
(附论文&代码)PanoNet3D:一种3D目标检测方法
点击左上方蓝字关注我们

作者 | 黄浴@知乎
链接 | https://zhuanlan.zhihu.com/p/344409383
论文:https://arxiv.org/pdf/2012.09418.pdf
代码:https://github.com/poodarchu/Det3D

作者觉得大多数激光雷达检测方法只是利用目标几何结构,所以提出在一个多视角框架下学习目标的语义和结构特征,其利用激光雷达的特性,2D距离图像,以此提取语义特征。
该方法PanoNet3D结构如图:
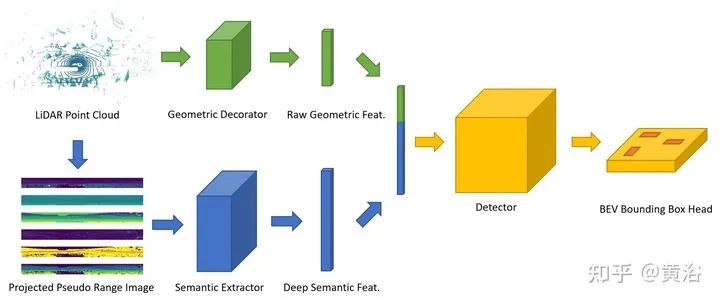
上面分支,LiDAR点云作为输入,用几个简单的局部几何特征修饰原始点特征,包括全局位置、局部相对所在体素中心的位移。
体素化有两种:1)3D正常体素化;2)pillarization,类似PointPillars。
下面分支,点云转换为伪距图像,类似LaserNet,得到结果如下图:5个通道,range r, height h, elevation angle theta, reflectance i, occupancy mask m。

馈入2D Semantic FPN (SFPN),获取每个像素的深度语义特征。将两个分支输出特征汇总并传递到主检测器。最终的框头部在BEV平面生成检测建议。单步检测器,基于anchor,预测朝向框以及置信度得分。
文中提出了时域多帧融合和空域多帧融合,前者简单,后者需要选择关键帧,如图是一个例子

这里取两帧n=2做实验。
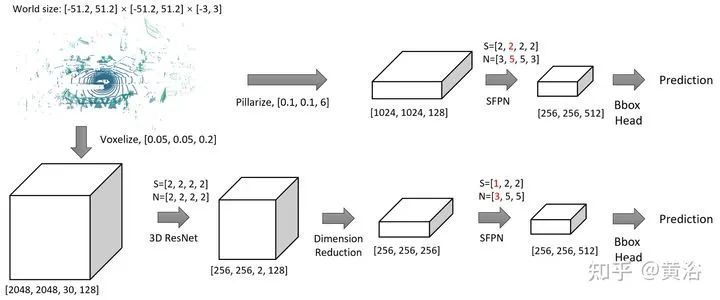
检测头设计如图:初始特征128维,整个场景大小限制为[-51.2, 51.2] [-51.2, 51.2] [-3, 3]米,分别在x-y-z方向。网络由ResNet基本块几层组成。S表示每层步幅,N表示块数。生成的SFPN特征图具有和该层同样分辨率的,标记为红色。可以是,3D voxelize输入或者pillarize再输入。
数据增强类似SECOND,cropped线下存储,做随机全局变换,如translation、scaling、rotation等。
该文实现是基于Det3D:CBGS开源库
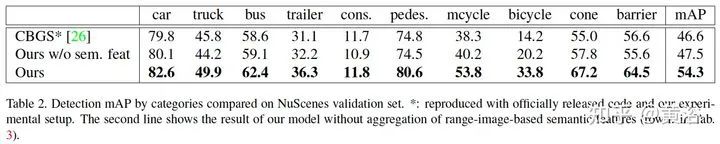
结果:

END
整理不易,点赞三连↓