
一种关注于重要样本的目标检测方法!
背景
论文是基于anchor的目标检测中正负样本采样的。首先来一起回顾下整个过程。
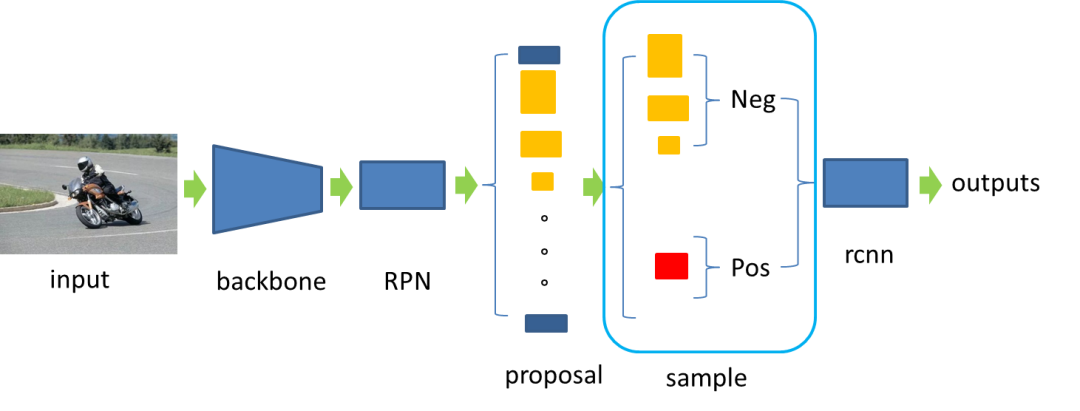
以经典two-stage目标检测网络Faster-rcnn为例,如图所示,过程大致为:
图片输入经过backbone得到feature_map,
然后经过RPN网络得到proposal,
再将proposal进行1:3的正负样本的采样,
将采样后的正负样本送入rcnn阶段进行分类和回归。
图中蓝框区域就是本文要研究的内容:
问题分析
在这样一个正负样本采样阶段,目前主流的算法都是怎么做的?
Faster-rcnn,将采样后的正负样本直接送入rcnn阶段进行分类和回归; ohem,将loss大的proposal视为难例,在采样的时候优先采样这些样本; focal_loss,通过两个超参数调节不同难易程度样本的loss。
还有很多别的关于正负样本采样的研究,这里不一一列举,但是目前来看,大部分关于这部分的优化,都是想要去优化难例样本,也就是说,一个proposal在训练的时候贡献的loss越大,越需要去优化,但是这样真的是对的吗?或者说,对于模型来说,这些难例样本真的是最重要的吗?
这里我们举一个例子,看一下本文认为什么是重要的样本,如下图所示:
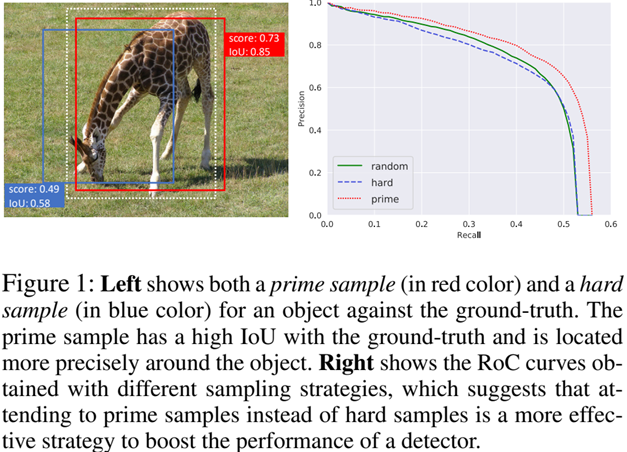
左图:白色虚线表示ground truth,红色框表示本文认为的重要样本(prime sample),蓝框为难例样本。
右图:不同采样策略下模型的PR曲线,random表示平等对待各个样本,hard表示重点关注难例样本,prima表示重点关注重要样本。
可以看到,基于prime sample的采样策略能够更好地提升检测器的性能,原因是什么呢?
我们以左图为例,对于左图来说,对于这样一个检测结果,往往我们希望去优化蓝框,因为它的loss更大,这是可以理解的。
但是对于这样一个图片,已经有更好的红框了,其实是没有必要去优化蓝框的,因为最终蓝框只要比红框得分低,它就会被后处理NMS干掉,从而不对检测指标有贡献,因此,此时,与其去优化蓝框,不如进一步优化红框,使其更加精确。换句话说,红框才是更重要的。
重新审视mAP
以COCO计算mAP的过程为例,大致分为以下四步:
以间隔0.05对在0.5~0.95内采样iou阈值 在每个iou阈值下,计算PR曲线,得到AP值 将所有iou阈值下的AP值平均得到mAP(m--mean iou) 所有类别的mAP进行平均得到总的mAP(m--mean class)
接下来我们看一下,从mAP的指标上来看,哪些正负样本是更重要的?
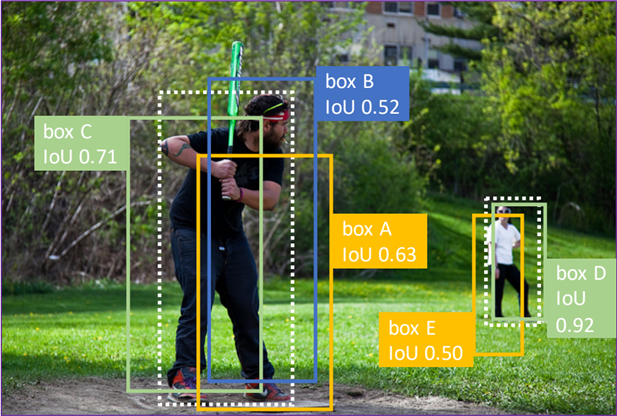
文章中说,对于单一gt bbox来说,与其重叠的所有预测边界框中,具有最高IoU的bbox最为重要。以图左边这个目标为例:
对于白色虚线gt来说,预测边界框有bbox A, bbox B,bbox C,那么bbox C是最重要的,其原因在于它和gt的IOU是最高的,倘若不考虑每个框的置信度以及NMS的影响,当计算AP50的时候,ABC都可以被认为检测到gt。
但是当计算AP70的时候,只有C表示检测到了gt,而此时A、B虽然表示没有检测到gt,但是有C检测到了,就不影响recall了,所以C是直接影响召回的,因此它是最重要的。
对于多目标gt bbox来说,在所有针对不同对象的IoU最高bbox中(图中bbox C和bbox D),具有更高IoU的bbox(图中bbox D)更为重要。以图中两个目标为例:
依旧类比单目标的思路,这里假设要计算AP50,那么两个目标分别被C和D很好的检测到,但是要计算AP90,就只有D贡献recall了,要计算AP95,那整张图的mAP直接到0,也就是说,随着mAP计算过程中IOU阈值的增大,最后还是靠D一直在顶着,因此它是最重要的。
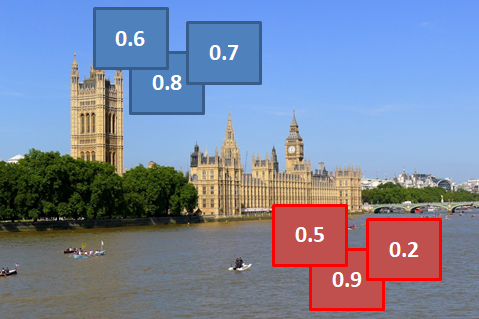
以图为例,负样本是没有IOU的概念的,只有置信度得分,在nms之后,每一簇负样本中(蓝色的一簇,红色的一簇)分数最高的被保留下来,因为它们背景区域被检测为某类别正样本的负样本,所以被预测为某类别分数越高代表其错的越厉害,也就是越重要。越重要也就是越需要重点关注去优化,但是与优化正样本不一样,对负样本的优化是希望高分数能够降下来。
PISA算法
基于以上内容,我们再来看一下PISA这篇论文是怎么做的,其实主要内容上面已经说了,就是为了得到高的mAP,分析出哪些正负样本对mAP指标的提高是最重要的。因此,下面主要就涉及两方面内容,第一,如何去找重要的样本?第二,对重要程度不同的样本分别做什么操作?
一、查找重要样本--HLR
(1)IOU-HLR,对正样本进行分层排序
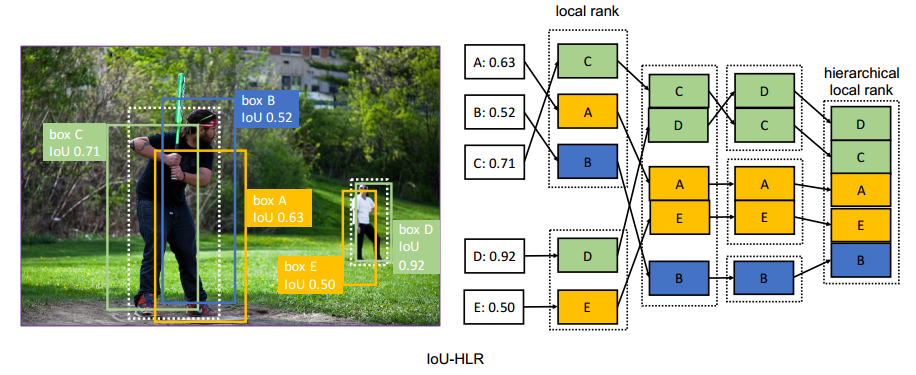
排序的过程图中表示地比较清楚,总结一下就是,对于单一目标附近的样本(ABC, DE),首先根据IOU在组内排序(CAB,DE),然后对不同类别同一顺位的样本排序(DC, AE, B),最后将排序后的样本重新组合。这么做既考虑了组内重要性,又考虑了组间重要性。
这里有一个简单的小实验,简单验证了本方法的有效性:
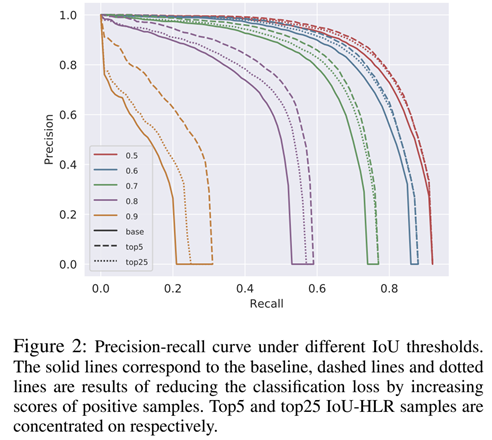
图中展示的是,不同IOU阈值下的PR曲线,top5/top25表示按照IOU-HLR排序方法排序后得到的top5/top25的重要样本。两点结论,第一,关注重要样本,的确能提升AP。第二,关注重要样本,对高IOU阈值下的AP增益更大。
(2)Score-HLR,对负样本进行分层排序
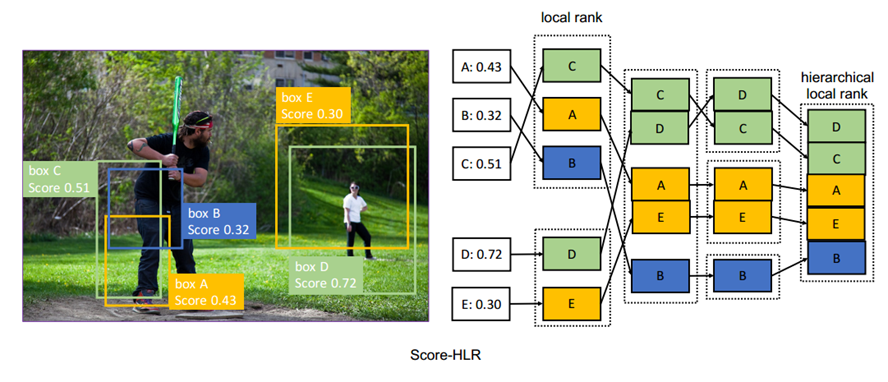
这个过程跟正样本差不多,不同的是正样本依据的是IOU,负样本依据的是Score,都能跟前面的分析照应。
二、算法实现
1. ISR
在对所有样本重要性进行排序之后,怎么跟训练过程联系起来呢?
这里采用的方法叫做ISR(Importance-based Sample Reweighting),即基于样本重要性重新赋予权重。
分为以下几个步骤:
(1) 首先将每个类别的样本分组(N个前景类别+1个背景类别),n_max表示在每个类别中样本数最多的数目,在每个组内对正样本进行IoU-HLR操作,对负样本进行Score-HLR操作,得到重要性排序。
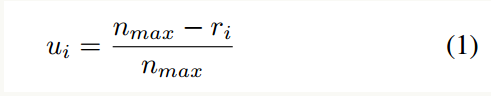
然后按照公式(1)将重要性排序进行线性变换,r_i表示某样本排序后的次序,r_i越小表示排序越靠前,可以看到r_i越小,u_i越大。
(2)再按照公式(2)将u和每个样本的权重w建立联系,为不同重要性的样本赋予不同的权重,其中β和γ是超参数。
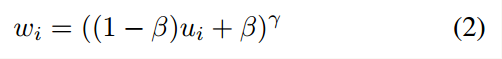
(3)最后将重新赋值的权重应用到分类损失的计算上。
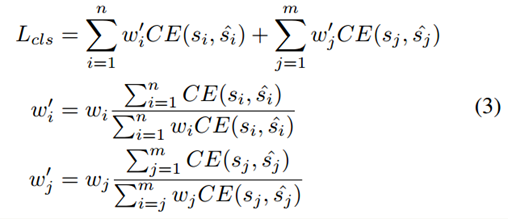
其中i表示正样本,j表示负样本,这里为了保证应用ISR之后不改变总的loss值,对ISR之后的每个样本的权重进行了归一化。
2. CARL
在为不同的样本根据重要性排序结果赋予不同权重之后,本来进而提出了CARL(Classification-Aware Regression Loss),来解决分类和回归不一致的问题,也就是有时候回归的好,但是分类分数差之类的问题。因为我们计算mAP的时候,不仅需要高的IOU阈值,更要高的分类置信度,毕竟NMS会首先保留下来分数最好的检测结果。
其做法如公式(4)所示,就是将分类置信度p_i引入到回归损失中,经过推倒可以证明,回归损失L(d_i, ^d_i)和L_carl对p_i的倒数是正相关的,回归损失较大的样本的分类分数会被抑制,这样让样本的回归结果指导分类分支,加强分类和回归的一致性。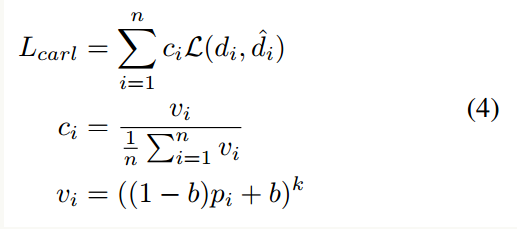
实验结果
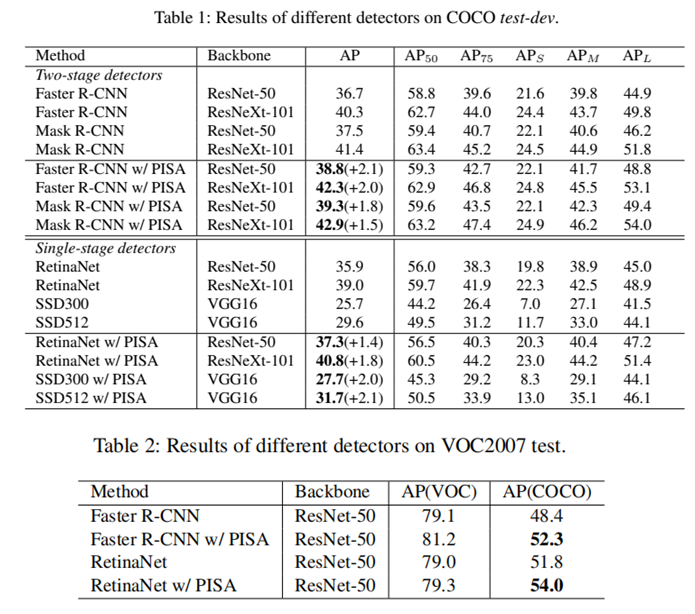
1. PISA应用在不同检测器时,在COCO和VOC测试集上带来的增益。
可以看到,基本都有涨点,尤其是对高IOU阈值下的AP指标(AP75)涨点较多。
2. 消融实验
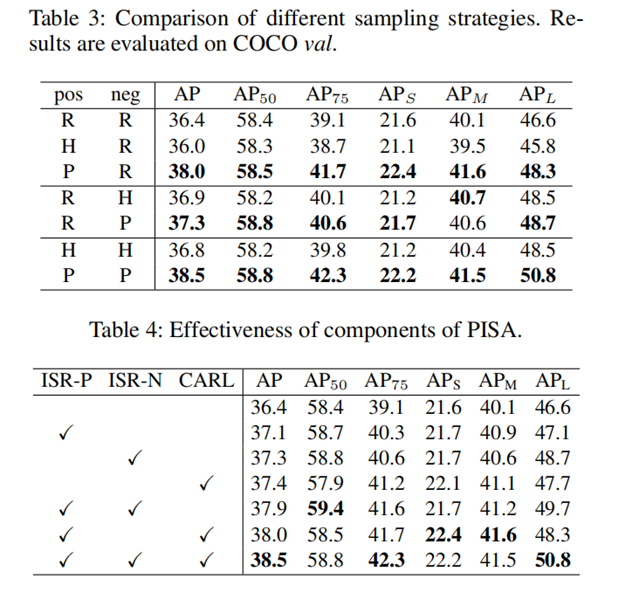
表3中,R表示平等对待所有样本,H表示关注难例样本,P表示关注主要样本。
表4中,ISP-R/ISR-N分别表示为正/负样本基于重要性重新赋予权重。CARL指分类和回归分支联合调优的应用。
3. 超参数搜索实验
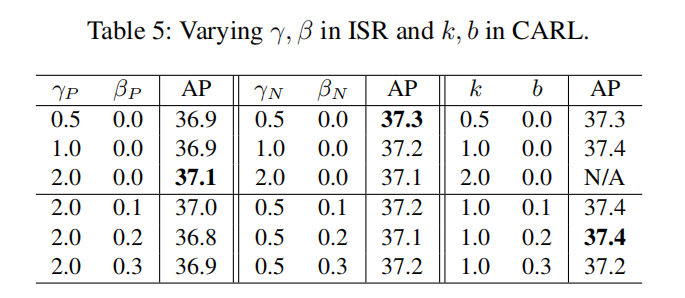
表5为公式(2)和公式(4)的超参数搜索实验结果。
4.ISR对样本分数的影响
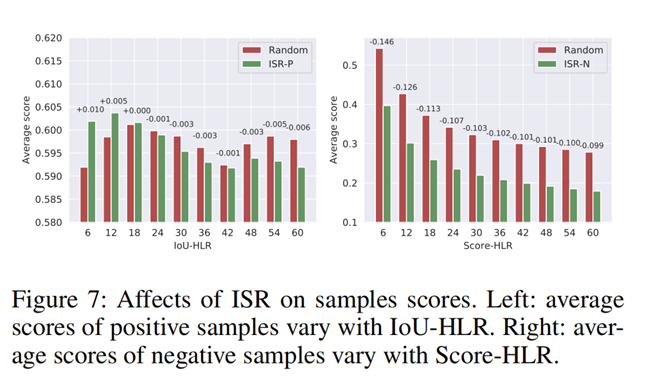
横坐标表示样本的重要性顺序,纵坐标表示样本分数。
可以看到,ISR-P能够提升重要性排名靠前的正样本的分数,且抑制重要性排名靠后的样本的分数。
ISR-N也的确能够抑制负样本的分数,且重要性排名越靠前,其分数被抑制的越多。
5. CARL对样本分数的影响
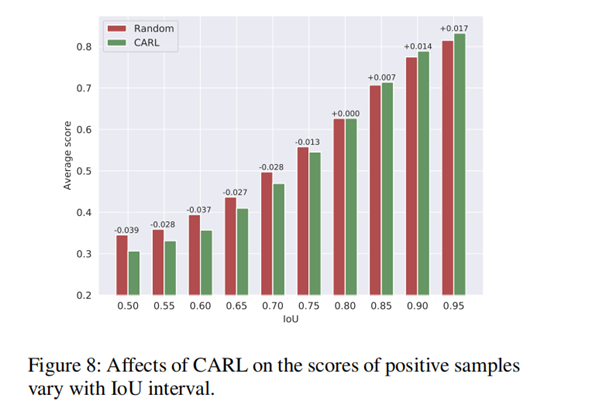
图8展示了应用CARL之后,不同IOU下样本分数均值的变化,可以看到,CARL能够提升高IOU下重要样本得分,低IOU阈值下样本得分会被抑制,也就是说,有了更好的,不那么好的就可以考虑丢了呀。
6. 可视化结果

从可视化结果可以看到,PISA能够使模型更关注于重要样本的优化,使得检测结果中有更少的假阳,且真阳的分数更高。
以上解读仅代表个人观点,水平有限,欢迎交流~
本文来自由周郴莲负责的Datawhale论文分享项目「Whalepaper」,NLP、CV、Res…每周一起解读论文!
Whalepaper介绍及加入方式:https://datawhale.feishu.cn/docs/doccnAbq5hJPaVB645IztpFPdld