
机器学习:模型评价指标总结
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
子曰:“温故而知新,可以为师矣。
混淆矩阵
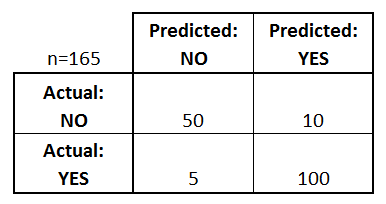
混淆矩阵是一种特定的矩阵用来呈现算法性能的可视化效果,通常用于二分类模型。其每一列代表预测值,每一行代表的是实际的类别。
其实就是把所有类别的预测结果与真实结果按类别放置到了同一个表里,在这个表格中我们可以清楚看到每个类别正确识别的数量和错误识别的数量。
Name 预测值 真实值
TP Y Y
TN N N
FP Y N
FN N Y
TP :预测为正样本,实际也是正样本。
FP :预测为正样本,实际是负样本。
FN :预测为负样本,实际是正样本。
TN :预测为负样本,实际也是负样本。

准确率
准确率是指我们的模型预测正确的结果所占的比例。
精确率
所有预测为正样本的集合中预测正确的比例,精确度告诉我们,实际上有多少正确预测的案例是肯定的。
召回率
召回率告诉我们可以使用模型正确预测多少实际阳性病例。
F1 值
实际上,当我们尝试提高模型的精度时,召回率会下降,反之亦然。F1分数以单个值捕获了两种趋势。F1得分是Precision和Recall的谐波平均值,因此它给出了关于这两个指标的组合思想。当Precision等于Recall时,最大值。
ROC & AUC
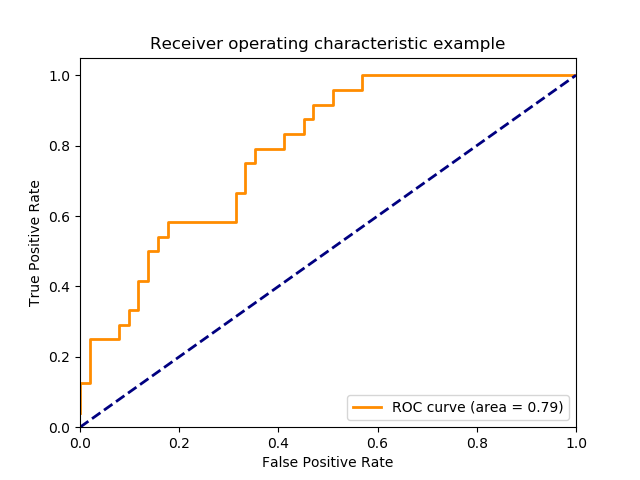
ROC曲线,它的横纵坐标分别是
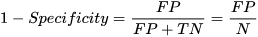
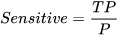
对于预测出的概率值和它们的真实label,当取不同阈值时,会得到很多的坐标 (x,y),把这些点都连接起来就是ROC曲线。
auc值是roc曲线下的面积,从定义就能看出,对于同一个 x,我们希望 y 越大越好,也就是说,在 FP 固定的时候,模型中 TP 越高 AUC 值就越高,所以 AUC 值很在乎正样本的准确率,当数据比例不平衡时,我们的模型很可能偏向预测样本数更多的负样本,虽然这时准确率和 log损失 看着都不错,可是 AUC 值却不理想。
log损失
log损失反映了样本的平均偏差,经常作为模型的损失函数来做优化,可是,当训练数据正负样本不平衡时,比如我们经常会遇到正样本很少,负样本很多的情况,我们更希望在控制 FP 的情况下检出更多的正样本,若不做任何处理,则降低LogLoss会倾向于偏向负样本一方,此时LogLoss很低,可正样本的检出效果却并不理想。
MAE
平均绝对误差(Mean Absolute Error),观测值与真实值的误差绝对值的平均值。
MSE
均方误差(MSE)是最常用的回归损失函数,计算方法是求预测值与真实值之间距离的平方和。
MAE对于异常值比MSE更稳定,相对于使用MAE计算损失,使用MSE的模型会赋予异常点更大的权重。如果异常点代表在商业中很重要的异常情况,并且需要被检测出来,则应选用MSE损失函数。相反,如果只把异常值当作受损数据,则应选用MAE损失函数。
R方
RMSE和MAE有局限性:同一个算法模型,解决不同的问题,不能体现此模型针对不同问题所表现的优劣。因为不同实际应用中,数据的量纲不同,无法直接比较预测值,因此无法判断模型更适合预测哪个问题。方案:将预测结果转换为准确度,结果都在[0, 1]之间,针对不同问题的预测准确度,可以比较并来判断此模型更适合预测哪个问题;

也可以加一下老胡的微信 围观朋友圈~~~
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓