
用于语言引导视频分割的局部-全局语境感知Transformer
0. 引言
随着Transformer的大火,NLP任务和CV任务的壁垒逐渐被打通。视频分割一直是一项极具挑战的任务,因为它对理解整个视频内容和各种语言概念提出了很高的要求,现有的基于FCN的LVS解决方案很难充分利用全局视频语境以及全局视频语境和语言描述之间的联系,但Transformer无疑为其提供了新的解决方法。本文将带大家精读2022 CVPR论文"用于语言引导的视频分割的局部-全局语境感知Transformer",该文章提出的视频分割模型在多个数据集上取得了SOTA效果,并且已经开源。
1. 论文信息
标题:Local-Global Context Aware Transformer for Language-Guided Video Segmentation
作者:Chen Liang, Wenguan Wang, Tianfei Zhou, Jiaxu Miao, Yawei Luo, and Yi Yang
来源:2022 Computer Vision and Pattern Recognition (CVPR)
原文链接:https://arxiv.org/abs/2203.09773
代码链接:https://github.com/leonnnop/Locater
2. 摘要
我们探索语言引导的视频分割(LVS)的任务。以前的算法大多采用3D CNNs来学习视频表示,难以捕捉长时间的语境,并且容易遭受视觉-语言错位。有鉴于此,我们提出了LOCATER (local-global context aware Transformer),它用有限的内存扩充了Transformer的体系结构,从而以高效的方式用语言表达式查询整个视频。
该存储器设计为包含两个组件:一个用于永久保存全局视频内容,另一个用于动态收集局部时间语境和分段历史。
基于记忆的局部-全局语境和每一帧的特定内容,LOCATER整体地和灵活地将该表达理解为每一帧的自适应查询向量。该向量用于查询相应的帧以生成掩码。该内存还允许LOCATER以线性时间复杂度和恒定大小的内存处理视频,而变压器式的自我关注计算与序列长度成二次方比例。
彻底检查LVS的视觉接地能力模型,我们贡献了一个新的LVS数据集,A2D-S+,它建立在A2D-S数据集之上,但在相似对象中消除歧义中提出了更多的挑战。在三个LVS数据集和我们的A2D-S+上的实验表明,LOCATER取得了SOTA效果。此外,我们基于LOCATER的解决方案在第三届大规模视频对象分割挑战赛的视频对象分割竞赛中获得了第一名。
3. 算法分析
如图1所示是作者提出的LOCATER视频分割模型,LOCATER首先利用自注意力机制,通过帧内视觉语境和语言来增强每帧表征。为了进一步将时间线索纳入每帧表征,LOCATER构建了一个外部有限记忆,它编码多时间尺度的语境,并基于注意力操作进行内容检索。这使得LOCATER成为一个基于完全注意力的模型,同时大大减少了空间和计算的复杂性。
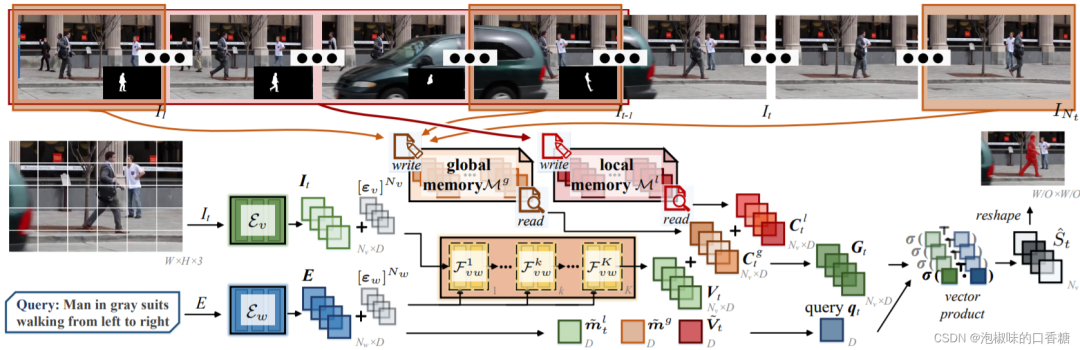
图1 LOCATER视频分割实例
特别的是,LOCATER存储器有两个组成部分:
(1) 持久地记忆全局时间语境,即从视频的整个跨度上采样的帧中总结的高度紧凑的描述符;
(2) 从过去的分割帧中在线收集局部时间语境和分割历史。全局存储器在整个分割过程中保持不变,而局部存储器随着分割过程而动态更新。
因此,LOCATER获得了对视频内容的整体理解,并捕捉到时间的连贯性,从而导致情境化的视觉表征学习。根据存储的语境和一个框架的特定内容,LOCATER通过自适应地关注信息词来生动地解释表达,并形成特别适合该框架的表达性查询向量。该特定查询向量然后被用于查询相应的语境化视觉特征以进行掩码解码。利用这样的存储器设计,LOCATER能够全面地模拟时间依赖性和交叉依赖性
作者的主要贡献有以下三点:
(1) 作者提出了试点工作,基于Transformer建立LOCATER模型,实现LVS任务的记忆增强。并且其中的有限记忆、渐进跨模态融合、情境化查询嵌入、深度监督几个模块极大地促进了网络学习,并最终实现了SOTA效果。
(2) 有限存储器使得网络能够长期存储和提取跨模态语境,同时摆脱了Transformer中传统注意力机制的二次复杂度所带来的难以负担的空间和计算成本。
(3) 通过引入更难合成的数据集,减少了当前最流行的LVS基准(A2D-S)中过多的琐碎案例。
3.1 局部-全局语境感知Transformer架构
由于二次时间和空间复杂度,传统的Transformer网络很难直接应用于LVS任务中。因此作者设计了专门聚焦于LVS和多模态的LOCATER架构,其具有线性复杂度。
对于给定的视频输入和语言表达,LOCATER主要有三个组成部分:
(1) 视觉-语言编码器:逐渐融合语言embedding到视觉embedding中,并对每一帧生成一个语言增强的视觉特征;
(2) 局部-全局记忆:从视觉embedding中收集不同的临时语境,对视觉特征给予语境化表示,并将语言embedding转化成用于Q向量的表达方式。
(3) 参考解码:将语境化特征及Q向量用于分割预测。
3.2 A2D-S+数据集
A2D-S是目前LVS任务中最为重要的数据集之一,但作者发现A2D-S测试集中只包含一个演员,因此跨模态任务往往退化为新对象分割的单模态问题。此外,许多A2D-S视频只包含很少的对象,但具有独特的语义。为了更好地检验LVS模型的视觉基础能力,作者构建了一个更稳健的数据集------A2D-S+。它由三个子集组成,即A2DS+M、A2D-S+~S~和A2D-S+T,它们都建立在A2D-S的基础上,但充分优化了A2D-S的局限性。具体而言,A2D-S+中的每个视频都被选择/创建为包含同一对象或动作类别的多个实例。因此,A2D-S+对LVS模型的分割能力提出了更高的要求。如图2所示是A2D-S+数据集的示例,表1所示是A2D-S+数据集中的统计信息。
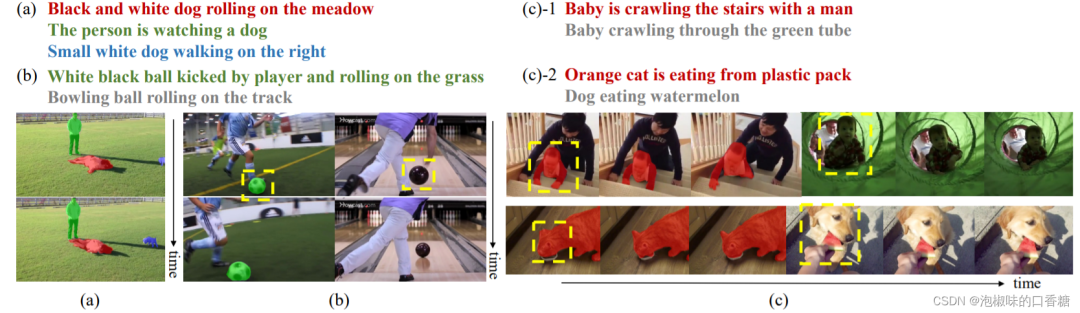
图2 A2D-S+数据集示例
表1 A2D-S+数据集统计信息

4. 实验
作者在实验部分首先在三个标准LVS数据集上测试LOCATER性能,进行定量实验,包括A2D-S、J-HMDB-S以及R-YTVOS。然后在作者提出的A2D-S+数据集上进行试验。最后,介绍LOCATER在第三届大规模视频对象分割挑战赛上的表现和消融实验。
4.1 A2D-S、J-HMDB-S以及R-YTVOS数据集实验
如表2、表3和表4所示为在A2D-S、J-HMDB-S和R-YTVOS数据集上的定量结果。
表2 A2D-S数据集定量结果
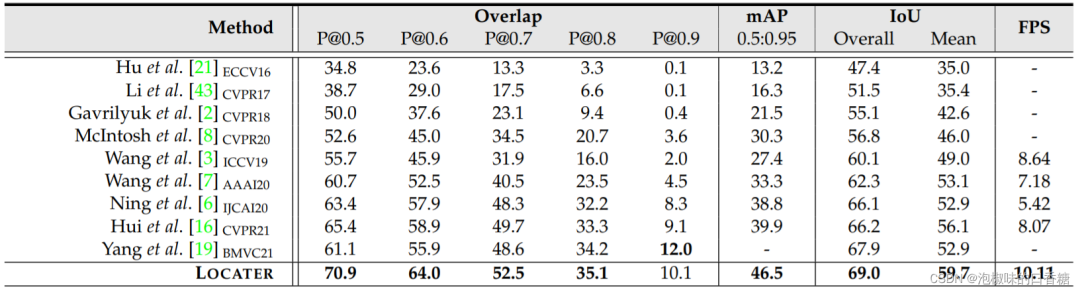
表3 J-HMDB-S数据集定量结果
表4 R-YTVOS数据集定量结果
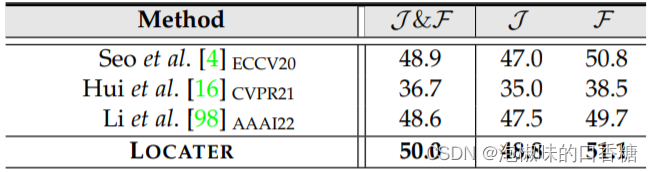
表2中对比了几个主要的基于FCN的视频分割模型,结果显示LOCATER模型比现有的LVS方法快得多,主要原因是其记忆增强的全注意力架构设计。表3显示,LOCATER模型超越了大多数指标上的其他竞争对手。值得注意的是,LOCATER模型平均IoU为66.3%,总IoU为67.3%,mAP为45.6%,而SOTA方法的相应分数分别为62.7%、65.2%和33.5%。
如图3所示为A2D-S测试集和R-YTVOS验证集上的对比结果,LOCATER模型产生了比ACGA和CSTM更精确的分割结果。它在处理遮挡和复杂的文本描述时表现出很强的鲁棒性,尤其是当面对由场景动态引起的模糊。
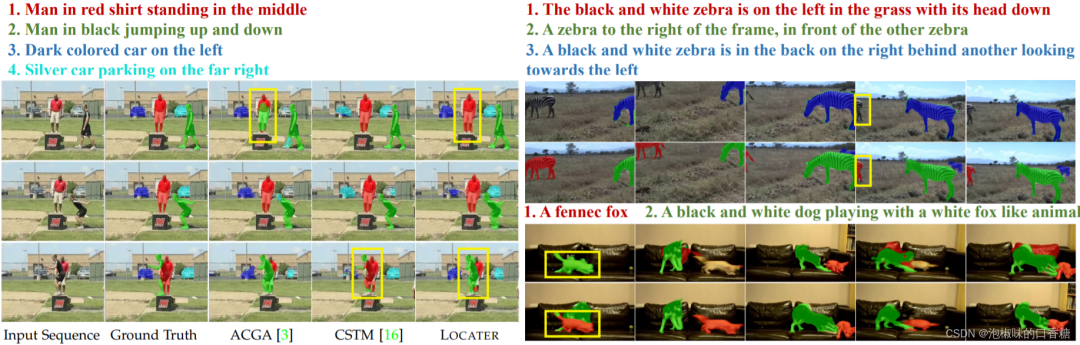
图3 A2D-S测试集和R-YTVOS验证集上的对比结果
4.2 A2D-S+数据集实验及挑战赛结果
表5所示是作者在自己的A2D-S+数据集上的实验结果,虽然其中对比的两大方法在A2D-S和J-HMDB-S数据集上取得了较好性能,但这两个方法很难处理作者提出的A2D-S+数据任务。相比之下,LOCATER模型产生了更好的整体性能,特别是在mIoU上实现了平均3.2%的性能提升,验证了其在以下方面的强大能力和精细的视觉语言理解。
表5 A2D-S+数据集定量结果
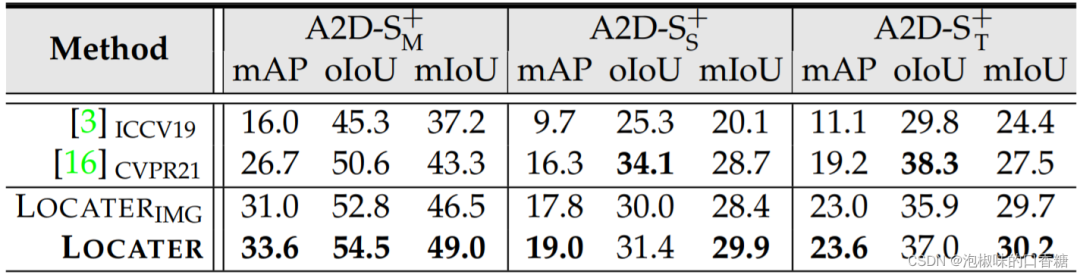
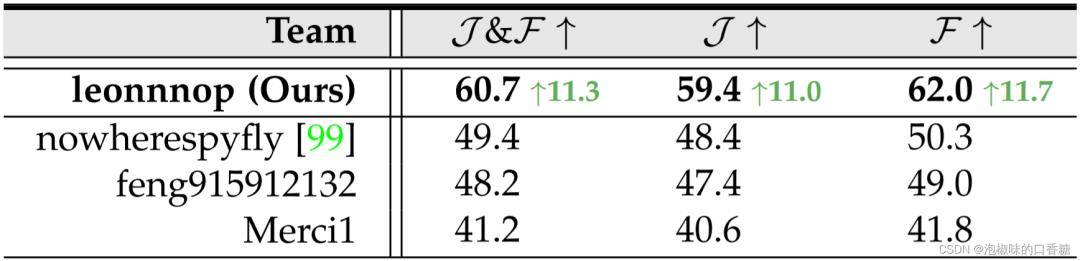
表6所示是作者在YTB-VOS~21~的RVOS跟踪中,LOCATER模型和其他表现最好的团队的最终结果对比。其他竞争者主要采用图像级的参考对象分割策略,简单地用固定的跟踪模块生成视频级的预测。这些方法不仅忽视了语言表达中不可缺少的长期线索,而且忽视了视频序列内在的低层次信息。相比之下,LOCATER模型很好地解决了这些问题。最终,结果明显优于排名第二的解决方案,且差距较大,分别为11.3 %,11.0 %和11.7 %。
表6 视频分割挑战赛中的分割结果对比
4.3 消融实验
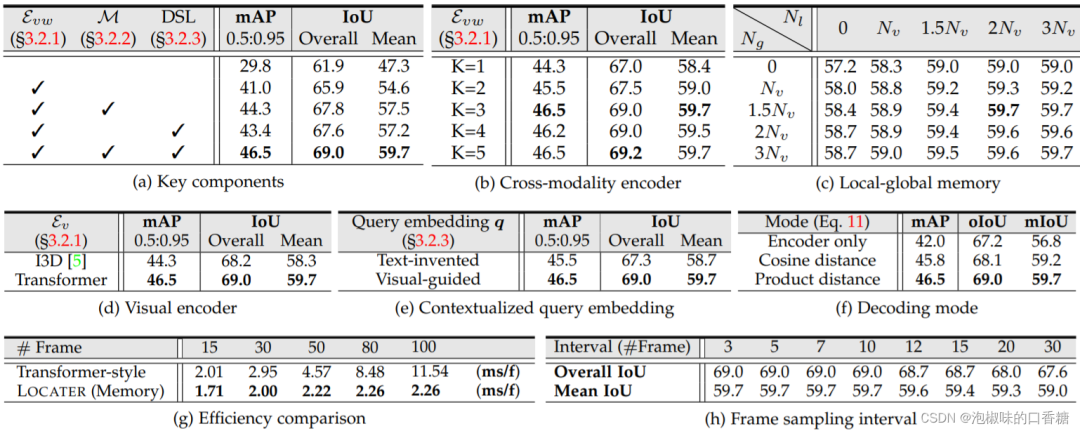
如表7所示,作者为了验证LOCATER模型性能,提出了一系列消融实验。其中分别包括视觉编码器、跨模态编码器、解码器模型、局部-全局记忆、语境Query-Embedding、内存效率以及帧采样间隔。
表7 一系列消融实验
5. 结论
本文带大家精读了2022 CVPR的论文"用于语言引导视频分割的局部-全局语境感知Transformer",这项工作提出了一个基于记忆增强和完全注意模型LOCATER,主要用于LVS任务。LOCATER模型能够有效地对齐跨模态表示,并通过外部存储器有效地模拟长期时间语境以及短期分割历史。通过视觉语境引导的注意力,LOCATER模型产生了特定于帧的查询向量,用于生成掩码,在多项LVS任务中取得了SOTA效果。此外,作者提出了新的A2D-S+数据集,这个数据集缓解了当前最流行的A2D-S数据集中对象的严重缺失问题。
