
人脸分析:用合成数据来代替真实数据
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
杨净 发自 凹非寺 量子位 报道 | 公众号 QbitAI
相信吗?现在训练数据也用合成的了。

而且人脸分析任务上,准确性还不输真实数据的那种。
这是微软团队的一项最新研究,论文标题就已经说明了一切。
Fake it till you make it.

文章介绍了一种程序生成的3D人脸模型与一个合成数据库结合起来训练图像,结果人脸解析等任务上,效果与真实数据相当。
研究人员表示,为一些不可能实现人工标注的地方,开辟了新方法。
是不是以后真就告别人工标注了?!
如何实现?
要想让人脸数据集更加多样化、丰富化,靠收集和标注越来越难以实现。
且不说收集,比如网络抓取,可能带来重大的隐私和版权问题。而人工标注,很容易导致出错或者标签不一致的情况。
因此,研究团队就考虑用合成数据来增加或替代真实数据。然鹅,此前因为人脸模型本身复杂实现难度较为困难。
那么这次是如何实现的呢?
第一步,用程序生成合成面孔,包括身份、表情、面部纹理,以及发型和衣着,不同光线环境下的效果。

所有这些数据都是独立采样,提前“手动”去除噪音,以确保创建更多样化的个体。
比如在人脸模型上,就是这样滴~
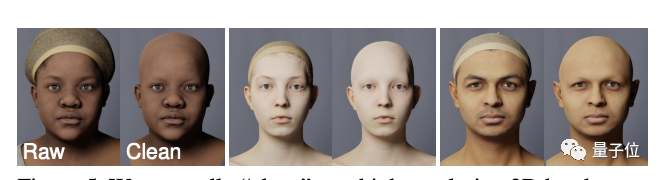
还有像衣着,则是由服装设计师和模拟软体设计师手工制作的,共有30套各种各样的衣服。
还包括头饰(36件)、面具(7件)和眼镜(11件) 。

除此以外,还合成了标签。

接着到了训练阶段,研究人员创建了一个10万张分辨率为512 × 512的图像的数据集,并做了数据增强处理,共用了150 张NVIDIA M60 GPU渲染48小时。
此外,团队还训练了人脸解析网络(仅使用合成数据)和标签适应网络,以解决合成标签和人工注释标签之间的系统差异。
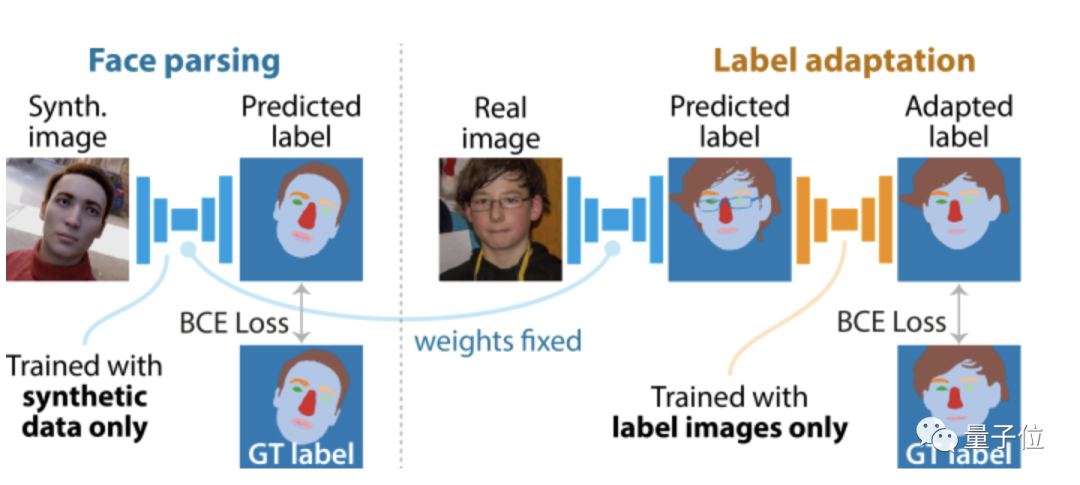
最终,人脸分析、地标定位等任务上的效果与其他采用真实数据的模型相当。
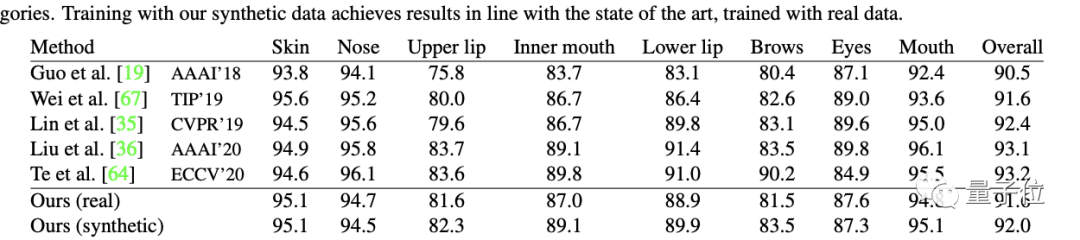

不过,研究人员也承认这项技术仍然有一定局限性。
比如人脸模型只有头部和颈部、无法模拟真实的皱纹、随机匹配人脸时会得到一些不合常理的面孔,比如有胡须的女性。
在接下来的工作中,他们计划将解决这些局限性。
好了,感兴趣的旁友可戳下方论文链接~
论文链接:
https://www.arxiv-vanity.com/papers/2109.15102/
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!