
Python爬虫实战 | 利用多线程爬取 LOL 高清壁纸
来源:公众号【杰哥的IT之旅】
作者:阿拉斯加
ID:Jake_Internet
如需获取本文完整代码及 LOL 壁纸,请为本文右下角点亮在看并添加杰哥微信:Hc220088 获取。
一、背景介绍
随着移动端的普及出现了很多的移动 APP,应用软件也随之流行起来。最近看到英雄联盟的手游上线了,感觉还行,PC 端英雄联盟可谓是爆火的游戏,不知道移动端的英雄联盟前途如何,那今天我们使用到多线程的方式爬取 LOL 官网英雄高清壁纸。
二、页面分析
目标网站:
https://lol.qq.com/data/info-heros.shtml#Navi
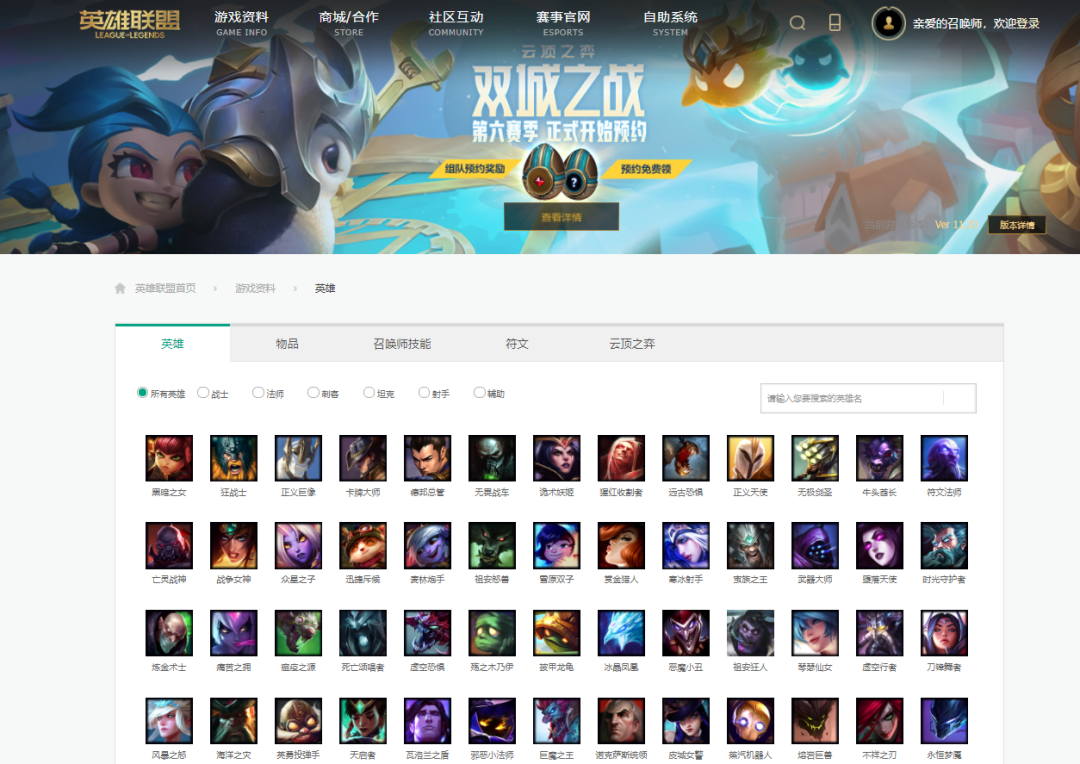
官网界面如图所示,显而易见,一个小图表示一个英雄,我们的目的是爬取每一个英雄的所有皮肤图片,全部下载下来并保存到本地。
次级页面
上面的页面我们称为主页面,次级页面也就是每一个英雄对应的页面,就以黑暗之女为例,它的次级页面如下所示:
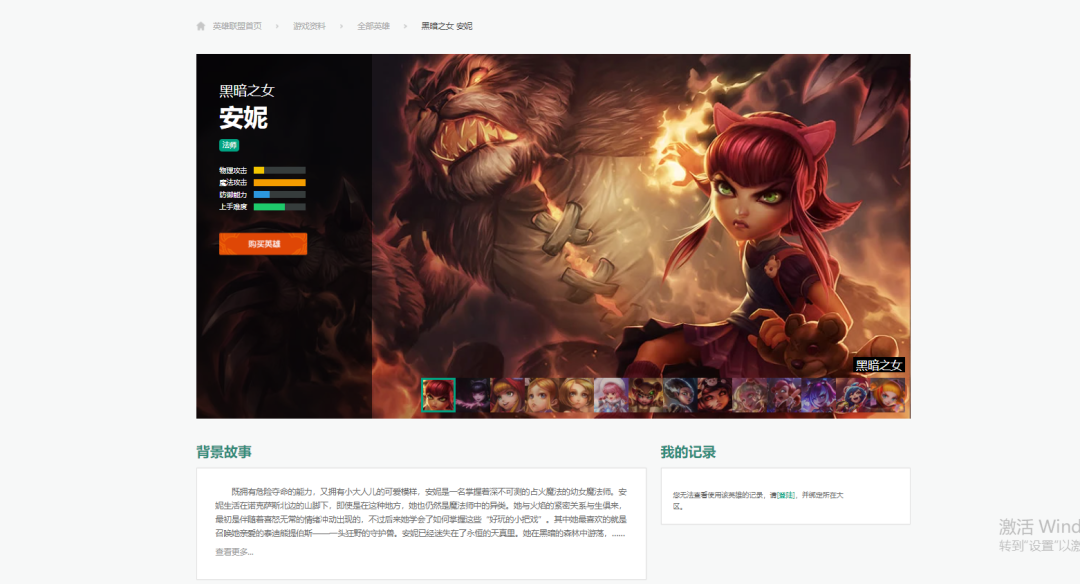
我们可以看到有很多的小图,每一张小图对应一个皮肤,通过 network 查看皮肤数据接口,如下图所示:
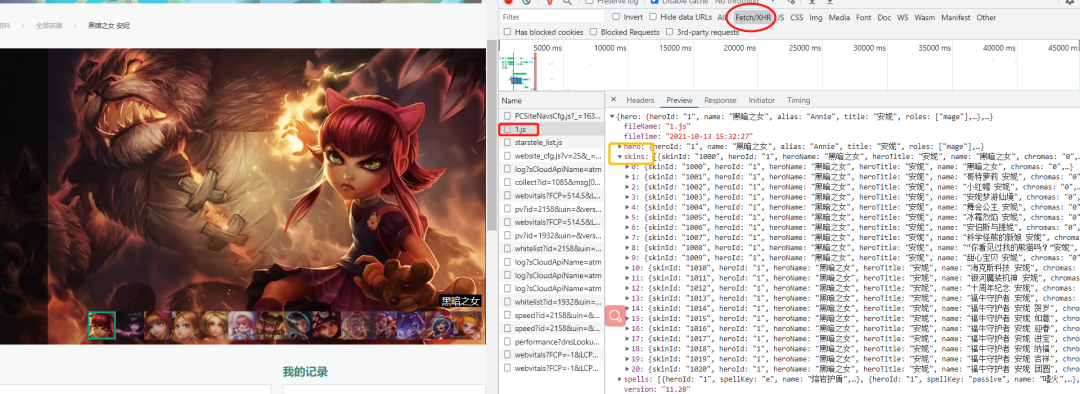
我们知道了皮肤信息是一个 json 格式的字符串进行传输的,那么我们只要找到每个英雄对应的 id,找到对应的 json 文件,提取需要的数据就能得到高清皮肤壁纸。
然后这里黑暗之女的 json 的文件地址是:
hero_one = 'https://game.gtimg.cn/images/lol/act/img/js/hero/1.js'
这里其实规律也非常简单,每个英雄的皮肤数据的地址是这样的:
url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(id)
那么问题来了 id 的规律是怎么样的呢?这里英雄的 id 需要在首页查看,如下所示:
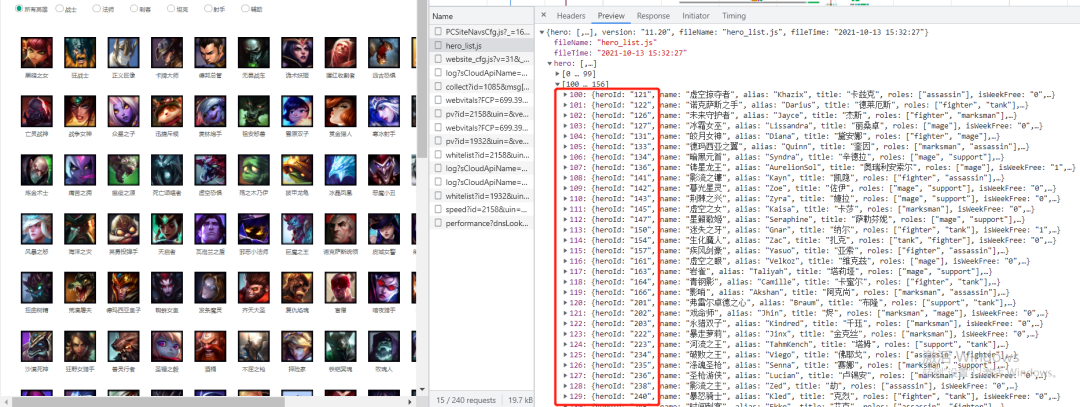
我们可以看到两个列表[0,99],[100,156],即 156 个英雄,但是 heroId 却一直到了 240….,由此可见,它是有一定的变化规律的,并不是依次加一,所以要爬取全部英雄皮肤图片,需要先拿到全部的heroId。
三、抓取思路
为什么使用多线程,这里解释一下,我们在爬取图片,视频这种数据的时候,因为需要保存到本地,所以会使用大量的文件的读取和写入操作,也就是 IO 操作,试想一下如果我们进行同步请求操作;
那么在第一次请求完成一直到文件保存到本地,才会进行第二次请求,那么这样效率非常低下,如果使用多线程进行异步操作,效率会大大提升。
所以必然要使用多线程或者是多进程,然后把这么多的数据队列丢给线程池或者进程池去处理;
在 Python 中,multiprocessing Pool 进程池,multiprocessing.dummy 非常好用。
multiprocessing.dummy模块:dummy模块是多线程;multiprocessing模块:multiprocessing是多进程;
multiprocessing.dummy模块与multiprocessing模块两者的 api 都是通用的,代码的切换使用上比较灵活;
我们首先在一个测试的 demo.py 文件抓取英雄 id,这里的代码我已经写好了,得到一个储存英雄 id 的列表,直接在主文件里使用即可;
demo.py
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
res = requests.get(url,headers=headers)
res = res.content.decode('utf-8')
res_dict = json.loads(res)
heros = res_dict["hero"] # 156个hero信息
idList = []
for hero in heros:
hero_id = hero["heroId"]
idList.append(hero_id)
print(idList)
得到 idList 如下所示:
idlist = [1,2,3,….,875,876,877] # 中间的英雄 id 这里不做展示
构建的 url:
page = 'http://www.bizhi88.com/s/470/{}.html'.format(i)
这里的 i 表示 id,进行 url 的动态构建;
那么我们定制两个函数一个用于爬取并且解析页面(spider),一个用于下载数据 (download),开启线程池,使用 for 循环构建存储英雄皮肤 json 数据的 url,储存在列表中,作为 url 队列,使用 pool.map() 方法执行 spider (爬虫)函数;
def map(self, fn, *iterables, timeout=None, chunksize=1):
"""Returns an iterator equivalent to map(fn, iter)”“”
# 这里我们的使用是:pool.map(spider,page) # spider:爬虫函数;page:url队列
作用:将列表中的每个元素提取出来当作函数的参数,创建一个个进程,放进进程池中;
参数1:要执行的函数;
参数2:迭代器,将迭代器中的数字作为参数依次传入函数中;
json数据解析
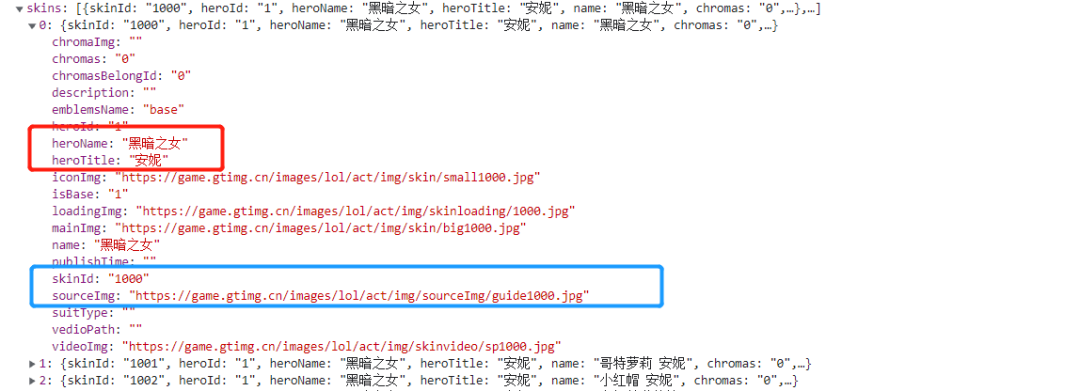
这里我们就以黑暗之女的皮肤的 json 文件做展示进行解析,我们需要获取的内容有 1.name,2.skin_name,3.mainImg,因为我们发现 heroName 是一样的,所以把英雄名作为该英雄的皮肤文件夹名,这样便于查看保存;
item = {}
item['name'] = hero["heroName"]
item['skin_name'] = hero["name"]
if hero["mainImg"] == '':
continue
item['imgLink'] = hero["mainImg"]
有一个注意点:
有的 mainImg 标签是空的,所以我们需要跳过,否则如果是空的链接,请求时会报错;
四、数据采集
导入相关第三方库
import requests # 请求
from multiprocessing.dummy import Pool as ThreadPool # 并发
import time # 效率
import os # 文件操作
import json # 解析
页面数据解析
def spider(url):
res = requests.get(url, headers=headers)
result = res.content.decode('utf-8')
res_dict = json.loads(result)
skins = res_dict["skins"] # 15个hero信息
print(len(skins))
for index,hero in enumerate(skins): # 这里使用到enumerate获取下标,以便文件图片命名;
item = {} # 字典对象
item['name'] = hero["heroName"]
item['skin_name'] = hero["name"]
if hero["mainImg"] == '':
continue
item['imgLink'] = hero["mainImg"]
print(item)
download(index+1,item)
download 下载图片
def download(index,contdict):
name = contdict['name']
path = "皮肤/" + name
if not os.path.exists(path):
os.makedirs(path)
content = requests.get(contdict['imgLink'], headers=headers).content
with open('./皮肤/' + name + '/' + contdict['skin_name'] + str(index) + '.jpg', 'wb') as f:
f.write(content)
这里我们使用 OS 模块创建文件夹,前面我们有说到,每个英雄的 heroName 的值是一样的,借此创建文件夹并命名,方便皮肤的保存(归类),然后就是这里图片文件的路径需要仔细,少一个斜杠就会报错。
main() 主函数
def main():
pool = ThreadPool(6)
page = []
for i in range(1,21):
newpage = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(i)
print(newpage)
page.append(newpage)
result = pool.map(spider, page)
pool.close()
pool.join()
end = time.time()
说明:
在主函数里我们首选创建了六个线程池;
通过 for 循环动态构建 20 条 url,我们小试牛刀一下,20 个英雄皮肤,如果爬取全部可以对之前的 idList 遍历,再动态构建 url;
使用 map() 函数对线程池中的 url 进行数据解析存储操作;
当线程池 close 的时候并未关闭线程池,只是会把状态改为不可再插入元素的状态;
五、程序运行
if __name__ == '__main__':
main()
结果如下:

当然了这里只是截取了部分图像,总共爬取了 200+ 张图片,总体来说还是可以。
六、总结
本次我们使用了多线程爬取了英雄联盟官网英雄皮肤高清壁纸,因为图片涉及到 IO 操作,我们使用并发方式进行,大大提高了程序的执行效率。
当然爬虫浅尝辄止,此次小试牛刀,爬取了 20 个英雄的皮肤图片,感兴趣的小伙伴可以把皮肤全部爬取下来,只需要改变遍历的元素为之前的 idlist 即可。
如需获取本文完整代码及 LOL 壁纸,请为本文右下角点亮在看并添加杰哥微信:Hc220088 获取。
以上就是本期分享的全部内容,我是杰哥,如果你觉得这篇文章对你有点用的话,就请为本文留个言,点个赞 or 在看,或者转发一下吧,我们下期不见不散!

推荐阅读
