
python爬取二次元肥宅最喜欢的壁纸图片,看过的都说爱了

前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
注:某憨批朋友发来的一个网址
其实这个网站的壁纸 还是不错的嘛,果然是二次元肥宅的最爱~



所以… 爬它
相关python开发工具
Python 3.6
Pycharm
requests
parsel
相关模块pip安装即可
安装速度慢可以使用镜像源安装
以前发过解决pip安装速度慢的问题
一、获取详情页url地址以及标题
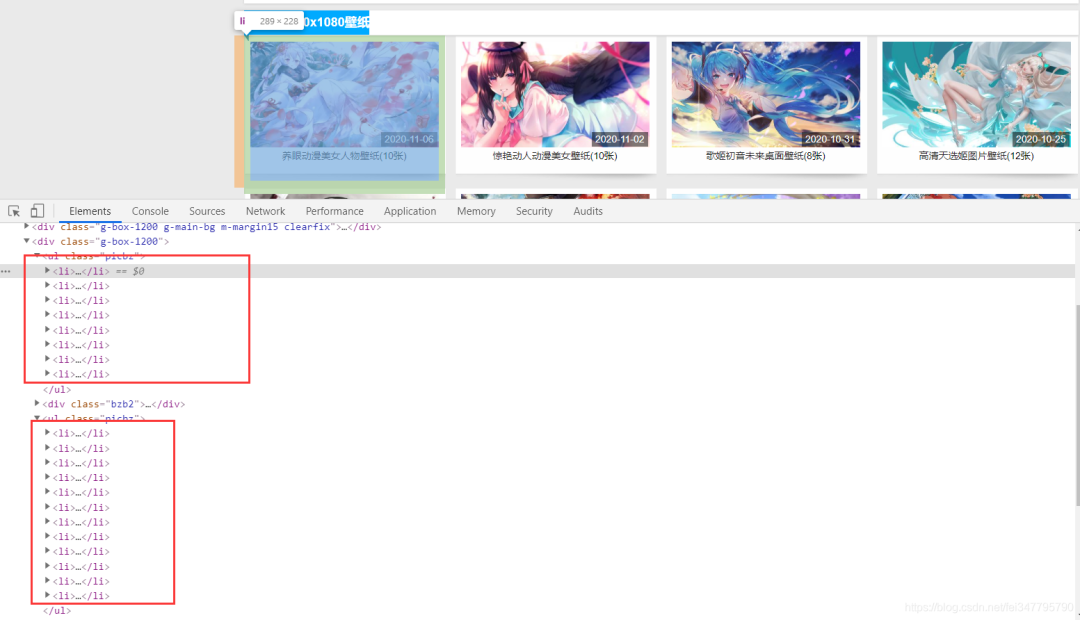
图片详情页是在 ul 标签里面的 li 标签下面的

所以只需要请求网址,网站是静态页面可以直接获取网页数据,但是网页文字是乱码,转码即可。。
关于动漫类一共是16页数据
'''
# 第一页链接
http://www.jj20.com/bz/ktmh/list_16_cc_14_1.html
# 第二页链接
http://www.jj20.com/bz/ktmh/list_16_cc_14_2.html
# 第三页链接
http://www.jj20.com/bz/ktmh/list_16_cc_14_2.html
'''
根据页码的改变对应的是第几页。
一般情况如果想要找到翻页的效果,是需要从第二页开始找的。
上述是已经找到答案的情况,但是实际情况你第一页的url是有所不同的
http://www.jj20.com/bz/ktmh/list_16_cc_14.html
实际上第一页url是没有页面参数的,只有到了第二页的时候才会有页码参数,然后你可以看第三页的url变化,就可以对比发现规则,然后根据规则拼接第一页的url地址,看是否也可以访问,如果可以,那么翻页规律就找到,如果不可以,那就要根据实际情况再作分析了。
import requests
import parsel
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
for page in range(1, 17):
url = 'http://www.jj20.com/bz/ktmh/list_16_cc_14_{}.html'.format(page)
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('body > div:nth-child(7) > ul li')
for li in lis:
page_url = 'http://www.jj20.com/' + li.css('a:nth-child(1)::attr(href)').get()
title = li.css('a:nth-child(1) img::attr(alt)').get()
二、获取壁纸原图地址
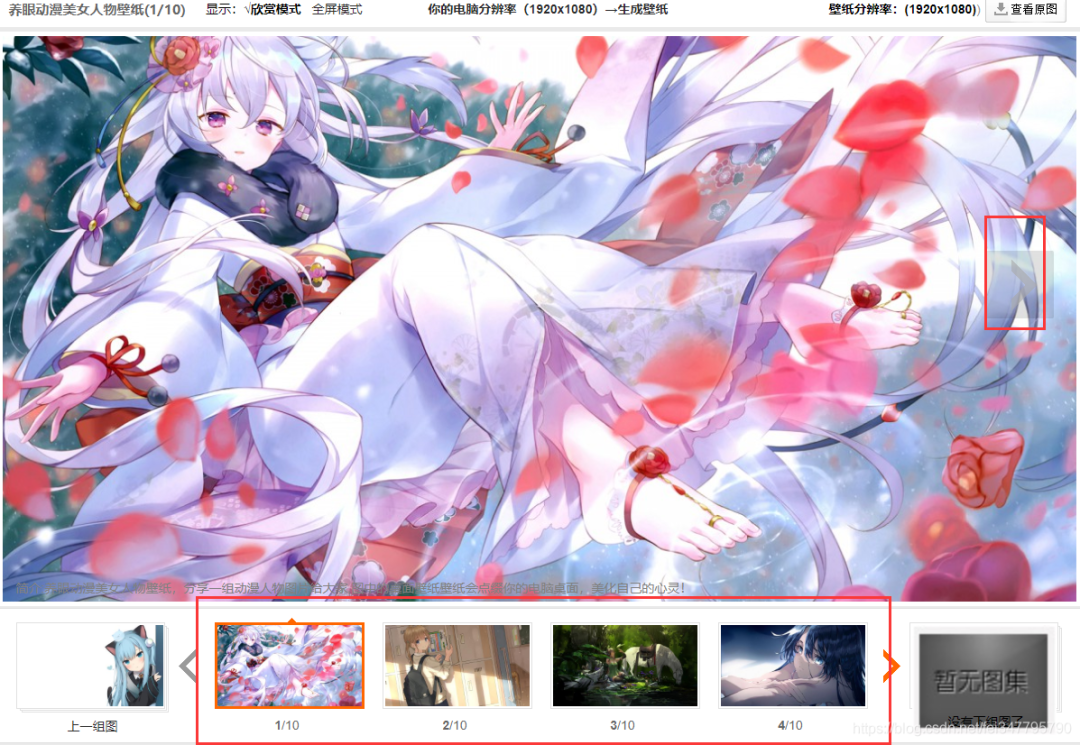
详情页中如果想要看下一张图片地址,则是需要点击下一张,下面也有其余壁纸的轮播
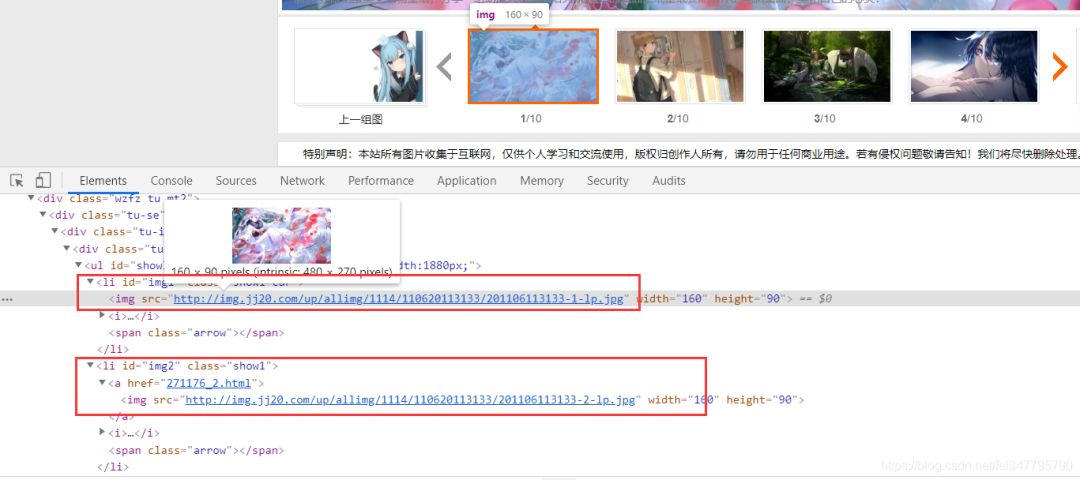
通过开发者工具可以看到,10张图片壁纸的地址也都是在 li 标签里面的,复制链接看一下是否是原图

果然不出意外,真的是缩略图。
那就点击下载原图看一下,原图地址是什么样的。
'''
# 原图地址
http://cj.jj20.com/2020/down.html?picurl=/up/allimg/1114/110620113133/201106113133-1.jpg
# li标签里面的地址
http://img.jj20.com/up/allimg/1114/110620113133/201106113133-1-lp.jpg
'''
1、拼接url地址就可以了
http://cj.jj20.com/2020/down.html?picurl= + up/allimg/1114/110620113133/201106113133-1.jpg
2、如果你可以自己试一下把 -lp 一样可以
http://img.jj20.com/up/allimg/1114/110620113133/201106113133-1.jpg
def get_img(page_url, title):
page_url_response = requests.get(url=page_url, headers=headers)
page_url_response.encoding = page_url_response.apparent_encoding
page_url_selector = parsel.Selector(page_url_response.text)
lis_2 = selector.css('#showImg li img::attr(src)').getall()
for i in lis_2:
# 原图壁纸地址
# http://pic.jj20.com/up/allimg/1114/110620113133/201106113133-1.jpg
# li标签壁纸地址
# http://img.jj20.com/up/allimg/1114/110620113133/201106113133-1-lp.jpg
img_url = i.replace('-lp.jpg', '.jpg')
img_title = title + img_url.split('-')[-1]
三、保存壁纸图片
保存没什么特别要说的,都是常规操作,固定写法了。图片、视频、音频都是二进制文件,用wb的方式写入就可以了。
def download(img_url, img_title):
path = 'img\\' + img_title
img_url_response = requests.get(url=img_url, headers=headers)
with open(path, mode='wb') as f:
f.write(img_url_response.content)
print(img_url, img_title)
四、实现效果
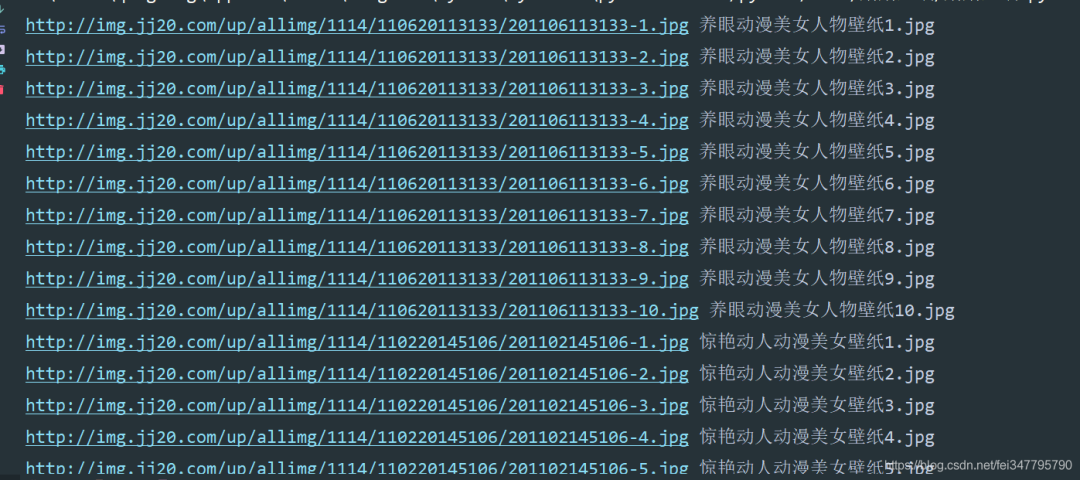
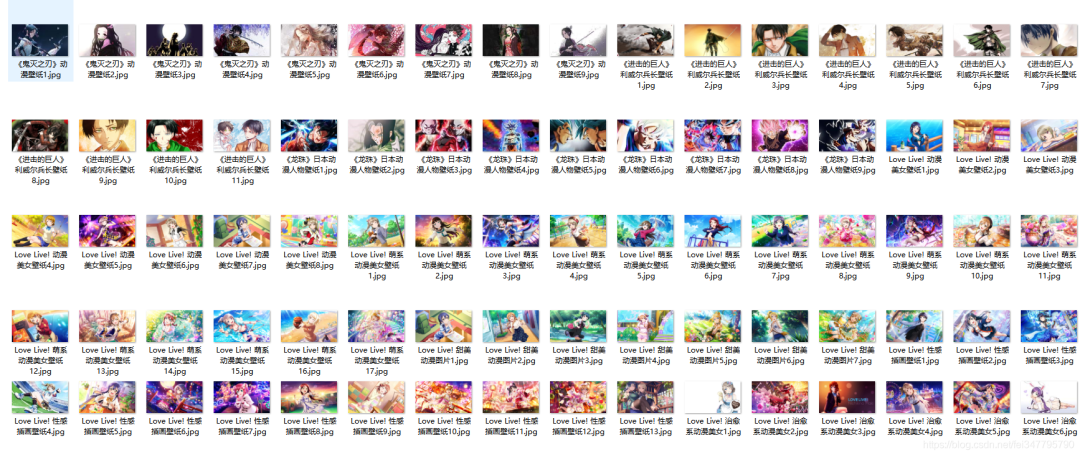
没有爬完所有的,就爬了1000多张,有点占地方,主要是演示一下。

扫下方二维码加老师微信
或是搜索老师微信号:XTUOL1988【切记备注:学习Python】
领取Python web开发,Python爬虫,Python数据分析,人工智能等学习教程。带你从零基础系统性的学好Python!
也可以加老师建的Python技术学习教程qq裙:245345507,二者加一个就可以!

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
万水千山总是情,点个【在看】行不行
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜