
我用《觉醒年代》做数据分析!
↑↑↑关注后"星标"Datawhale
每日干货 & 每月组队学习,不错过
Datawhale干货
作者:牧小熊,华中农业大学,Datawhale成员
最近有同学和我说《觉醒年代》好好看,于是我后知后觉地查了一下,不查不知道,这部剧豆瓣评分9.3,微博讨论度26亿+。《觉醒年代》都是哪些人在看?不如给受众群体做一个用户画像分析。

开始前要先准备数据,觉醒年代作为关键词在微博平台有很高的阅读量,于是就从微博作为切入口进行数据采集。
因为微博对爬虫的限制,我们只爬取了觉醒年代超话下的50页的相关信息,数量已经很多了,这个爬取的时间也比较长。
1. 数据准备
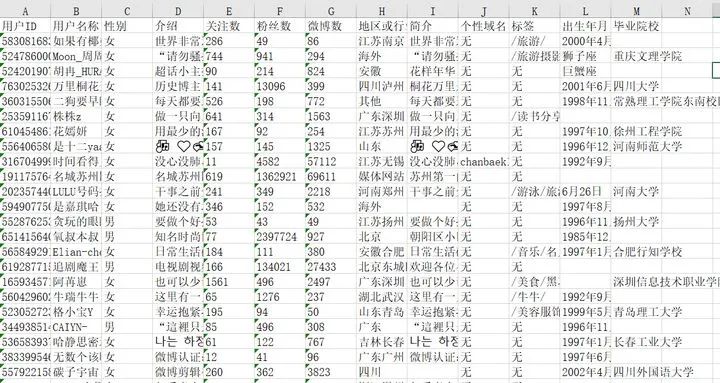
因为微博是动态加载的数据,因此我们使用了selenium操作浏览器对微博的数据进行了爬取。使用关键词#觉醒年代 进行搜索,爬取这个话题下的相关微博动态,共爬取了1300个相关微博动态以及微博用户的相关信息。
后台回复 觉醒年代 可获取打包的数据与代码
2. 数据分析实践
导入相关的数据
user=pd.read_excel('微博用户信息.xlsx')
info=pd.read_excel('微博信息.xlsx',header=None,names=['用户名','设备','内容'])
info

2.1 用户性别分布
from pyecharts.charts import Pie
from pyecharts import options as opts
data=[('男',266),('女',1081)]
pie = Pie()
pie.add("性别分布分析",data)
pie.set_global_opts(title_opts=opts.TitleOpts(title='用户的性别分布'))
#formatter参数{a}(系列名称),{b}(数据项名称),{c}(数值), {d}(百分比)
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{d}%"))
pie.render_notebook()
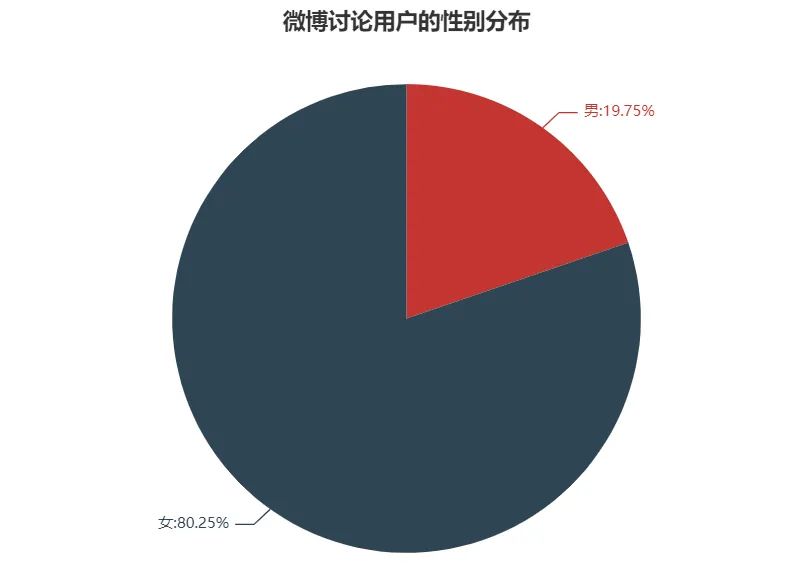
通过分析我看可以看到,微博讨论用户群中女性占比达到80.25%。
因为不能做全量数据抽取,数据的采集是通过微博动态采集,考虑到微博本身的用户性别占比,同时女性人群更爱通过互联网平台写自己的观影感受,因此我们的数据采集有一定的偏好性,但是也能说明《觉醒年代》的受众群体中,女性占据了一个较高的比例。
2.2 用户地域分布
因为地域分布的数据包含了省和地级市,因此我们需要进行一定程度的处理。
def clean(row):
pro=['上海','云南','内蒙古','北京','台湾','吉林','四川','天津','宁夏','安徽','山东','山西','广东','广西','新疆','江苏','江西','河北','河南','浙江','海南','湖北','湖南','澳门','甘肃','福建', '西藏','贵州','辽宁','重庆','陕西','青海','香港','黑龙江']
row=str(row)
flag1=row[:2]
flag2=row[:3]
if flag1 in pro:
return flag1
elif flag2 in pro:
return flag2
else:
return '其它'
user['地域']=user['地区或行业类别'].apply(clean)
location=user['地域'].value_counts()
data=[list(z) for z in zip(location.index, location)]
c=Map()
c.add(series_name="位置分布", data_pair=data, maptype="china",zoom = 1,center=[105,38])
c.set_global_opts(
title_opts=opts.TitleOpts(title='用户的位置分布',pos_left = 'center'),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(max_=150,range_color=["white", "#FA8072", "#FF0000"])
)
c.render_notebook()

从地域分布图来看,用户分布有2个高峰群,分别是北京和广东。分析其产生的可能原因是北京拥有较多的高校,广东包含了广州以及深圳两个一线城市,年轻用户群较多。包括一线、新一线以及江浙沿海地区也有较高的讨论度。
2.3 用户年龄分布
from pyecharts.charts import Bar
def age(row):
if '年' in str(row):
num=2021-int(row.split('年')[0])
if num>=40:
return '40岁以上'
elif 40>num>=30:
return '30-40岁'
elif 30>num>=20:
return '20-30岁'
elif 20>num:
return '小于20岁'
else:
return '其它'
else:
return '其它'
user['年龄']=user['出生年月'].apply(age)
columns=['小于20岁','20-30岁','30-40岁','40岁以上']
num=[100,464,62,23]
bar=Bar()
bar.add_xaxis(columns)
bar.add_yaxis('人数',num)
bar.set_global_opts(title_opts=opts.TitleOpts(title='微博讨论用户年龄分布',pos_left = 'center'),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name="人数",name_location='middle',name_gap=30,name_textstyle_opts=opts.TextStyleOpts(font_size=20)))
bar.render_notebook()
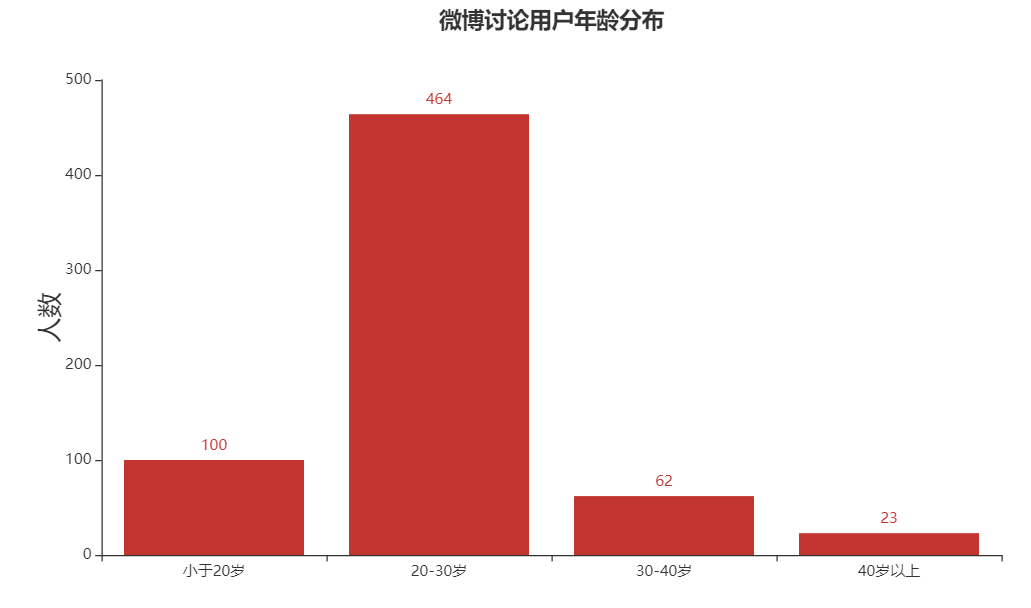
从微博讨论用户群来看,年龄主要集中在20-30岁之间,这说明《觉醒年代》在90后的观众有比较深远的影响。作为一部主旋律电影,让90后追剧上头足以证明它的诚意和质量。
这里也要留意潜在的数据采集误差,因为数据入口是微博讨论用户,平台中80以及90后本身就占据较大比例,同时90后更喜欢通过社交媒体自我表达。
2.4 用户设备分布
def device(row):
row=str(row)
if 'iPhone' in row:
return 'iPhone'
elif 'iPad' in row:
return 'iPad'
elif ('荣耀' in row) or ('honor' in row):
return 'honor'
elif ('HUAWEI'in row) or ('华为'in row) or ('nova'in row) or ('HarmonyOS' in row) or ('麦芒' in row) :
return 'HUAWEI'
elif ('mi'in row) or ('小米'in row) or ('Redmi'in row) or ('红米'in row) or('K30' in row ) :
return 'mi'
elif ('vivo' in row) or ('ColorOS' in row):
return 'vivo'
elif 'OPPO' in row:
return 'oppo'
elif 'OnePlus' in row:
return 'OnePlus'
elif 'iQOO' in row:
return 'iQOO'
elif ('真我' in row) or ('realme' in row):
return 'realme'
elif '三星' in row:
return 'sumsung'
elif '索尼' in row:
return 'sony'
else:
return '其它'
info['device']=info['设备'].apply(device)
columns=['iPhone','HUAWEI','mi','honor','oppo','vivo','iPad','OnePlus','sumsung','realme']
num=[497,222,58,44,41,36,13,5,4,2]
data=[list(x) for x in zip(columns,num)]
pie = Pie()
pie.add("微博讨论用户手机品牌分布",data)
pie.set_global_opts(title_opts=opts.TitleOpts(title='微博讨论用户手机品牌分布',pos_left = 'center'),legend_opts=opts.LegendOpts(is_show=False))
#formatter参数{a}(系列名称),{b}(数据项名称),{c}(数值), {d}(百分比)
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b} {d}%"))
pie.render_notebook()
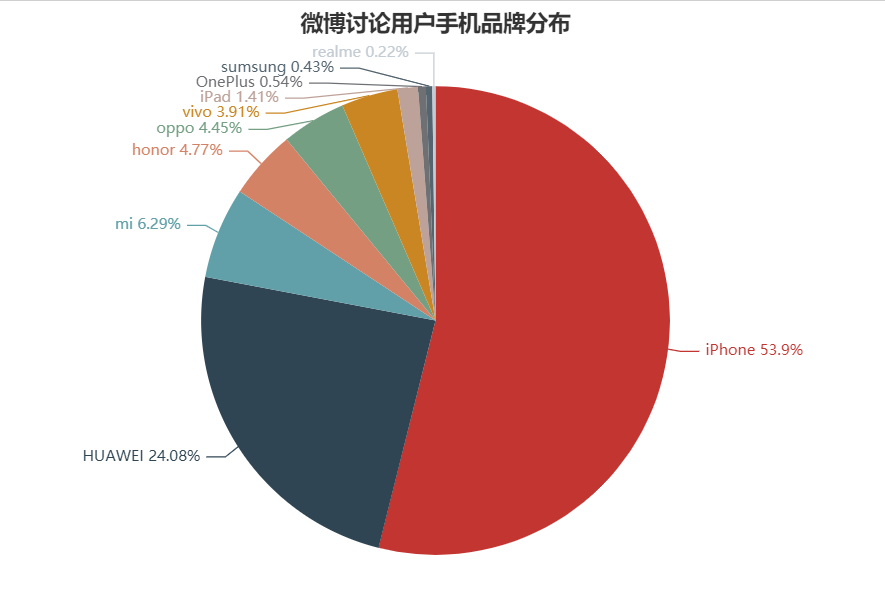
通过数据来看,微博讨论用户的主力设备是iPhone和华为,其中苹果设备占比超过了50%,随着苹果手机价格的降低在市场占有率上有着明显的优势。
2.5 用户个性标签词云
且慢!在开始做词云之前,要先删除停顿词,停顿词往往没有有效的含义还会占据大量位置,影响词云的效果。
在github上找到了停顿词表:
goto456/stopwords:https://link.zhihu.com/?target=https%3A//github.com/goto456/stopwords
#pip install jieba
import jieba
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
from collections import Counter
content=''.join([str(i) for i in list(info['内容'])])
stopwords = [line.strip('') for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()]
jieba.add_word("觉醒年代")
jieba.add_word("yyds")
content=[x for x in jieba.lcut(content) if x not in stopwords and len(x)>1]
content=Counter(content)
test_mask = np.array(Image.open("datawhale.png"))
stopwords = set(STOPWORDS)
stopwords.add("said")
wc = WordCloud(background_color="white",mask=test_mask,font_path='simhei.ttf',width=5000,height=5000,
stopwords=stopwords)
wc.generate_from_frequencies(content)
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
wc.to_file("test.png")

2.6 角色讨论热度
import pandas as pd
hero=['陈独秀','李大钊','延年','鲁迅','乔年','蔡元培','胡适','毛泽东','周恩来','辜鸿铭','顾维钧','赵纫兰','汪大燮','邓中夏','柳眉','白兰','吴炳湘','易白沙','高君曼','章士钊','黄侃','沈尹默']
content=''.join([str(i) for i in list(info['内容'])])
hero_num=[]
for i in hero:
num=content.count(i)
hero_num.append((i,num))
hero_num=pd.DataFrame(hero_num)
hero_num.columns=['人名','出现次数']
hero_num=hero_num.sort_values(by='出现次数',ascending=False)
hero_num=hero_num.reset_index(drop=True)
columns=list(hero_num['人名'])[:10]
num=list(hero_num['出现次数'])[:10]
bar=Bar()
bar.add_xaxis(columns)
bar.add_yaxis('次数',num)
bar.set_global_opts(title_opts=opts.TitleOpts(title='微博讨论角色频率分布',pos_left = 'center'),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name="次数",name_location='middle',name_gap=30,name_textstyle_opts=opts.TextStyleOpts(font_size=20)))
bar.render_notebook()
对于剧中的常用角色对内容进行匹配,选出来排名前10的角色
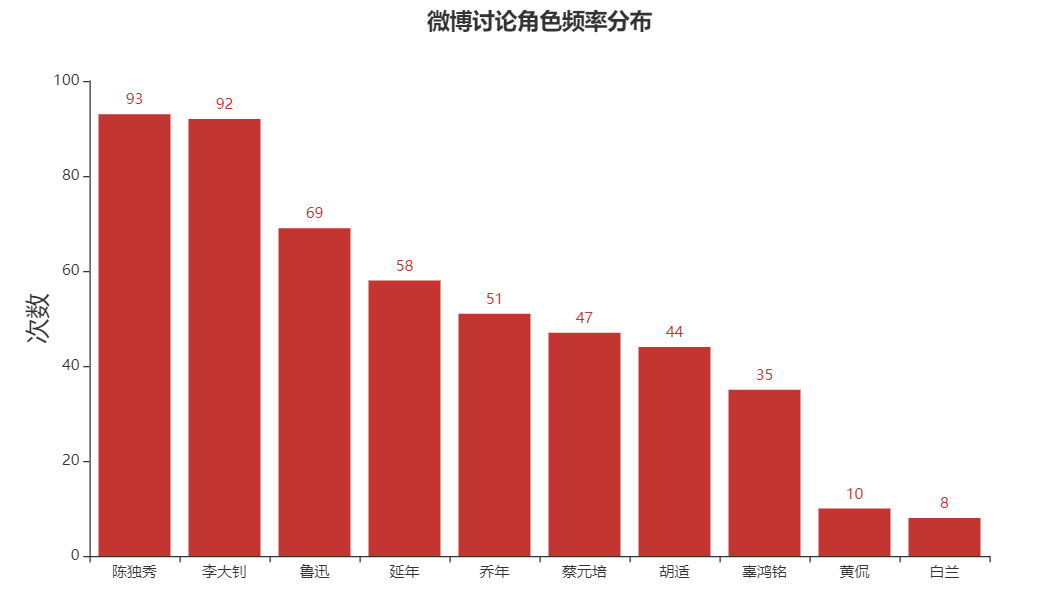
可以看到根据讨论内容中出现的次数来看,陈独秀及李大钊两位作为主角,讨论热度遥遥领先于其他角色,延年与乔年也都是排行在前列。
也是在电视剧播出后,很多市民在延乔路鲜花,想起了习总书记在中国共产党成立100周年上的讲话:中国人民也绝不允许任何外来势力欺负、压迫、奴役我们,谁妄想这样干,必将在14亿多中国人民用血肉筑成的钢铁长城面前碰得头破血流。这盛世,如你所愿!

3. 数据及代码
在本次的项目中,我们爬取了微博关键词下的相关数据,同时对数据进行清洗与相关的可视化分析,项目中包含了一定的可视化技巧,适合初学者进行相关的学习。如需代码数据,公众号后台回复 觉醒年代 可下载。
干货学习,点赞三连↓