
这个数据集,绝了
大家好,我是DASOU;
前几天发现华为诺亚方舟实验室开源了一个亿级中文多模态数据集:悟空。
「悟空这个名字真的有意思了,之前也是诺亚方舟开源了一个中文预训练模型:哪吒」
我就去瞄了一眼:

现在大多数组在做多模态的时候基本还都是在做基于图像和基于文本的预训练模型的融合,相当于站在巨人肩膀做事情。
主要有两个原因,一个是从零训练一个多模态预训练模型太耗资源了,还有一个就是质量比较高而且数量比较大的多模态中文数据集太少了。
这个新发布的数据集不仅规模大——包含1亿组图文对,而且质量也很高。
所有图像都是筛选过的,长宽都在200个像素以上,比例从1/3-3不等。
而和图像对应的文本也根据其语言、长度和频率进行了过滤,隐私和敏感词也都考虑在内。
例如这一组数据集中的例子,内容还相当新,像进门扫码登记,社区疫苗接种的防疫内容都有。

这一波可以说是填上了大规模中文多模态数据集的缺口。
文本这边用的是BERT,图像这边用了三个,一个是ResNet「多种」,一个是VIT,一个是Swin;
整体架构比较简单,还是传统的方式:

其中视觉标记和文本标记作为输入。然后,将两种模式的输入标记连接起来,并用位置嵌入来显示标记位置。
除此之外,论文还提供了不同下游任务的基准测试。
例如零样本图像分类,下图中除了WukongViT-500M,其他的悟空模型变体都是在这个一亿的数据库上训练的:
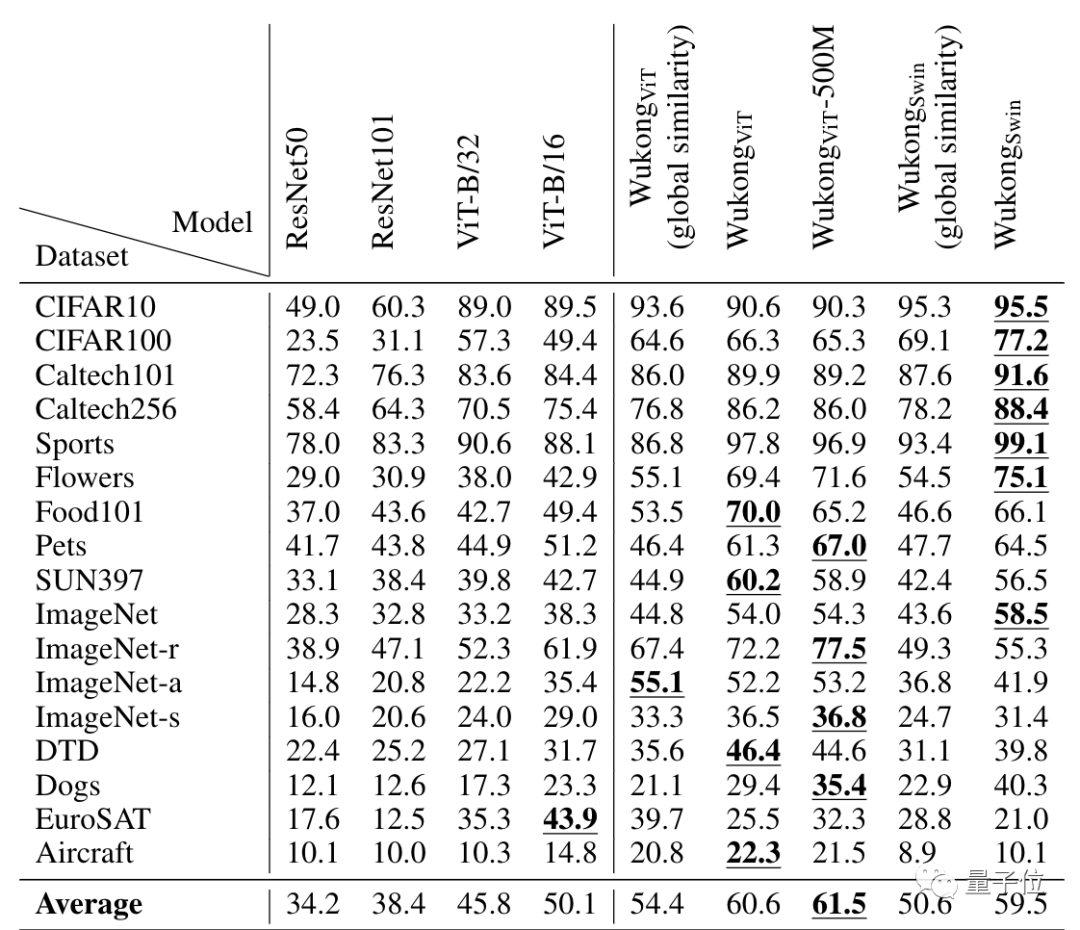
再比如在图像检索文本和文本检索图像这两个任务上,在五个不同的数据集上的测试结果如下:

而这也证明了将在英语数据集上预训练的图像编码器应用于中文多模态预训练的良好效果。未来也可能会探索更多的解决方案,利用悟空数据集训练多语言跨模态模型。
目前悟空数据集在官网即可下载(链接在文末),赶快用起来吧~
数据集地址:https://wukong-dataset.github.io/wukong-dataset/benchmark.html
论文地址:https://arxiv.org/abs/2202.06767
简单来说,这个数据集对于那些手上有计算资源但是没大量多模态数据的组来说帮助不小,大家可以去试试。
我看了下大小,大概是11多个G:
