
CVPR2019 | 目标检测 FSAF:为金字塔网络的每一层带去最好的样本
作者:ChenJoya
编辑:黄俊嘉
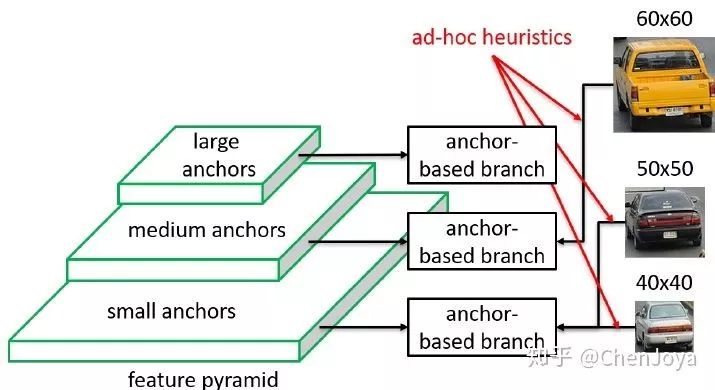
今天为大家奉上一篇 CVPR2019 关于目标检测的文章:Feature Selective Anchor-Free Module for Single-Shot Object Detection,它深入探究了在目标检测中广泛采用的特征金字塔网络 FPN(Feature Pyramid Network),并且指出了一个极其隐蔽的问题:不同尺寸的物体依据其与 FPN 每一层 Anchor 的适配程度,分配到不同分辨率的层上进行学习,期望其能够充分适配各层感受野和空间信息,从而使得检测器能够检测尺寸不一物体;这种启发式的方法虽听着合理,却没有明确的证据,我们并不知道一个确切的 ground-truth 分配到哪一层上去学习是最合适的。因此,要想取代这种分配方式,就必须不再依赖每一层 anchor 和 ground-truth 的 IoU 来做分配。因此本文提出的模块也是就叫做 Feature Selective Anchor-Free Module(FSAF),让网络自己学习该怎么分配,为金字塔网络的每一层带去最好的样本。

01
方法
很明显,要想取代上述的分配方式,那么“把 FPN 上所有层的所有 anchor 全部拿过来,和 ground-truth 计算 IoU”这一步就不能有。因此作者提出了一个 anchor-free 的 module,称为 FSAF,大体思想是在每一层都插入这个模块,尝试不用 anchor 去检测 instance,而后看看哪一层的 FSAF 对于这个 instance 的损失最小,不就可以认为这一层是最适合检测这个 instance 的吗? 接着 FSAF 大喊一句“安排”!!!把这个物体安排到这个层,再用 anchor-based 的模块去检测,如下图所示:
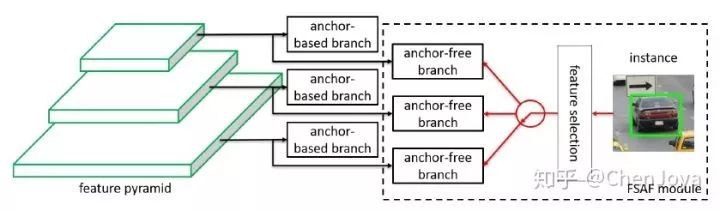
那么我们需要关注两个问题:
anchor-free branch 是怎么不借助 anchor 去检测物体的?
anchor-free branch 怎么和 anchor-based branch 联合起来?
对于(1):作者说他的设计十分 simple,是真的 simple,这十分惹人喜欢;
对于(2):FSAF 中也是采用的最自然的
jointly training 方法。下面来具体看看:
(1)anchor-free branch 是怎么不借助 anchor 去检测物体的?
不借助 anchor 去检测的方法已经层出不穷了,诸如 CornerNet,ExtremeNet 等,戳 Tenacious:目标检测最新方向:推翻固有设置,不再一成不变Anchor(https://zhuanlan.zhihu.com/p/56228320)。在这里,实现 anchor-free detection 则简单的多,在 RetinaNet 的 box 和 cls 分支上仅仅各加了一层 conv layer,分别生成一个 W × H × K classification output 和一个 W × H × 4 的 regression output,如下图:
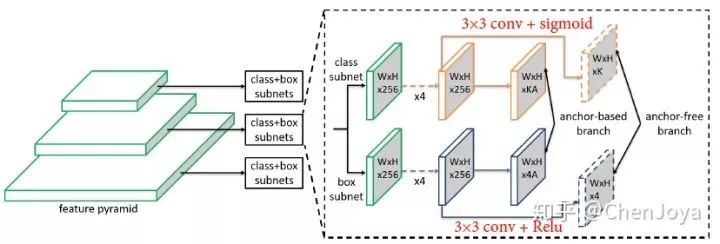
其中 K 是类别数量,classification output 的 每一个 pixel 就表示这个位置应该是什么类别,它的标签可以通过 ground-truth 投影计算,并且设置一定的比例后得到,如下图,在 instance 的 0.2 倍 box 内为 positive,提供的标签即为“车”这个 class id;在 0.5 倍 box 内进行忽略;其他都设为负。而 regression output 只针对于 0.2 倍的 instance box 进行训练,回归像素点(i,j)离边界的距离,如下图所示:
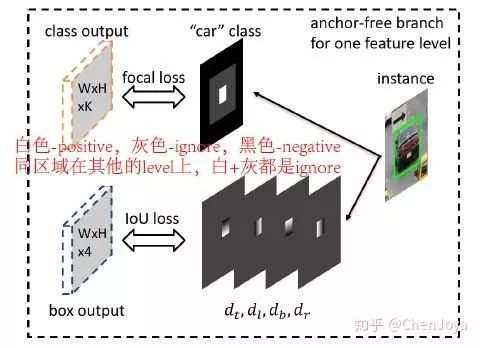
这可真是最简单的 anchor-free detection 了,不过效果略差,在后面 ablation study 内有提供的检测结果大约是 34~35 AP,不过人家主要是用来做分配的,当然也没有关系。
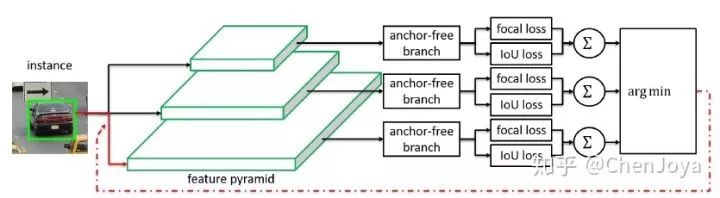
(2)anchor-free branch 怎么和 anchor-based branch 联合起来?
再看这张图,哪一个 anchor-free branch 输出的 loss 最小,就把 ground-truth 分配去哪一个层:
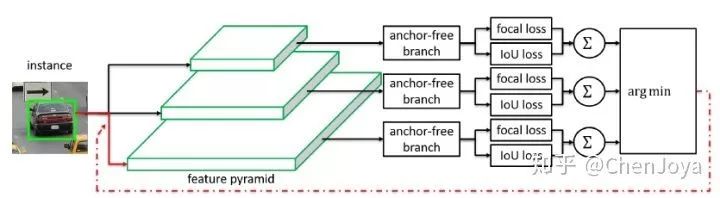
在训练阶段,它与 anchor-based 的分支进行加权训练,通过 λ = 0.5 进行权衡。在推理的时候,还需要进行这样的 selective 吗?当然不用了,不过要把 anchor-free branch 得到的 box 拿过来和 anchor-based branch 一起做 NMS。
02
实验
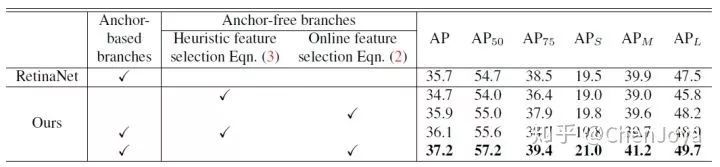
我们首先来关注 online feature selection 是不是必要的。如果不采用 loss 决定分配层,而是采用 FPN 应用于 two-stage 中公式  来选层的话,对于 anchor-free branch,AP 下降了 1.2 (35.9 → 34.7),当有 anchor-based
branch 后,采用 online feature selection 可以比公式选层增加 1.1 的 AP(36.1 → 37.2)。
来选层的话,对于 anchor-free branch,AP 下降了 1.2 (35.9 → 34.7),当有 anchor-based
branch 后,采用 online feature selection 可以比公式选层增加 1.1 的 AP(36.1 → 37.2)。
这里有两个细节值得留意:
按照公式选层+anchor-based竟然比原来一把抓 anchor 按照 IoU 选层要高出 0.4(35.7 → 36.1)! 这到底是加了 anchor-free branches 带来的提升,还是一把抓 anchor 匹配 ground truth 确实还不如按公式选层?
anchor-free branches 加上 online feature selection 可以超过原生 RetinaNet 0.2 个 AP(35.7 → 35.9)!这就很有意思了,这么简单的一个 anchor-free detector 超过了 RetinaNet。
接着我们来关注 online feature selection 分配的框和 RetinaNet 分配的框有什么区别,如下图,作者说,总体上 FSAF 还是遵循了 upper levels select larger instances, lower levels are responsible for smaller instances,但是也有例外(图中红色box),也许正是由于这些例外进一步提升了 AP 吧。

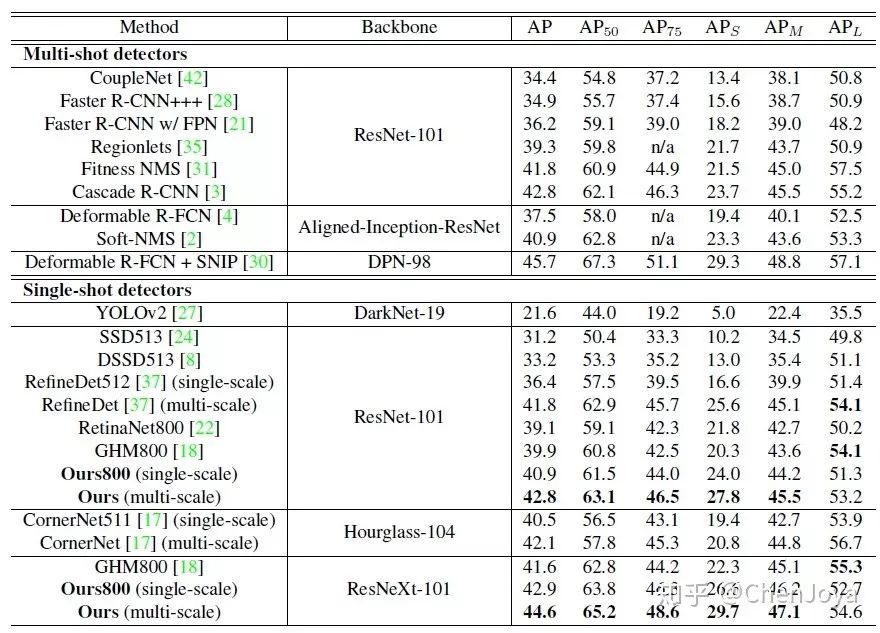
最后来看一张 SOTA 总体 AP report,在多尺度训练和测试的加成下,在 ResNeXt-101-64x4d 的backbone 下达到了 44.6 的 AP。在时间消耗方面,作者声称在 ResNeXt-101 下比原来 RetinaNet 慢了6ms。
03
总结
这篇文章面向于目标检测中广泛使用的 FPN 结构,细致挖掘出了在 anchor 分配时这个隐蔽的问题,从而较为自然的设计出了 Feature Selective Anchor-Free Module。而同年命中的检测/分割论文
Mask Scoring R-CNN(https://arxiv.org/abs/1903.00241),
Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression(https://arxiv.org/abs/1902.09630)
Region Proposal by Guided Anchoring(https://arxiv.org/abs/1901.03278)
等都与其相似,深入探讨和解决现有 pipeline 中一个小巧而精致的问题,让人回味无穷。

END
往期回顾
机器学习算法工程师
一个用心的公众号
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助
(更多详情请点击原文链接)