
不用1750亿!OpenAI CEO放话:GPT-4参数量不增反减

新智元报道
新智元报道
来源:AIM
编辑:好困
【新智元导读】不要100万亿!也不要10万亿!更不要1750亿!GPT-4参数量竟然比GPT-3还少!
GPT-4官宣?

甚至连OpenAI的「自己人」也觉得这怎么也得有个100亿吧。

GPT-4的期待

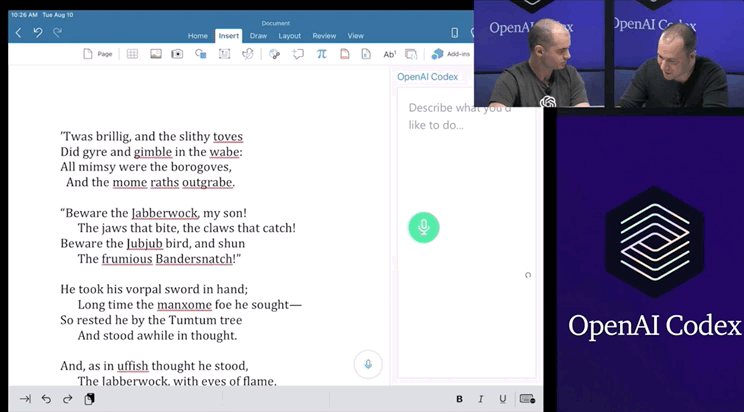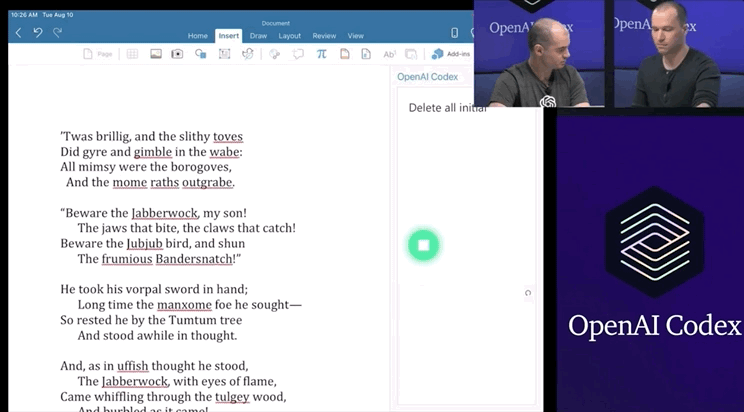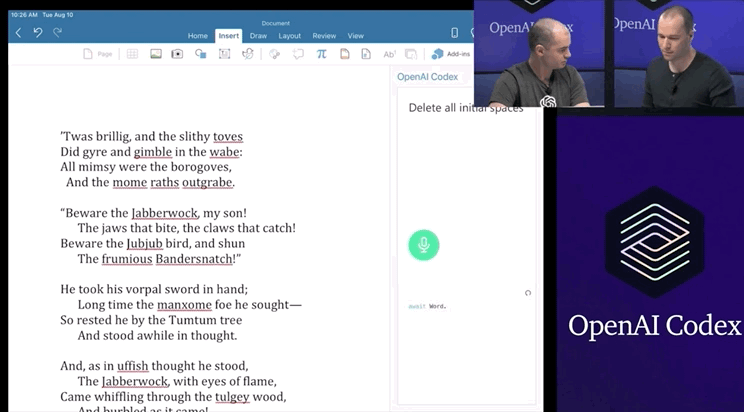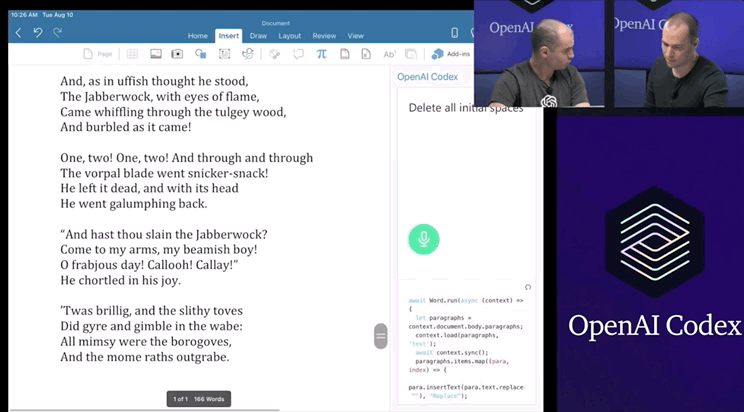
DALL.E将开源
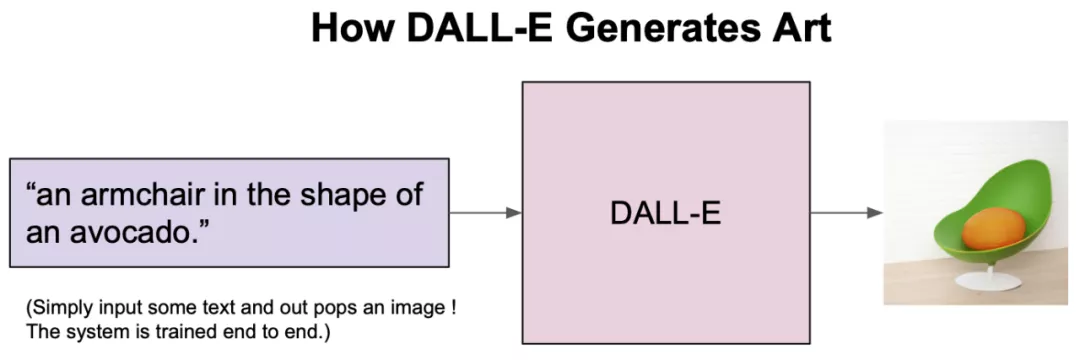
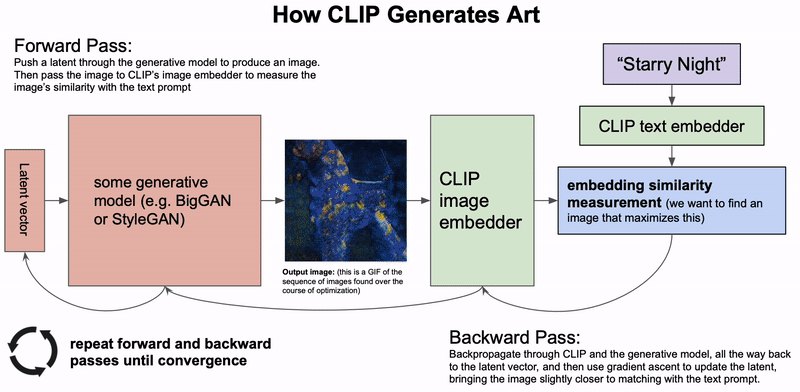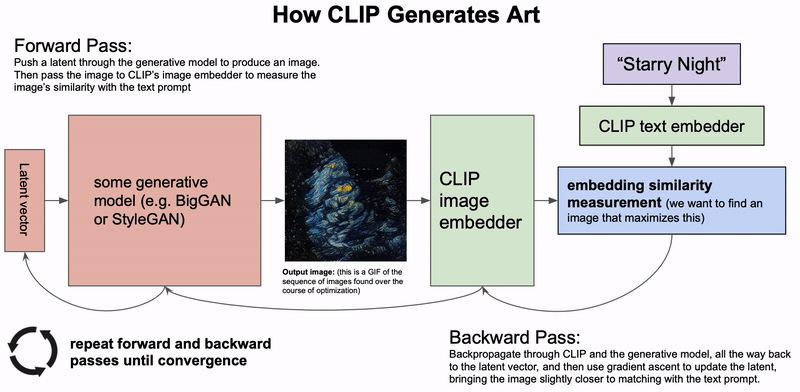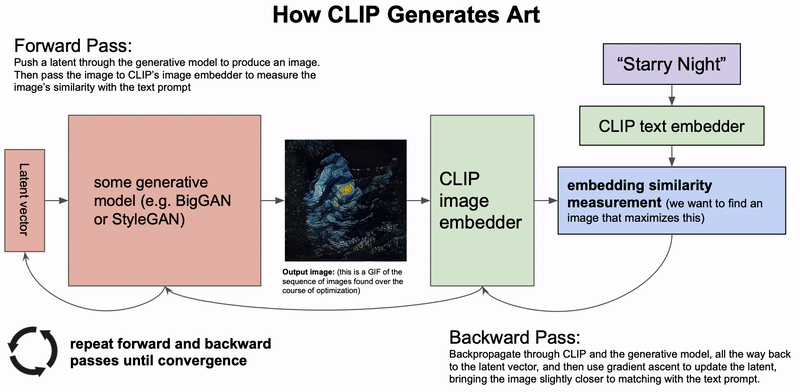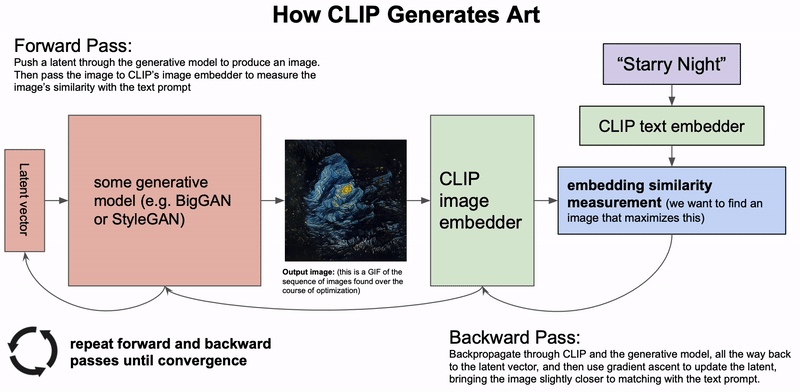

AGI:算法、数据和计算机
AGI:算法、数据和计算机
参考资料:
https://analyticsindiamag.com/gpt-4-sam-altman-confirms-the-rumours/
https://towardsdatascience.com/gpt-4-will-have-100-trillion-parameters-500x-the-size-of-gpt-3-582b98d82253

评论