
谈谈我眼中的Label Smooth
【GiantPandaCV导语】label smooth(标签平滑)作为一种简单的训练trick,能通过很少的代价(只需要修改target的编码方式),即可获得准确率的提升。本文想要通过一些简单的公式推导,理解target使用label smooth表示会比单纯的使用one-hot好在哪里。感谢深度眸在本文中对我的帮助。
前言
本文的开头先引用下《深度学习》中文版,第四章开头的一段话。
机器学习的算法通常需要大量的数值计算。这通常是指通过迭代过程更新解的估计值来解决数学问题的算法,而不是通过解析过程推导出公式来提供正确解的方法。常见的操作包括优化(找到最小化或者最大化函数值的参数)和线性方程组的求解。对数字计算机来说实数无法在有限内存下精确表示,因此仅仅是计算涉及实数的函数也是困难的。
这里就涉及到两个求解数学问题的方法:
迭代更新解的估计值,如通过二分法和牛顿迭代法求开方的过程。 解析过程推导公式,如我们考试中的那些需要大量计算的数学题,一般最后会得出一个解析解。
在整日学习深度学习之后,我们有的时候也需要用解析解,即公式推导求解一些深度学习的问题。
one-hot解析解推导
神经网络的输出称为logits,简记为,经过softmax之后转化为和为1的概率形式,记为,真值target记为,为分类类别的数量。本文所有讨论的内容是在导数等于0的情况下(解析解的情况下),为多少(神经网络的输出是多少)。当损失函数为交叉熵且target的编码和为1时, 导数则为(求导过程文章:https://zhuanlan.zhihu.com/p/343988823 ), 假设总共有个类. 可以有如下的公式.
令公式(1)的导数等于0, 可以得到公式(2), 记真值下标为.
是通过推导出来的, 则
通过公式(3.1)可得
通过公式(3.2)也可以得上面的结果。所以target为one-hot编码,损失函数为交叉熵的情况下。解析解是
所以通过上述推导可以得到:最优的情况下,在one-hot编码和交叉熵的损失函数下,错误类的logit值要是负无穷,正确类要是一个常数。这种最优的情况一般是不能达到的,且会远大于.
在文章《Rethinking the inception architecture for computer vision》里面认为如果远大于,会出现两个不好的性质
导致过拟合,将所有的概率都赋给了真值,会导致泛化能力下降 鼓励真值对应的logit远大于其他值的logit,但是导数是有界的,也就是数值不会很大,想要达成远大于的效果,要更新很多很多次。
个人认为:logit要是负无穷,损失才会变为0,神经网络很难会有输出负无穷的情况(权重衰减还会约束着神经网络的参数)
label smooth解析解推导
label smooth是在《Rethinking the inception architecture for computer vision》里面提出来的。我觉得作者的想法应该是这样的:蒸馏改变了学习的真值,能获得更好的结果,但是它需要准确率更高的教师网络;如果我现在想要训练出一个准确率最高的模型,那么是没有网络能给我知识的,所以就通过label smooth学习一种简单的知识。
label smooth 学习的编码形式如公式(4)所示,其中是预定义好的一个超参数,一般取值0.1,是该分类问题的类别个数
令公式(4)导数等于0,可得到公式(5.1)和(5.2)。类似于公式(1)的求导,但是要注意target编码的和要为1( https://zhuanlan.zhihu.com/p/343988823 里面有解释).
因为正确的类只有1个;错误的类有K-1个,且解析解的情况下,错误类的概率是相等的。所以公式(5.1)可以推导为公式(6):
把公式(6)的放到右边,两边再取下对数可得公式(7)
我们通过公式(5.2)也能推出相同的解。右边的公式分子分母颠倒一下可得公式(8)
因为错误类的值是相等的,所以,则可得公式(9)
将记为, 则可得公式(10),即导数等于0的情况下,logit的取值。
和论文《bag of tricks for image classification with convolutional neural networks》中,给出的结果是一样的(文章里面交叉熵的和好像写反了)
带入label smooth定义的公式验算一下则是
所以,在损失函数为交叉熵的情况下,如果我们使用label-smooth编码,错误类的logit不会要求是负无穷。且错误类和正确类的logit值有一定大小误差的情况下,loss就会很小很小。
label smooth中的gap
论文《bag of tricks for image classification with convolutional neural networks》还画出了gap图,此处的gap就是导数等于0的情况下,和之间的数值误差
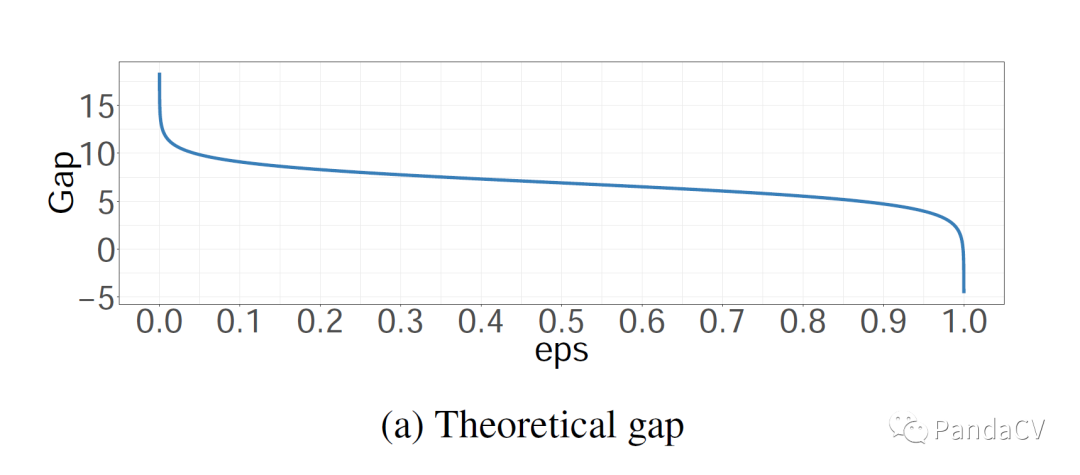
gap就是
,其中K是分类的类别数,(eps)是label smooth的超参数。假设取0.5且是1000分类,那么意思是,正确类和错误类的误差等于7就够了,损失不想要继续更新参数让他们的误差越来越大。实际代码的过程中,一般取即可。
总结
one-hot的编码方式需要错误类的logit趋向于负无穷,这样会导致正确类和错误类的logit输出误差很大,网络的泛化能力不强。并且因为网络训练时会有一些正则化的存在,logit的输出很难是负无穷。label-smooth的编码方式只要正确类和错误类有一定的数值误差即可,这个取决于分类的类别数量和。网络即使在正则化的情况下也比one-hot容易学习到最优情况。
代码
这里推荐https://github.com/CoinCheung/pytorch-loss/blob/master/label_smooth.py,大家需要注意的是这个代码的编码表示值和好像不为1.
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。