
【评价指标】详解F1-score与多分类F1
基本概念
首先,要背住的几个概念就是:accuracy,precision,recal, TP,FP,TN,FN
TP:true positive。预测是正确的正样本 FP:false positive。预测是错误的正样本 TN:true negative。预测是正确的负样本 FP:false positive。预测是错误的负样本
通常我们会做出这样的一个混淆矩阵:
| Positive | Negative | |
|---|---|---|
| Positive | True Positive | False Positive |
| Negative | False Negative | True Negative |
左边的positive,negative表示样本真实值,表格上边的positive,negative表示样本的预测结果。
现在我们有这样的一个例子: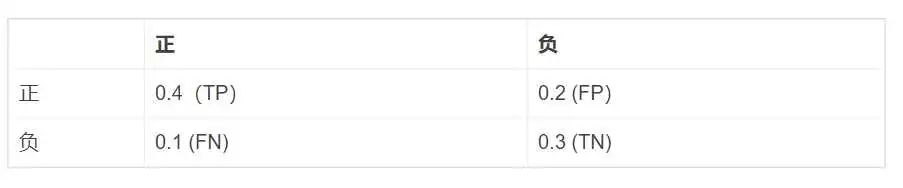 图中的TP,FP等是一个比例,假设总共有100个样本,有40个是TP,有20个是FP……(不过混淆矩阵一般不用除以总样本数量)
图中的TP,FP等是一个比例,假设总共有100个样本,有40个是TP,有20个是FP……(不过混淆矩阵一般不用除以总样本数量)
现在我们有了
准确率Accuracy
准确率是指,对于给定的测试数据集,分类器正确分类的样本书与总样本数之比,也就是预测正确的概率。
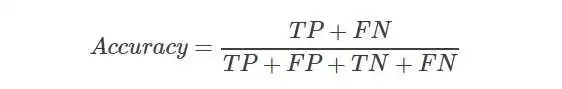
对应上面的例子,可以得到Accuracy=0.7。
【准确率Accuracy的弊端】
准确率作为我们最常用的指标,当出现样本不均衡的情况时,并不能合理反映模型的预测能力。例如测试数据集有90%的正样本,10%的负样本,假设模型预测结果全为正样本,这时准确率为90%,然而模型对负样本没有识别能力,此时高准确率不能反映模型的预测能力。
精确率Precision
表示预测为正的样本中,实际的正样本的数量。
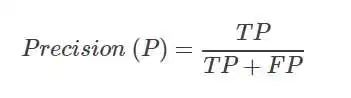
对应上面的例子,。
【个人理解】
Precision是针对预测结果而言的。预测结果中,预测为正的样本中预测正确的概率。**类似于一个考生在考卷上写出来的答案中,正确了多少。**体现模型的精准度,模型说:我说哪个对哪个就是对的。
召回率Recall
Recall表示实际为正的样本被判断为正样本的比例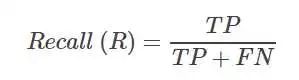 对应上述的例子,得到
对应上述的例子,得到
【个人理解】
Recall是针对数据样本而言的。数据样本中,正样本中预测正确的概率。类似于一个考生在考卷上回答了多少题。体现一个模型的全面性,模型说:所有对的我都能找出来。
F1 score
Precision和Recall是一对矛盾的度量,一般来说,Precision高时,Recall值往往偏低;而Precision值低时,Recall值往往偏高。当分类置信度高时,Precision偏高;分类置信度低时,Recall偏高。为了能够综合考虑这两个指标,F-measure被提出(Precision和Recall的加权调和平均),即: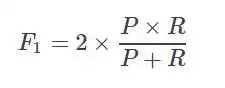
F1的核心思想在于,在尽可能的提高Precision和Recall的同时,也希望两者之间的差异尽可能小。F1-score适用于二分类问题,对于多分类问题,将二分类的F1-score推广,有Micro-F1和Macro-F1两种度量。
【Micro-F1】
统计各个类别的TP、FP、FN、TN,加和构成新的TP、FP、FN、TN,然后计算Micro-Precision和Micro-Recall,得到Micro-F1。具体的说,统计出来各个类别的混淆矩阵,然后把混淆矩阵“相加”起来,得到一个多类别的混淆矩阵,然后再计算F1score
【Macro-F1】
我感觉更常用的是Macro-F1。统计各个类别的TP、FP、FN、TN,分别计算各自的Precision和Recall,得到各自的F1值,然后取平均值得到Macro-F1
【总结】
从上面二者计算方式上可以看出,Macro-F1平等地看待各个类别,它的值会受到稀有类别的影响;而Micro-F1则更容易受到常见类别的影响。
参考:
[1]http://zjmmf.com/2019/08/13/F1-Score%E8%AE%A1%E7%AE%97/
[2]https://zhuanlan.zhihu.com/p/49895905
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群请扫码进群: