
Python训练了个模型,怎么交给Java用呢?
最近碰到几个人问,如何实现 java 调用他们写好的 Python 应用(模型)
这里我就把几种常见的办法做下汇总整理。
1. 通过命令行调用
如使用 java 的 ProcessBuilder API,
#hello.py
print("Hello ProcessBuilder!")
import java.util.stream.Collectors;
import java.util.List;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.InputStream;
import java.io.BufferedReader;
import java.io.IOException;
public class PyEx0{
private static List readOutput(InputStream inputStream) throws IOException {
try (BufferedReader output = new BufferedReader(new InputStreamReader(inputStream))) {
return output.lines()
.collect(Collectors.toList());
}
}
public static void main(String[] args) throws Exception {
ProcessBuilder processBuilder = new ProcessBuilder("python", "hello.py");
processBuilder.redirectErrorStream(true);
Process process = processBuilder.start();
List results = readOutput(process.getInputStream());
System.out.println(results);
int exitCode = process.waitFor();
System.out.println(exitCode);
}
}
2. 通过 REST API
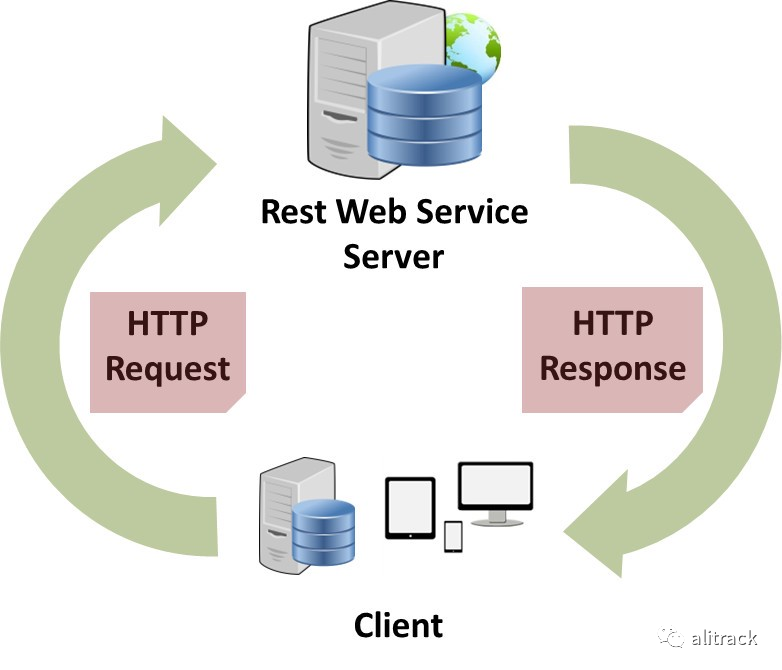
REST 是表现层状态转换(英语:Representational State Transfer)的英文缩写,是 Roy Thomas Fielding 博士于 2000 年在他的博士论文中提出来的一种万维网软件架构风格,目的是便于不同软件/程序在网络(例如互联网)中互相传递信息。表现层状态转换是根基于超文本传输协议(HTTP)之上而确定的一组约束和属性,是一种设计提供万维网络服务的软件构建风格。符合或兼容于这种架构风格(简称为 REST 或 RESTful)的网络服务,允许客户端发出以统一资源标识符访问和操作网络资源的请求,而与预先定义好的无状态操作集一致化。因此表现层状态转换提供了在互联网络的计算系统之间,彼此资源可交互使用的协作性质(interoperability)。相对于其它种类的网络服务,例如 SOAP 服务,则是以本身所定义的操作集,来访问网络上的资源。
目前在三种主流的 Web 服务实现方案中,因为 REST 模式与复杂的 SOAP 和 XML-RPC 相比更加简洁,越来越多的 Web 服务开始采用 REST 风格设计和实现。例如,Amazon.com 提供接近 REST 风格的 Web 服务执行图书查询;雅虎提供的 Web 服务也是 REST 风格的。
使用你熟悉的 Python 开发框架构建 Restful Server, 我之前介绍过一个专门用于部署机器学习框架的,详见
100天搞定机器学习 番外:使用FastAPI构建机器学习API
有兴趣的同学也可以尝试下试下比较流行的 GraphQL,网上关于基于 GraphQL 开发模型 API 的文章也不少。
3. GraphQL
GraphQL 是一个开源的,面向 API 而创造出来的数据查询操作语言以及相应的运行环境。于 2012 年仍处于 Facebook 内部开发阶段,直到 2015 年才公开发布。2018 年 11 月 7 日,Facebook 将 GraphQL 项目转移到新成立的 GraphQL 基金会(隶属于非营利性的 Linux 基金会)。
GraphQL 相较于 REST 以及其他 web service 架构提供了一种更加高效、强大和灵活的开发 web APIs 的方式。它通过由客户端根据所需定义数据结构,同时由服务端负责返回相同数据结构的对应数据的方式避免了服务端大量冗余数据的返回,但与此同时也意味着这种方式不能有效利用起查询结果的 web 缓存。GraphQL 这种查询语言所带来的灵活性和丰富性的同时也增加了复杂性,导致简单的 APIs 有可能并不适合这种方式。
GraphQL 支持数据读取、写入(操作)和数据变更订阅(实时更新)。
主要的 GraphQL 客户端有 Apollo Clien 和 Relay. GraphQL 的服务端在多个语言都有实现包括 Haskell, JavaScript, Python,Ruby, Java, C#, Scala, Go, Elixir, Erlang, PHP, R,和 Clojure.
2018 年 2 月 9 日 GraphQL 的部分模式定义语言(SDL)规范制定完成。
4. PMML
PMML(Predictive Model Markup Language)是预测模型的通用描述语言,简单的说就是用 XML 语法保存模型的一种标准规范,按照这个格式保存模型,其他编程语言也可以加载模型完成预测。
更多 PMML 信息,可以访问 https://github.com/jpmml
5. m2cgen
m2cgen[1], 模型转代码生成器,是一个轻量级库,它提供了一种将经过训练的统计模型转换为本机代码(Python、C、Java、Go、JavaScript、Visual Basic、C#、PowerShell、R、PHP、Dart、 Haskell、Ruby、F#、Rust)。
安装
pip install m2cgen
支持模型

使用方法 将训练好的模型转为 Java code,只需一行代码(最后一行)
from sklearn.datasets import load_boston
from sklearn import linear_model
import m2cgen as m2c
boston = load_boston()
X, y = boston.data, boston.target
estimator = linear_model.LinearRegression()
estimator.fit(X, y)
code = m2c.export_to_java(estimator)
生成一个 Java 类
public class Model {
public static double score(double[] input) {
return (((((((((((((36.45948838508965)
+ ((input[0]) * (-0.10801135783679647)))
+ ((input[1]) * (0.04642045836688297)))
+ ((input[2]) * (0.020558626367073608)))
+ ((input[3]) * (2.6867338193449406)))
+ ((input[4]) * (-17.76661122830004)))
+ ((input[5]) * (3.8098652068092163)))
+ ((input[6]) * (0.0006922246403454562)))
+ ((input[7]) * (-1.475566845600257)))
+ ((input[8]) * (0.30604947898516943)))
+ ((input[9]) * (-0.012334593916574394)))
+ ((input[10]) * (-0.9527472317072884)))
+ ((input[11]) * (0.009311683273794044)))
+ ((input[12]) * (-0.5247583778554867));
}
}
6. Jython

Jython(原 JPython),是一个用 Java 语言写的 Python 解释器。
Jython 程序可以和 Java 无缝集成。除了一些标准模块,Jython 使用 Java 的模块。Jython 几乎拥有标准的 Python 中不依赖于 C 语言的全部模块。比如,Jython 的用户界面将使用 Swing,AWT 或者 SWT。Jython 可以被动态或静态地编译成 Java 字节码。
Jython 还包括 jythonc,一个将 Python 代码转换成 Java 代码的编译器。这意味着 Python 程序员能够将自己用 Python 代码写的类库用在 Java 程序里。
这东西是不错,但有个致命的问题,不支持 Python3,除非你仍然在使用 Python2,否则没有啥用。
7. GraalVM Python Runtime

GraalVM 提供了一个兼容 Python 3.8 的运行时。GraalVM Python 运行时的主要目标是支持 SciPy 及其组成库,以及与来自丰富 Python 生态系统的其他数据科学和机器学习库一起使用。
官方的数据说:graalpython(企业版) 比 CPython 快 8.92 倍,比 Jython 快 8.34 倍。
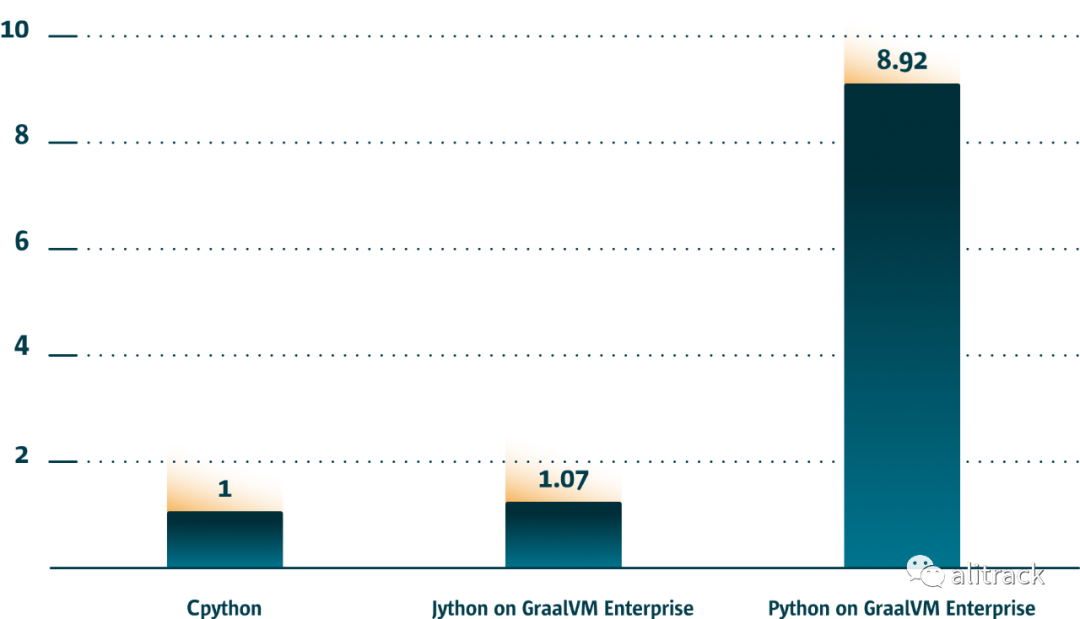
我装的是社区版,没有做过对比测试。
以后我会另外写文章介绍 GraalVM,今天就简单介绍下如何写一个简单的 Python 程序。
安装 GraalVM
目前 GraalVM 提供了 四种平台的预编译版本(对应的 Java 版本有 11 和 17),以及 Docker 的支持。
Linux
Linux AArch64
macOS
Windows
Docker Container
平台的安装方式都一样,下载解压缩,以 macOS java17 为例,
wget https://github.com/graalvm/graalvm-ce-builds/releases/download/vm-21.3.0/graalvm-ce-java17-darwin-amd64-21.3.0.tar.gz
tar xf graalvm-ce-java17-darwin-amd64-21.3.0.tar.gz
sudo mv graalvm-ce-java17-21.3.0 /Library/Java/JavaVirtualMachines/
sudo xattr -r -d com.apple.quarantine /Library/Java/JavaVirtualMachines/graalvm-ce-java17-21.3.0/Contents/Home
验证下 所安装的 java 版本和默认的 java 版本,
$ /usr/libexec/java_home -V
Matching Java Virtual Machines (3):
17.0.1 (x86_64) "GraalVM Community" - "GraalVM CE 21.3.0" /Library/Java/JavaVirtualMachines/graalvm-ce-java17-21.3.0/Contents/Home
1.8.311.11 (x86_64) "Oracle Corporation" - "Java" /Library/Internet Plug-Ins/JavaAppletPlugin.plugin/Contents/Home
1.8.0_31 (x86_64) "Oracle Corporation" - "Java SE 8" /Library/Java/JavaVirtualMachines/jdk1.8.0_31.jdk/Contents/Home
/Library/Java/JavaVirtualMachines/graalvm-ce-java17-21.3.0/Contents/Home
安装 Python
$ gu install python
$ gu install llvm-toolchain
$ graalpython --version
Python 3.8.5 (GraalVM CE Native 21.3.0)
创建虚拟环境以及安装包
$ graalpython -m venv .venv
$ source .venv/bin/activate
#下面这个编译过程有些长
$ graalpython -m ginstall install pandas
$ pip list
Package Version
--------------- -------
hpy 0.0.3
numpy 1.16.4
pandas 0.25.0
pip 20.1.1
polyglot 16.7.4
python-dateutil 2.7.5
pytz 2018.7
setuptools 47.1.0
setuptools-scm 1.15.0
six 1.12.0
pandas 版本有些低 0.25.0。
例子
python 代码
#hello.py
import pandas as pd
def get_data():
d = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data=d)
return df
get_data()
java 代码
import java.io.FileNotFoundException;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.nio.file.Paths;
import org.graalvm.polyglot.Context;
import org.graalvm.polyglot.Source;
import org.graalvm.polyglot.Value;
public class Pandas {
private static String PYTHON = "python";
private static String VENV_EXECUTABLE =Paths.get(".venv", "bin", "graalpython").toString();
private static String SOURCE_FILE_NAME = "ex.py";
public static void main(String[] args) throws Exception {
Context context = Context.newBuilder(PYTHON).
allowAllAccess(true).
option("python.Executable", VENV_EXECUTABLE).
option("python.ForceImportSite", "true").
build();
try {
FileInputStream input = new FileInputStream(SOURCE_FILE_NAME);
InputStreamReader code = new InputStreamReader(input);
Source source = Source.newBuilder(PYTHON, code, SOURCE_FILE_NAME).build();
Value value = context.eval(source);
System.out.println(value);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
该方案还不够成熟。
参考资料
m2cgen: https://github.com/BayesWitnesses/m2cgen
三连在看,月入百万👇