,Alan与Leta(由GPT-3提供支持的AI)共同举办了一场名为“The new irrelevance of intelligence”的研讨会。他的应用型人工智能研究和可视化成果受到了国际主要媒体的报道,同时还在2021年12月牛津大学有关AI伦理的辩论中被引用。他曾担任门萨国际(Mensa International)主席、通用电气(GE)和华纳兄弟(Warner Bros)顾问,也曾是电气与电子工程师协会(IEEE)和英国工程技术学会(IET)会员。
(文章来源OneFlow,原文:https://lifearchitect.ai/whats-in-my-ai/)
END 
分享
收藏
点赞
在看

关于作者
Alan D. Thompson博士是人工智能专家、顾问。在2021年8月的世界人才大会(World Gifted Conference)上,Alan与Leta(由GPT-3提供支持的AI)共同举办了一场名为“The new irrelevance of intelligence”的研讨会。他的应用型人工智能研究和可视化成果受到了国际主要媒体的报道,同时还在2021年12月牛津大学有关AI伦理的辩论中被引用。他曾担任门萨国际(Mensa International)主席、通用电气(GE)和华纳兄弟(Warner Bros)顾问,也曾是电气与电子工程师协会(IEEE)和英国工程技术学会(IET)会员。
分享
收藏
点赞
在看