
【论文介绍】:用双注意力模块来做语义分割
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


作者:Umer Rasheed
编译:ronghuaiyang
本文对双注意网络进行场景分割进行简要概述。
论文链接:https://arxiv.org/abs/1809.02983
本文认为,尽管编码器-解码器结构是一种标准的语义分割方法,近年来取得了很大的进展,但它严重依赖于局部信息,可能会带来一些偏见,因为无法看到全局信息。本文基于自注意机制,通过捕获丰富的上下文依赖关系来解决这一问题。
本文提出了双注意网络(DANet),该网络在扩展的FCN基础上附加两个注意力模块(位置注意力模块和通道力注意模块),分别在空间维度和通道维度上建模语义相关性。位置注意力模块选择性地聚合所有位置的特征。相似的特征是相互关联的,无论它们的距离如何。同时,通道注意力模块选择性地强调相互依赖的通道图。该网络将两个注意模块的输出相加,进一步改进特征表示,从而提高语义分割的准确性。
下文概述了下列情况:
双注意力网络 位置注意力模块 通道注意力模块 实验结果
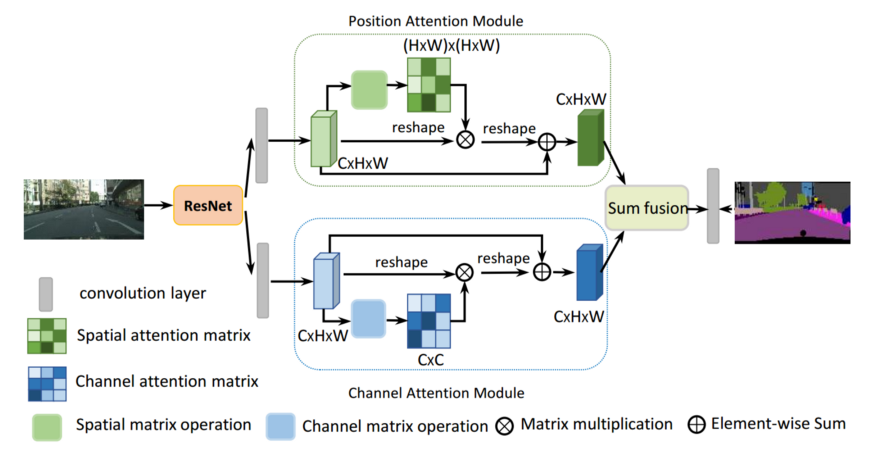
图1表示了图像通过一个带膨胀的残差块的整体网络。然后将扩展后的网状区域的局部特征输入两个并行卷积层,分别传递到位置注意力块和通道注意力块。两个注意力模块的输出通过另一个卷积层进行变换,计算元素和完成特征融合。最后通过卷积层生成最终的预测图。
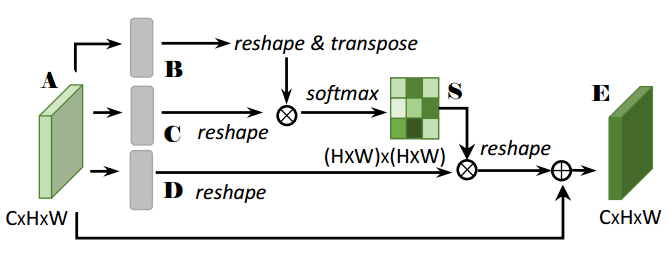
为了在局部特征上模拟丰富的上下文关系,引入了位置注意力模块。位置注意力模块将范围更广的上下文信息编码为局部特征,从而增强了局部特征的表示能力。
在位置注意力模块中,给定一个局部特征a∈R (C×H×W),首先将其输入一个卷积层,分别生成两个新的特征图B和C,其中{B, C}∈R (C×H×W)。然后这些特征图reshape为R (C×N),其中N = H×W是像素的数量。然后在C与B的转置之间进行矩阵乘法,应用softmax层计算空间注意力图S∈R(N×N)。两个位置的特征表示越相似,它们之间的相关性就越大。同时,将特征图A送入卷积层,生成新的特征图D∈R(C×H×W),并将其reshape为R(C×N)。然后在D和S的转置之间进行矩阵乘法,并将结果reshape为R (C×H×W)。最后,将其与尺度参数α相乘,并与特征图A进行元素求和运算,得到最终输出E∈R (C×H×W)。将尺度参数α初始化为0,逐步学习权值。
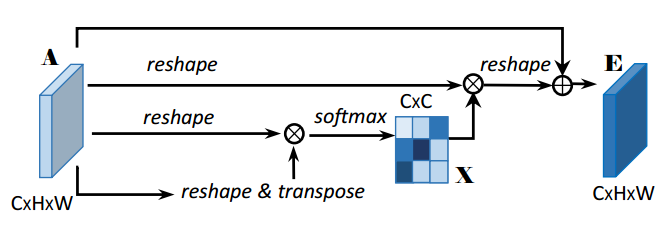
每个高级特征的通道图都可以看作是一个类特有的响应,不同的语义响应之间相互关联。通过利用通道图之间的相互依赖性,可以强调相互依赖的特征图,并改进特定语义的特征表示。因此,提出了一个通道注意例模块来显式地建模通道间的相互依赖性。
在通道注意力模块中,通道注意力图X∈R (C×C)是从原始特征图A∈R (C×H×W)中直接计算出来的。具体来说,将A reshape 成R(C×N),然后将A与A的转置进行矩阵乘法,最后应用softmax层得到通道注意力图X∈R(C×C)。此外,在X和A的转置之间进行矩阵乘法,其结果被reshape为R (C×H×W)。然后将结果与尺度参数β相乘,并与A进行元素求和运算,得到最终输出E∈R (C×H×W)。参数β从0逐步学习权值。
注意,注意力模块很简单,可以直接插入到现有的FCN管道中。
本文分别对有注意模力块和没有注意力模块时的结果进行了详细的比较。本文进行了一项全面的消融研究,将结果与其他最先进的语义分割网络进行比较。
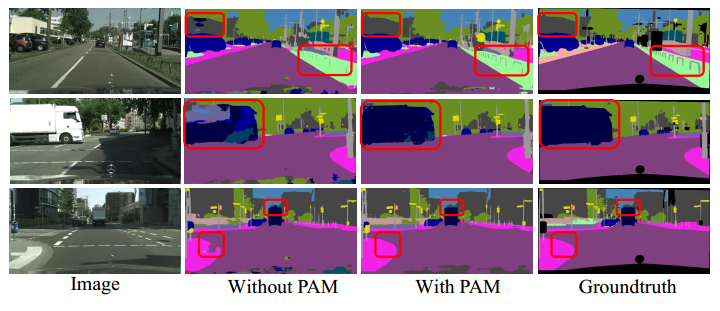
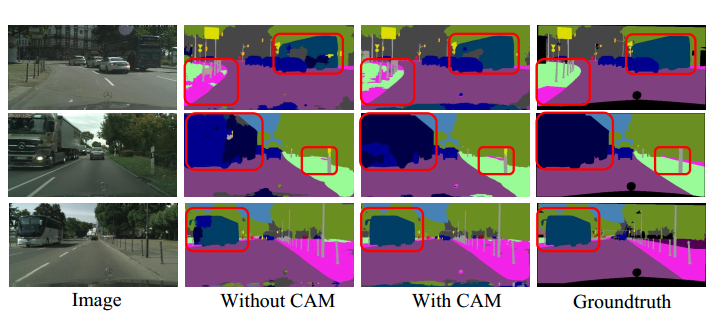
消融实验表明,双注意力模块能有效地捕获长距离上下文信息,并给出更精确的分割结果。注意力网络在4个场景分割数据集上均取得了优异的性能。

英文原文:https://umerrasheed.medium.com/review-dual-attention-network-for-scene-segmentation-1be813289ca4
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!