
LG-Transformer:全局和局部建模Transformer结构新作
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
写在前面
近段时间,基于Transformer的结构在CV领域展现出了很大的应用潜力,已经逐渐掩盖了CNN的光芒。Transformer的缺点也很明显:计算复杂度和输入的特征大小呈平方的关系。因此直接对整张图片进行Self-Attention是不现实的,所以,最近的一些工作(比如Swin-Transformer[1])采用了像CNN一样的分层结构,每层施加注意力的范围只在local window上,逐渐扩大Self-Attention的感知范围。
作者提出,这样的方式存在一定的缺点,因为在前面几个stage中没有对global的特征进行感知,因此,作者就提出了一种多分支的Transformer设计结构,使得Transformer在每个stage中都进同时进行全局和局部的信息感知。通过引入多分支结构,使得模型在分类任务和语义分割任务上都取得了一定的性能提升。
1. 论文和代码地址

论文:https://arxiv.org/abs/2107.04735
代码:https://github.com/ljpadam/LG-Transformer(未开源)
2. Motivation
CNN和Transformer目前是CV任务主要流行的两种结构,这两个结构的主要不同是感知范围不一样:CNN的感受野受卷积核大小的限制,因此CNN的建模范围只能在一个卷积核的感受野之内;Transformer的Self-Attention是做全局信息的建模,因此Self-Attention的感知范围是整张图片。
但是,因为Self-Attention的计算复杂度跟输入特征的大小是呈平方关系的,所以如果图片中的token数量特别大,就会导致计算量的爆炸。所以,目前的Transformer-based的模型大多都将图片的token分成很多局部的window,Self-Attention只在每个window之间进行。
但是,作者提出,这样的结构会使得前面几个stage的建模范围都比较小,不能捕获全局信息,这可能会影响模型的性能。(个人觉得,其实这样attention方式慢慢从局部到整体的一个层次结构可能也比较好的。如果过早的引入了全局的注意力,那就会减弱对CV特征平移等变性这个偏置的利用,从而影响模型的泛化能力。
之前的工作也表明了,加入一些local的建模方式,利用平移等变性这个假设偏置,能够大大提高模型的建模能力。另一方面,在本文中,作者进行全局信息建模的时候,只是将当前特征进行了下采样,这在一定程度上也会对信息造成损失。而Inception结构其实只是用了不同大小的卷积核,并没有进行下采样。所以个人觉得,在这一方面,本文虽然参考了Inception,但是结构设计上可能没有Inception巧妙。)
基于上面的Motivation,作者提出了一个多分支的、多尺度的Self-Attention感知方式。作者将特征进行不同比例的下采样后,再用参数不共享的Self-Attention模块进行建模,因此,下采样比例大的特征感受野更大,下采样比例小的特征感受野比较小,最后将不同分支的输出结构进行融合,就得到了多尺度感知后的特征。

作者在文中指出,本文的结构参考了CNN中同样是多分支的Inception结构(Inception结构如上图所示)。本文的结构如下图所示,作者通过不同比例的下采样,使得本文提出的Local-to-Global Self-Attention结构能够进行不同尺度的信息建模,其中最大感受野的Attention模块能够进行全局的信息建模。
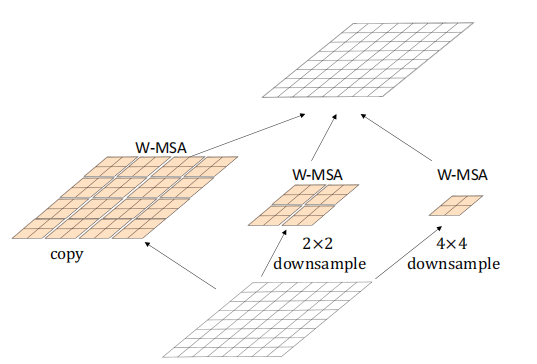
最后,作者在分类任务和语义分割任务上进行了实验,相比于Swin-Transformer,本文提出的LG-Transformer 在ImageNet达到了0.9% Top-1准确率的性能提升,在ADE20K数据集上达到了0.8% mIoU的性能提升。
3. 方法
3.1. Local-to-Global Attention Block
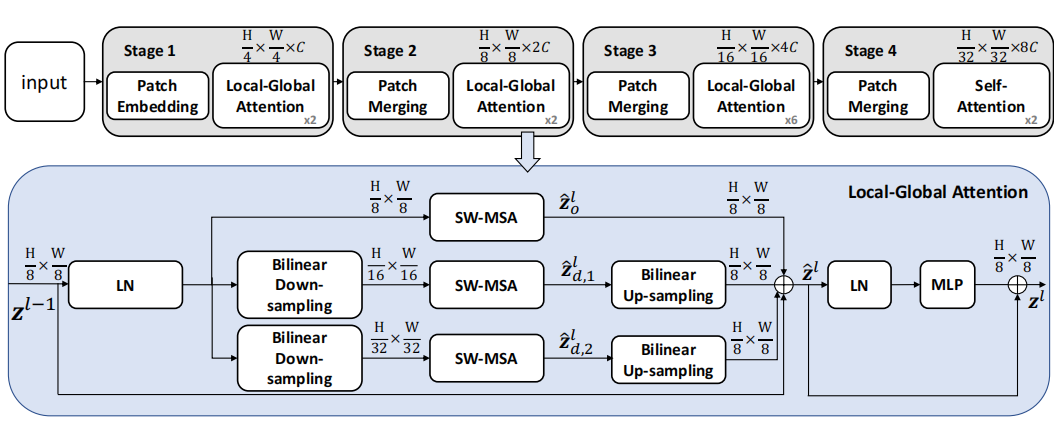
如上图所示,本文提出的LG-Transformer分为四个stage,经过每个stage之后特征的空间维度缩小为原来的一半,通道维度提升为原来的两倍。
LG Attention的注意力模块和Swin-Transformer中的注意力模块相似,不同的是,除了采用了Swin-transformer的Attention模块,作者还将特征进行了不同比例的降采样,然后将不同比例降采样之后的特征放入不同分支的attention模块进行计算,并将计算得出的特征进行上采样,使得输出特征的大小和原来输入特征的大小一样。
最后将多分支的输出进行融合,就得到了施加多尺度注意力后的结果。在施加attention机制之后,跟其他Transformer结构一样,作者在后面继续加了一个MLP结构,进行通道信息的交互。用公式表示如下:
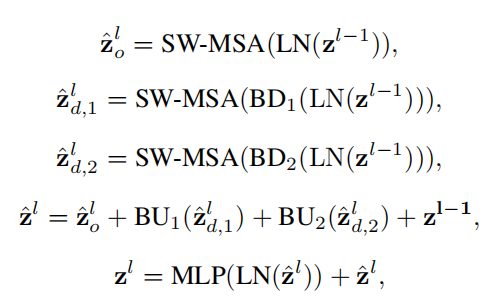
3.2. Computational Complexity
由于本文提出的LG-atttention模块比Swin-Transformer的SW-MSA模块多了降采样后的特征的attention计算,因此本文的LG-Attention计算量比SW-MSA稍微多一些,具体的计算量如下面的公式所示:
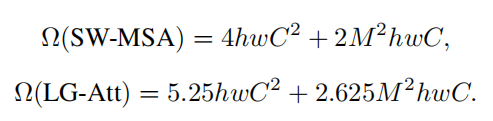
3.3. Architecture Variants
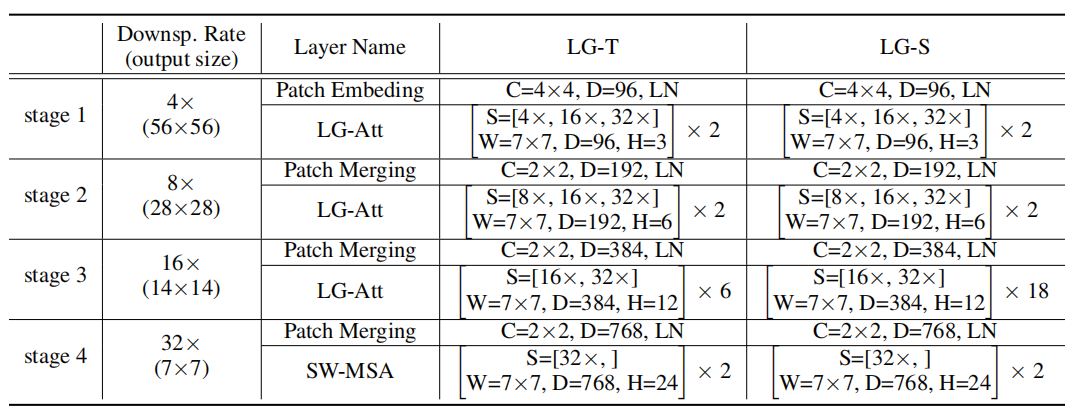
基于LG-Attention,作者提出了两种有不同计算量和参数量的LG Transformer,具体的配置如上表所示。
4.实验
4.1. Image Classification
4.1.1. Comparative Results
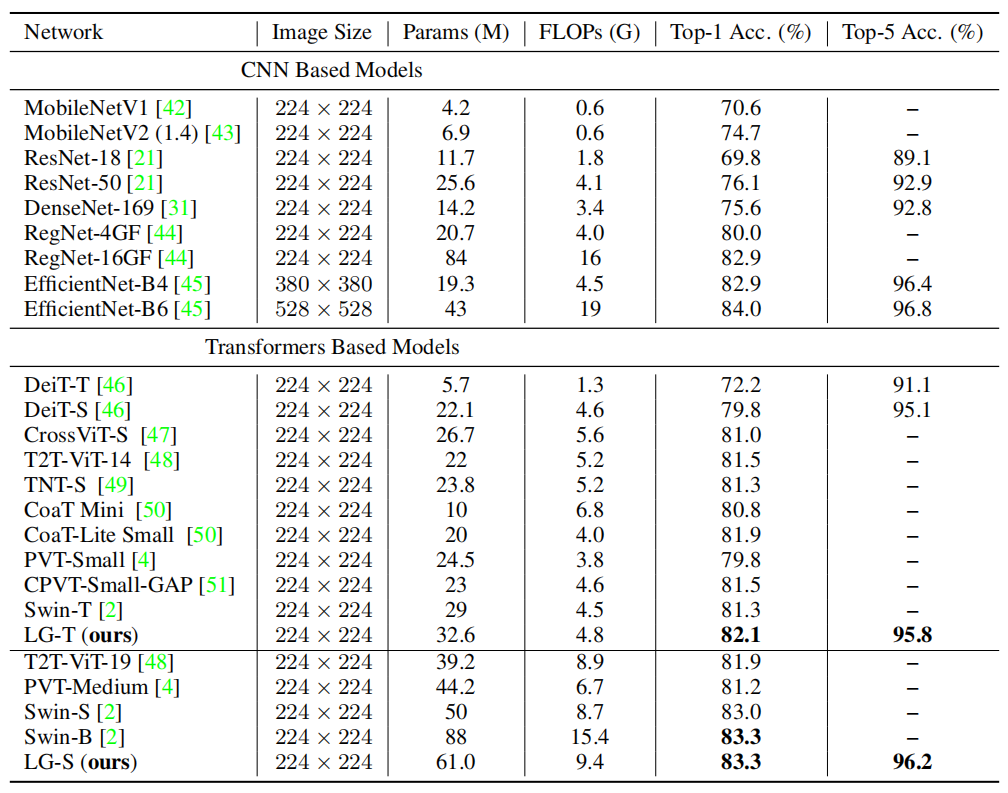
上表展示本文的LG Transformer和其他SOTA模型的性能对比。可以看出,在相似的计算量下,LG-T比Swin-T高了0.8%,比PVT-Small高了2.3%。LG-S在参数量和计算量都比Swin-B小的情况下,达到了相同的performance。
4.1.2. Ablation Studies
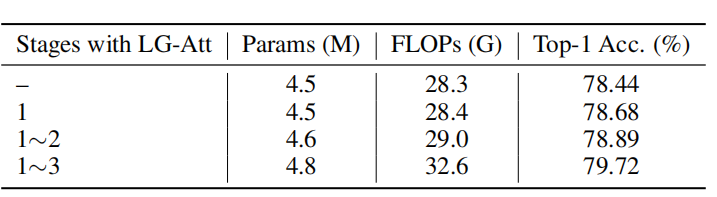
从上表可以看出,在不同的stage上加入LG-Attention,模型的performance也是不一样的,LG-Attention加的越多,参数量和计算量也越大。在1-3stage中都加入LG-Attention效果最好。
4.1.3. Qualitative Results
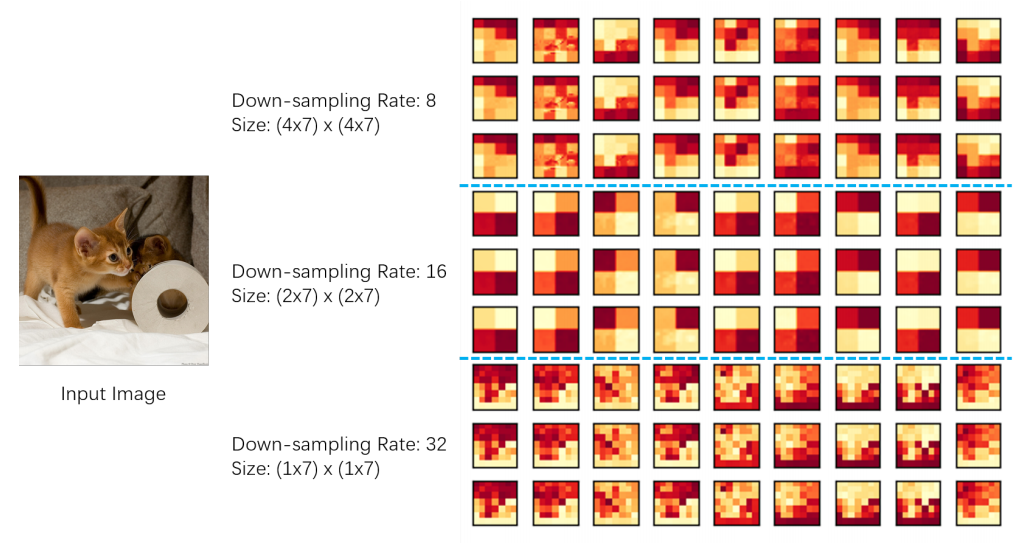
上图展示了三个层次的特征图,下采样率为8(局部关注)、16(中等关注)和32(全局关注)。可以看出,在下采样率为8和16的特征图中,跨局部attention窗口的边界存在明显的不连续性,显示了局部注意力的局限性。
4.2. Semantic Segmentation
4.2.1. Results Analysis
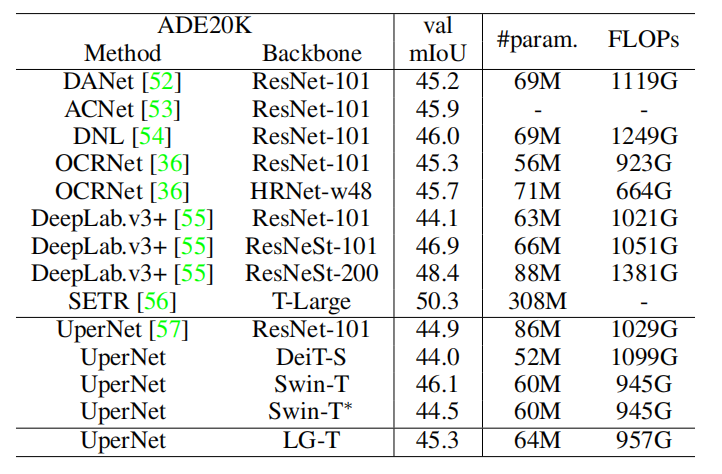
在语义分割任务上,在相似的计算量下,本文提出的LG-T比ResNet-101,DeiT-S,Swin-T性能更好。
5. 总结
首先,这篇文章的Motivation非常明确,就是希望在前面的stage中也能加入全局的信息感知,所以作者引入了多分支结构,有的分支用来捕获全局的注意力(先降采样),有的分支用来捕获局部注意力,相当于是在Transformer中采用了一个类似Inception的结构。
个人觉得,这样的改法比较straightforward,并且也引入了额外的计算量和参数量,所以从网络结构上看起来不是非常惊艳。
除此之外,与之前的HaloNet[2]相比 ,本文的性能也没有非常惊艳,因此,个人认为,这样的结构对于解决这个motivation,可能并不是一个最优解。
参考文献
[1]. Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." arXiv preprint arXiv:2103.14030 (2021).
[2]. Vaswani, Ashish, et al. "Scaling local self-attention for parameter efficient visual backbones." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看