
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近日,谷歌研究团队(ViT同名作者)最新的研究论文Scaling Vision Transformers(https://arxiv.org/pdf/2106.04560.pdf),发布了包含20亿参数的vision transformer模型ViT-G/14,在ImageNet的Top-1可以达到90.45%,超过之前谷歌提出的Meta Pseduo Labels模型。
但其实谷歌这篇论文的重点是研究vision transformer模型的scaling laws,在NLP领域已经有研究(Scaling laws for neural language models)给出了语言模型效果和 compute, data size, model size之间的指数定律,更有GPT-3这样成功的模型。虽然已经有论文研究(如EfficientNet)CNN模型的scaling strategy:模型增大提升效果。但是在CV领域还是缺少比较全面的研究,而且最近vision transformer的成功应用更是需要这样的工作。
在这篇论文中,实验模型参数从5M到2B,训练数据量从30M到3B,训练时长从1 TPUv3 core-day到10 000 core-days。这使得谷歌比较全面地研究ViT模型效果和model size,data size和compute之间的scaling laws。
论文中采用的是ViT模型,并增加了G/14这样超大的模型(接近2B),不同大小的模型如下所示,主要区别在patch size以及transformer layer的参数配置。

在数据方面,谷歌又抛出重磅炸弹:JFT-3B,这个是JFT-300M的超大版本,包含接近30亿的图像,标注为包含30k类别的层级类别,由于采用半自动标注,所以标注是有噪音的。具体到训练模型,直接采用sigmoid cross-entropy损失训练多分类模型,忽略类别间层级关系。所有的测试数据均从JFT-3B中移除。
据此,实验分别改变architecture size,number of training
images和training duration来测试模型的representation quality,具体可以用(i) few-shot transfer via training a linear classifier on frozen weights, (ii) transfer via fine-tuning the
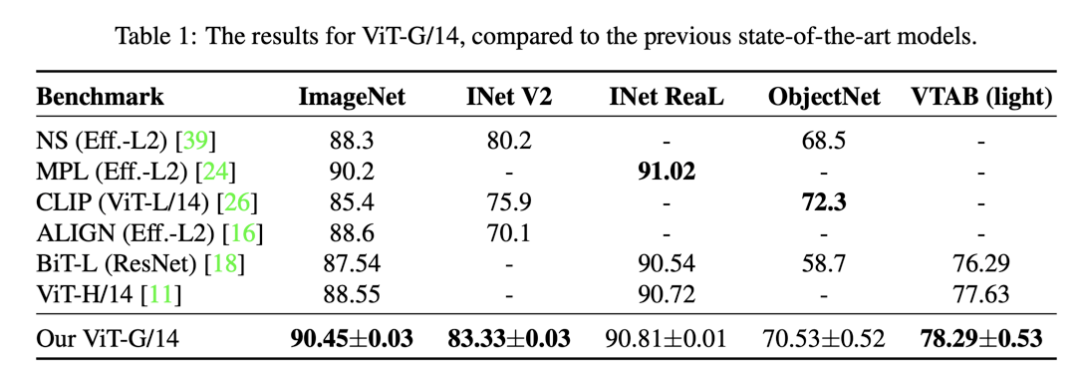
whole model on all data, both to multiple benchmark tasks来作为评价指标,下图是在ImageNet数据集上的结果:
最终的结论主要有三点:
scaling up compute, model and data together improves representation quality:同时增大模型,训练数据和计算力是可以同步提升效果的,近似满足指数定律(log-log曲线是线性的);
representation quality can be bottlenecked by model size:模型大小会限制上限,小的模型即使用再大的数据集也难以继续提升;
large models benefit from additional data, even beyond 1B images:对于大模型来说,训练数据会制约性能上限,对于最大的模型,训练数据量从1B提升至3B,效果还有提升。
虽然从实验看来,ViT模型也满足指数scaling定律,但是其实是double-saturating power law:对于最小的模型,其效果会比指数定律预测值要好,这是因为模型效果也有下限;而最大的模型即使给再多的训练数据和算力也不会达到0 error,模型也有上限。所以出现了双饱和。
除了上述结论,论文还发现了额外的结论:bigger models are more sample efficient,即大的模型需要更少的unseen数据就可以达到和小模型类似的效果,如下图所示:
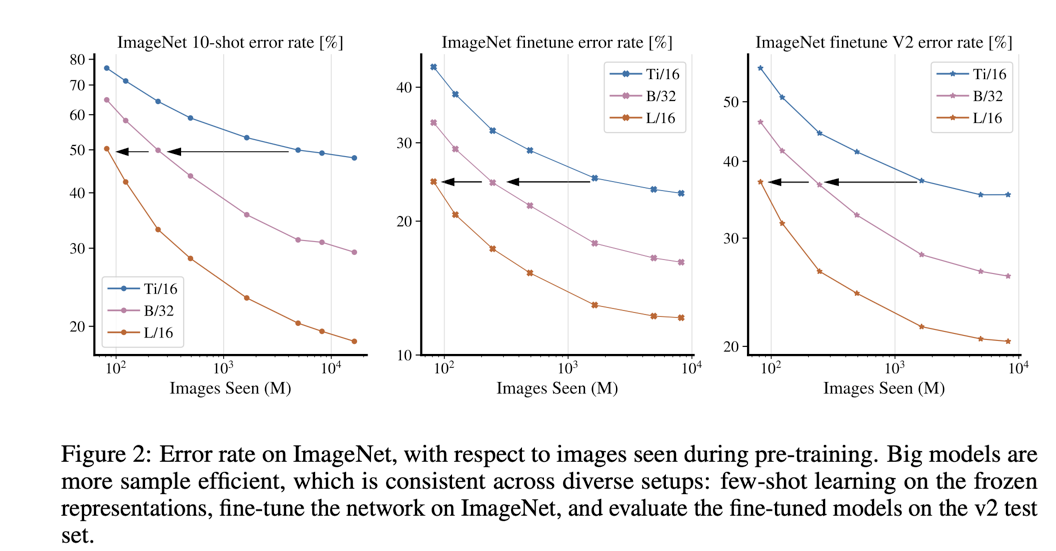
最大的模型ViT-G/14,接近2B参数,在ImageNet上finetune后top-1 acc可达90.45%,而且在few-shot learning也表现优异,每个类只用10个图像训练就能在ImageNet上达到84.86%。
另外,在训练ViT模型,论文中还设计了一些训练策略来提升内存利用和模型效果,这些策略也使得ViT-G/14可以采用数据并行训练策略,这意味着ViT-G/14模型可以放在一张TPUv3 core。具体策略包括:
Decoupled weight decay for the “head”:模型的head(分类的linear层)和模型的主体body部分采用不同的weight decay,论文中发现head采用较大的weight decay有助于迁移到下游任务(可能和SVM类似,拉大类间间距);
Saving memory by removing the [class] token:采用multihead
attention pooling (MAP) 来替换class token,class token会使得TPU需要padding而增加50%内存使用;Memory-efficient optimizers:对于Adam优化器,采用half-precision momentum,并采用Adafactor优化器(进行了修改)来进一步减少内存使用;
Learning-rate schedule:学习速率learning-rate schedules引入cooldown阶段(学习速率逐渐降为0),这样可以一次训练就可以得到不同训练时长的模型。

谷歌做这个实验的代价自然不必说,也有很多人在质疑这个研究的意义,但是论文也在最后给出了这个工作的意义,首先就是这个scaling laws做出来后对后续研究是有启发意义的:
First, such studies of scaling laws need only be performed once; future developers of ViT
models may use our results to design models that can be trained with fewer compute resources.
此外,这个预训练模型可以迁移到其它任务:
Second, the models trained are designed primarily for transfer learning. Transfer of pre-trained
weights is much less expensive than training from scratch on a downstream task, and typically reaches
higher accuracy.
作为一个AI大厂,Google做这么大的work,我个人还是持肯定态度。
推荐阅读
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
