
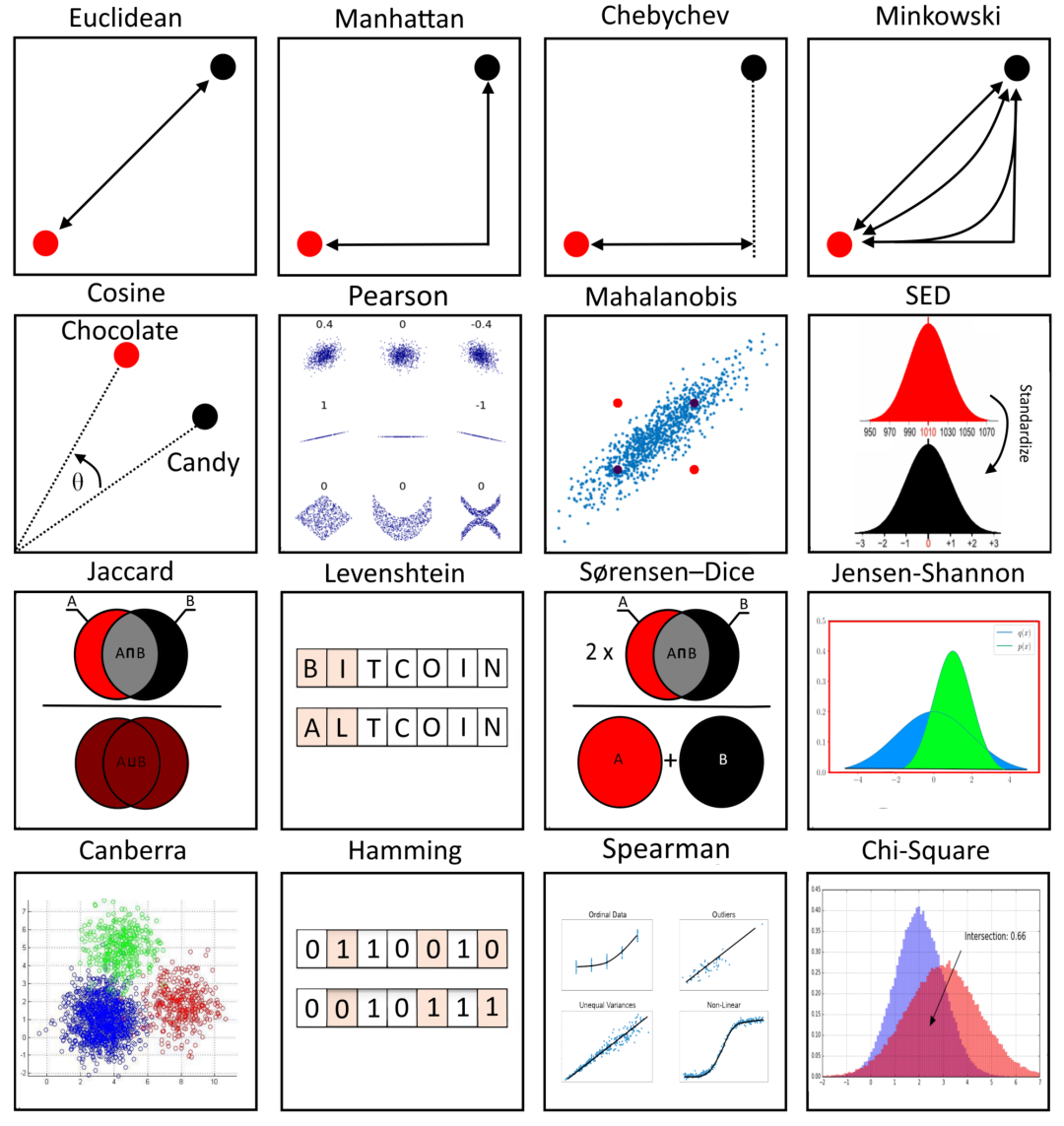
数据科学中 17 种相似性和相异性度量
"There is no Royal Road to Geometry."—欧几里得
🄰 . 简介
相似性和相异性
指标
2 - 对称性: 对于所有 和 。
3 - 三角不等式: 对于所有 。
4 - 仅当 时。
🄱 . 距离函数
⓪ L2范数,欧几里得距离
n 维空间中两点之间的欧几里德距离
二维空间中两点之间的欧几里德距离。


KNN 算法,该算法使用欧几里德距离对数据进行分类。为了演示 KNN 如何使用欧几里德度量,我们选择了一个 Scipy 包的流行 iris 数据集。Iris-Setosa、Iris-Versicolor 和 Iris-Virginica,并具有以下四个特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度。因此就有一个 4 维空间,在其中表示每个数据点。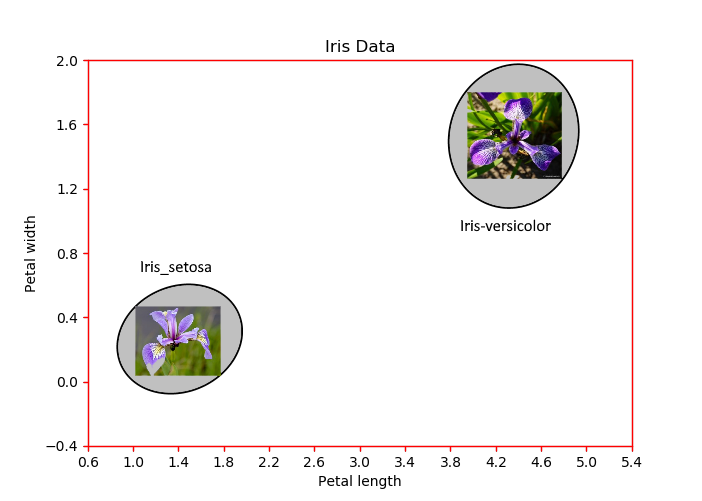
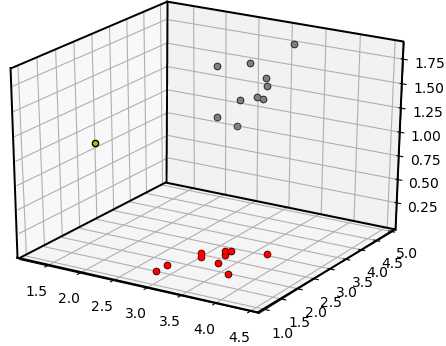
Iris-virginica 数据。通过这种方式,我们可以在二维空间中绘制数据点,其中 x 轴和 y 轴分别表示花瓣长度和花瓣宽度。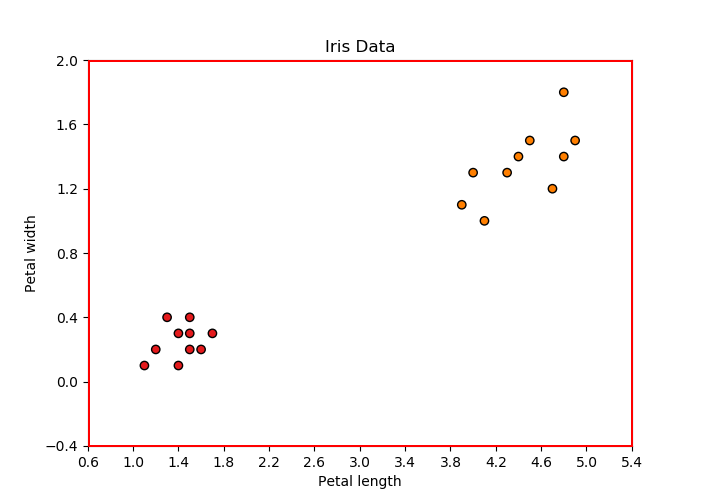
Iris-Setosa 或 Iris-versicolor(数据集中的 0 和 1)。因此,该数据集可用于 KNN 分类,因为它本质上是一种有监督的 ML 算法。假设我们的 ML 模型(k = 4 的 KNN)已经在这个数据集上进行了训练,我们选择了两个输入特征只有 20 个数据点,如上图所示。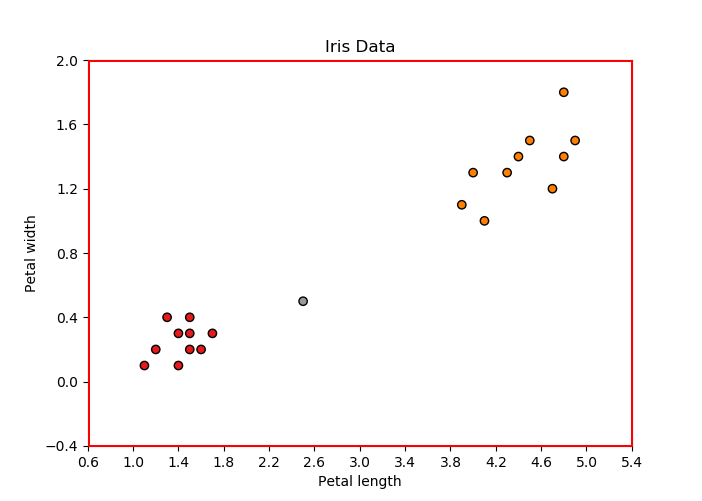
Iris-Setosa 或 Iris-versicolor。至此,新数据点到我们训练数据的每个点的欧几里德距离都计算出来了,如下图所示:
k = 4时,KNN分类器需要选择最小的四个距离,代表新点到以下点的距离:point1、point5、point8和point9,如图所示: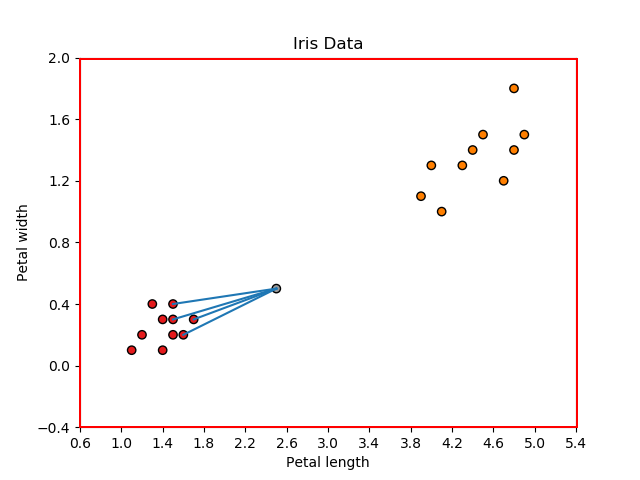
Iris-Setosa。使用这个类比,可以想象更高的维度和其他分类器。➀ 平方欧几里得距离
② L1 范数、城市街区、曼哈顿或出租车距离


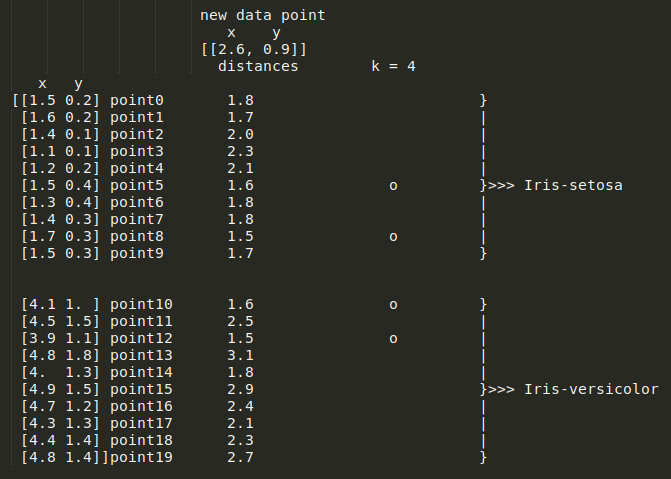
Iris-Setosa,另外两个数据点投票支持 Iris-versicolor,这意味着这是个平局。
k=4,将其更改为 k=3将导致以下值:
k=5 将导致以下值:
Iris-Setosa。因此,由你决定是否需要增加或减少 k 的值。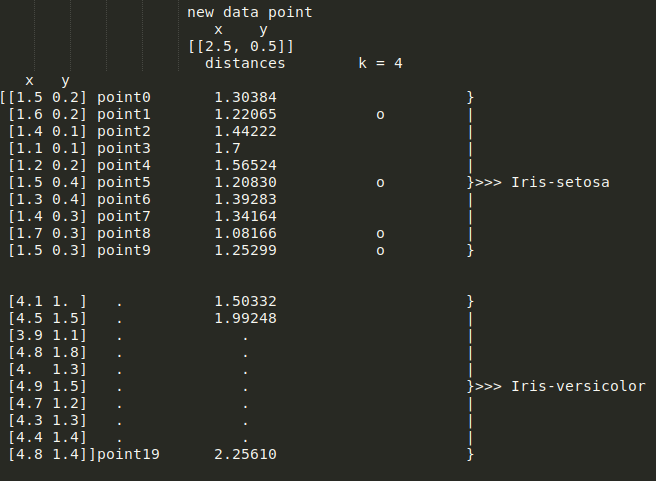
Iris-Setosa。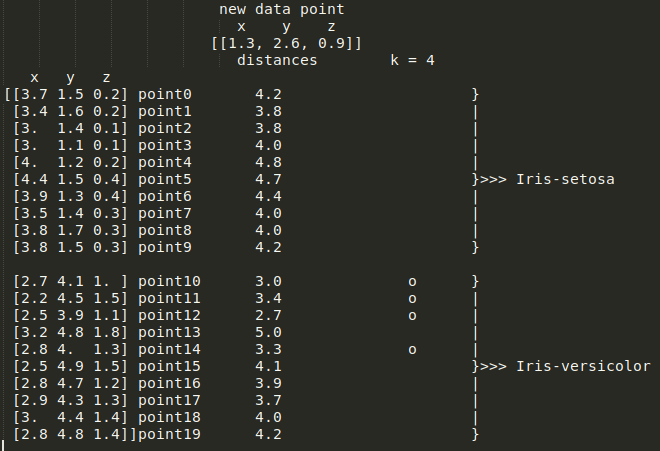
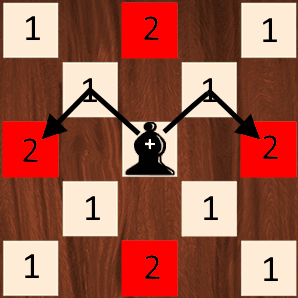
Bishop 使用曼哈顿距离(如果没有看到,可通过将棋盘旋转 45° 来想象一下)。换句话说,让主教越过红色方块所需的移动次数(距离)等于曼哈顿距离,即 2。L1-norm 比 l2-norm 给出更稀疏的估计。除此之外,L1 范数和L2 范数通常用于神经网络的正则化,以最小化权重或将某些值归零,就像套索回归中使用的那样。
③ 堪培拉距离
④ L∞ 范数,切比雪夫距离,最大距离

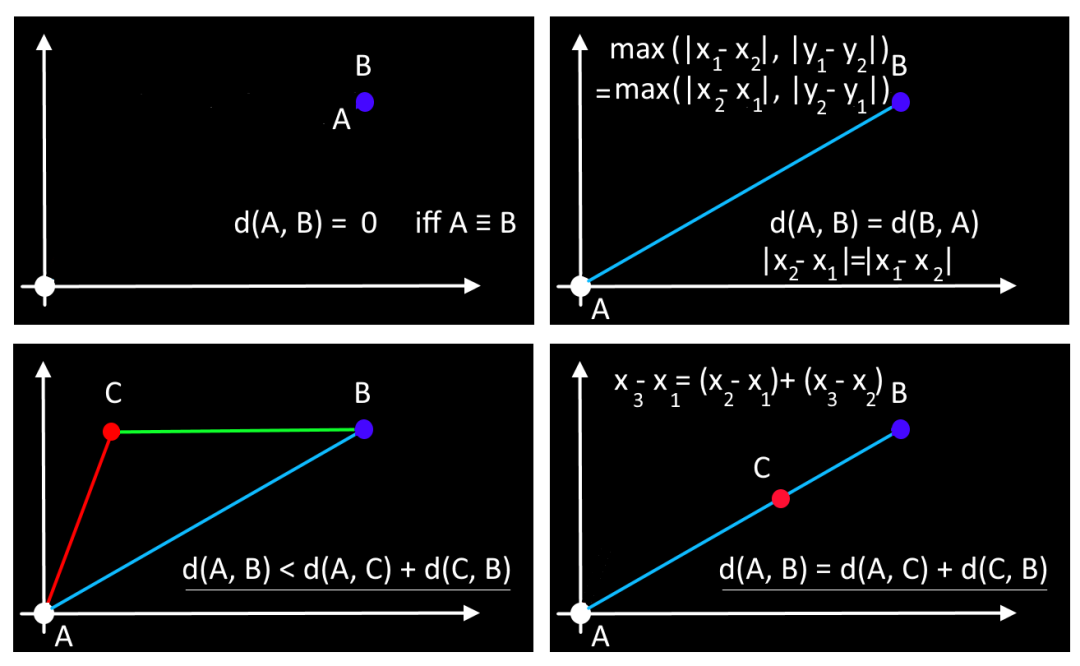



⑤ Lp 范数,闵可夫斯基距离

p = 1: 曼哈顿距离。 p = 2: 欧几里得距离。 p → +∞ : 切比雪夫距离,逻辑或(点 D = A或B = 1或1 = 1)。 p → 0: 逻辑与(点 C = A AND B = 零)。 p → -∞ : 最小距离(点 D 的对称性)。
⑥余弦距离
文件A: "I love to drink coffee in the morning." 文件B: "I like to drink coffee." 文件C: "My friend and I work at a coffee shop in our hometown. He tells some good jokes in the morning. We like to begin the day by drink a cup of tea each."

“I love to drink coffee” 然而,文件 C 包含文件 A 的所有单词,但从频率表中的含义非常不同。为了解决这个问题,你需要计算余弦相似度来判断它们是否相似。文件 A: "Bitcoin Bitcoin Bitcoin Money" 文件 B: "Money Money Bitcoin Bitcoin"
“Bitcoin”这个词作为 x 轴,把“Money”这个词作为 y 轴。这意味着文档 A 可以表示为向量 A(3,1),文档 B 可以表示为 B(2,2)。0.894 并不意味着文档 A 是 89.4%,与 B 相似。它意味着文档 A 和 B 非常相似,但我们不知道有多少百分比!该值没有阈值。换句话说,你可以将余弦相似度的值解释如下:它越大,文档 A 和 B 相似的可能性就越大,反之亦然。
A(1, 11) 和 B(22, 3) 的例子22.4,这并不能说明向量之间的相对相似性。另一方面,余弦相似度也适用于更高维度。参考资料
参考原文: https://towardsdatascience.com/17-types-of-similarity-and-dissimilarity-measures-used-in-data-science-3eb914d2681
[2]计算机安全: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.97.2974&rep=rep1&type=pdf
[3]OpenPose: https://github.com/CMU-Perceptual-Computing-Lab/openpose

推荐阅读
欢迎长按扫码关注「数据管道」
评论