
用Python爬取Bilibili上二次元妹子的视频

一直想爬取BiliBili的视频,无奈一直没有去研究一下。
最近,在旭哥的指点之下,用了Fiddler抓包,抓到了一直期待的视频包,完成了下载。
下面写一下我做这个爬虫的过程。
# 相关依赖 :Fiddler+Python3 + Requests
下面看一下我做这个爬虫的具体步骤:
1. 进入某个具体视频的页面抓取视频包测试。
进入这个页面:https://www.bilibili.com/video/av26019104,如下图所示。点击播放按钮。
可以看到Fiddler已经抓到了很多包。别着急,现在还没有视频包出现。由于需要时间下载,所以具体视频包会过一会才能弹出来。
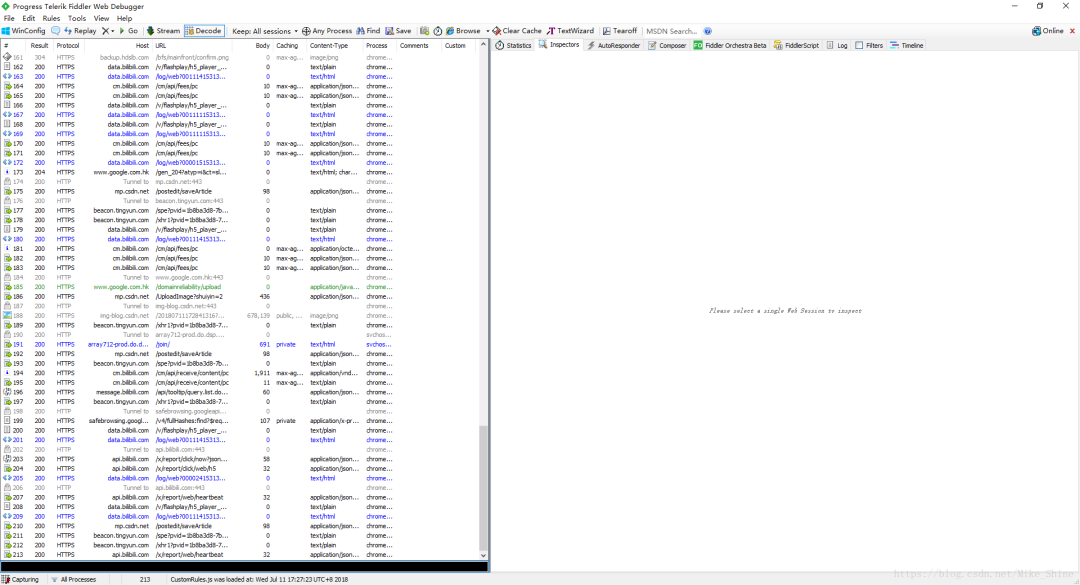
过大概一两分钟,就会看到这个包,如下图。可以清楚的看到这个是Flv形式的视频流的包,看这个包的大小也可以看出来,是相当的大。
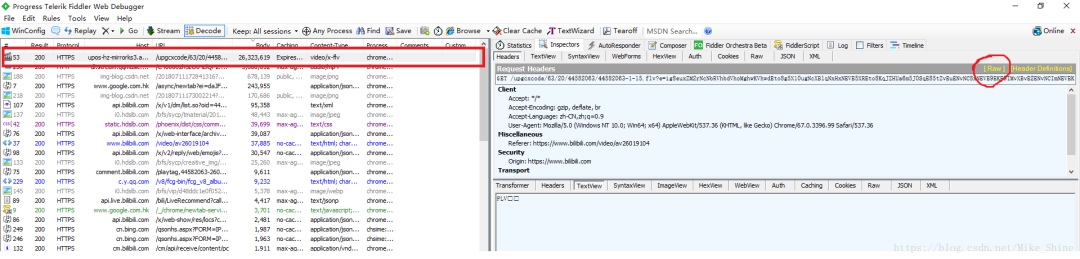
下面分析一下这个包的具体参数。点击上图红色圈圈那个“Raw",会弹出下面这个窗口
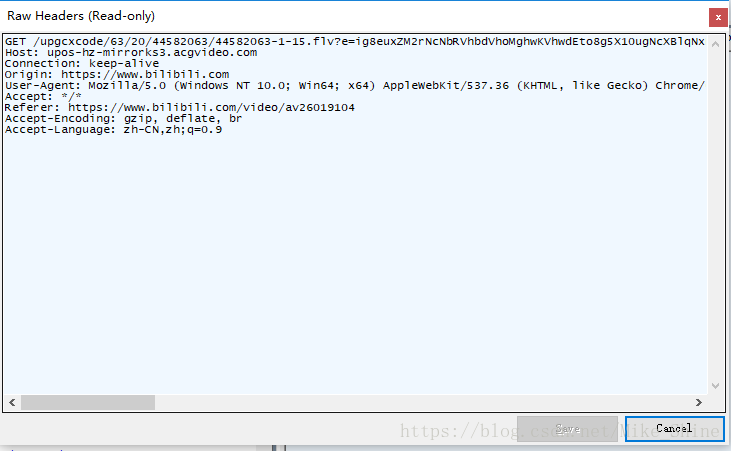
可以看到是一个Get请求,请求的url和Headers都很清楚。
这时候就可以实验一下,来写一小段代码测试一下是否可以通过requests.get()方法来下载视频。
#######################################################################import requestswith open("D:\video\bilibili.mp4") as f:f.write(requests.get(url, headers = headers, verify = False).content) #这里的Verify=False是跳过证书认证print("下载完成") # 这里只是写了核心部分,headers和url没有写,直接copy过来就好了,# 注意Url前面要加Host. 真正的请求地址是http://主机Host地址/upgcx.......############################################################################
可以看到如果你运行这段代码,已经可以把视频下载到了本地。
这里你可以多试几个视频,可能会发现,有些视频按照抓包得到的Headers,请求之后只能Get到一部分视频,比如视频8M,你Get到只有2M。你去看一下Headers就会发现,他多了一个Range参数。把这个删除掉,就可以下载了。
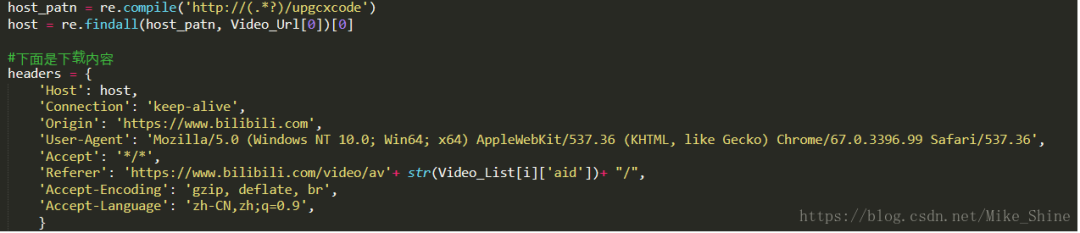
经过我的实验,所有视频请求的Headers格式都可以统一为下图这样。里面有2个参数哈。
1.host,主机名,就是从你爬出来的URL中正则出来的host
2. 视频标号。
2. 获取请求Headers参数和请求源URL:
要找URL,可以看一下URL中的内容,里面的hfa=xxxxxxxx和hfb=xxxxxxx应该是加密的?这可怎么办。这时候用Fiddler,从抓来的包里搜索一下这两个参数,肯定藏在某个包里。用CTRL + F 输入hfa 搜索。可以看到包含HFA关键字的包都被找出来了。
进去一看,其实包含在网页源代码的包,也就是说URL中的参数包含在网页源代码里。
回到最初的那个视频页面,看一下网页源代码。搜索一下URL。
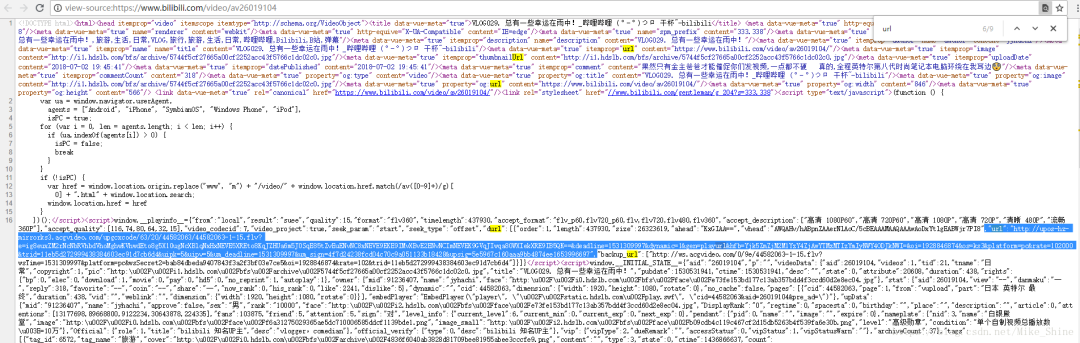
惊喜的发现,其实整个URL都在网页源码里。这岂不是太简单了。
不过需要注意的是,这个URL中含有的hfa等加密部分是会动态变化的。所以在最终脚本的代码结构中,需要拿一个URL,及时用来做get请求。下载完成之后再拿下一个URL。
我之前就犯过这样的错,由于URL过期,导致部分视频下载不到。
3. 从UP主的主页爬取所有视频的信息(视频编号,标题)。
在之前的实验之上,现在只要有视频编号,我们就可以下载到对应的视频了。所以接下来要做的工作就是从Up主的主页来获取所有的视频信息。
访问某个Up主的主页
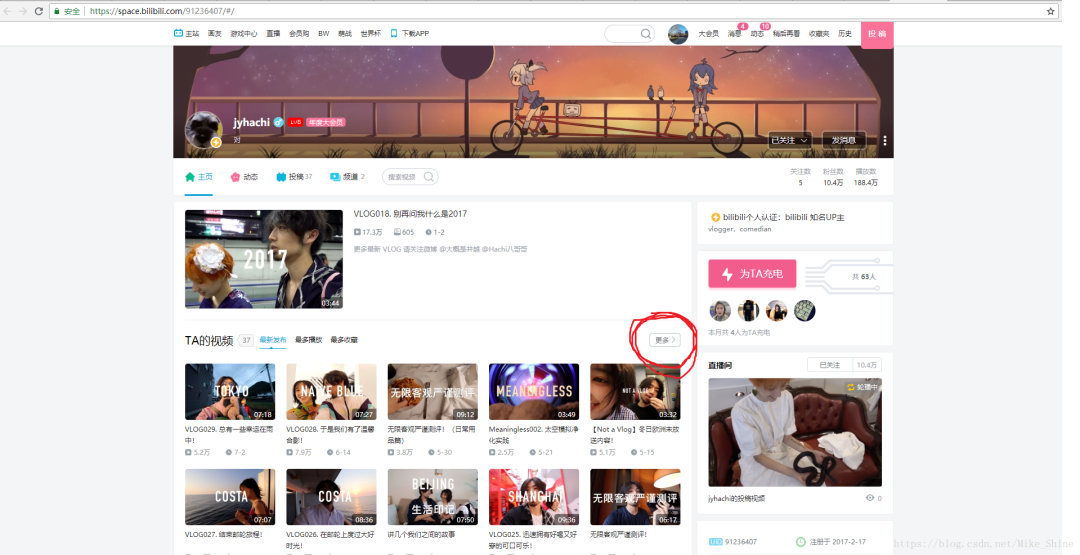
点击圈圈的更多,可以进入所有视频的页面。
这时候看Filddler抓包的结果,看到这个json包,里面包含了本页所有视频的信息。
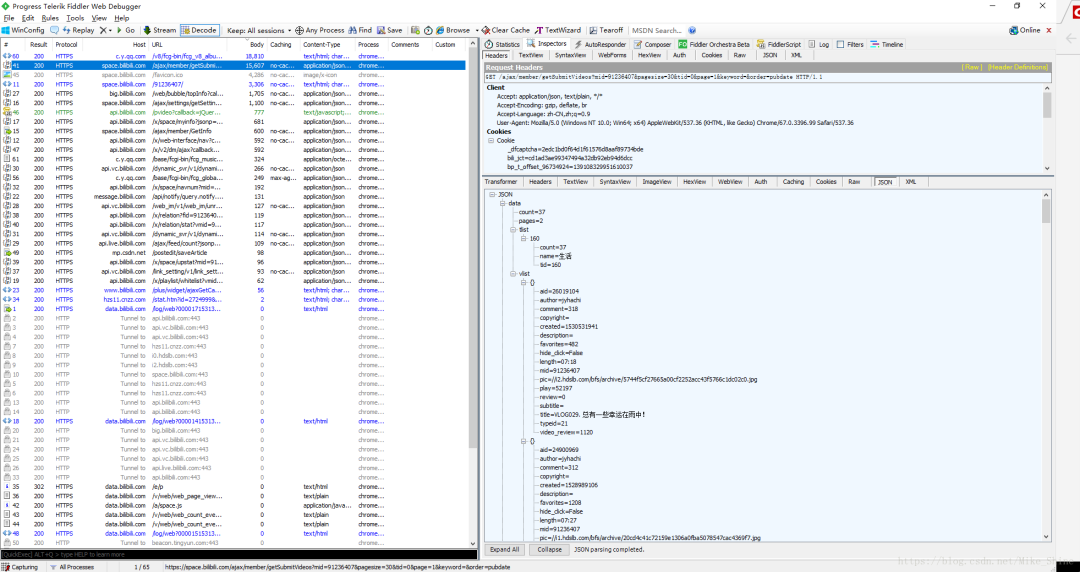
同样,看一下包头。如下图
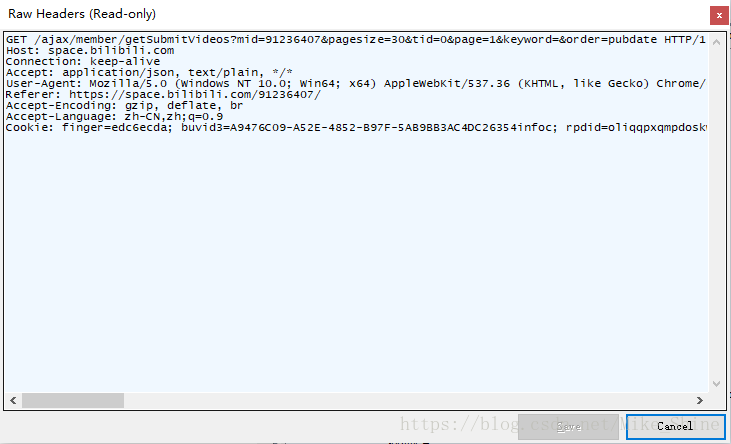
也做一下实验,可以发现Cookie是不必须的参数。
同之前下载视频的Get方法,同样可以Get到这个Json包。然后就可以把内容通过Json解析的语句拿出来。
这里我并没有做翻页的工作,而是直接请求了100个视频。想做翻页的同学,加一点代码就好了。
评论