
使用TensorFlow和OpenCV实现口罩检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

在这段艰难的疫情期间,我们决定建立一个非常简单和基本的卷积神经网络(CNN)模型,使用TensorFlow与Keras库和OpenCV来检测人们是否佩戴口罩。

图片来源于澳门图片社
为了建立这个模型,我们将使用由Prajna Bhandary 提供的口罩数据集。这个数据集包括大约1,376幅图像,其中690幅图像包含戴口罩的人,686幅图像包含没有戴口罩的人。
我们将使用这些图像悬链一个基于TensorFlow框架的CNN模型,之后通过电脑端的网络摄像头来检测人们是否戴着口罩。此外,我们也可以使用手机相机做同样的事情。
首先,我们需要标记数据集中两个类别的全部图像。我们可以看到这里有690张图像在‘yes’类里,也就是戴口罩的一类;有686张图像在‘no’类中,也就是没有带口罩的一类。
The number of images with facemask labelled 'yes': 690The number of images with facemask labelled 'no': 686
这里,我们需要增强我们的数据集,为训练提供更多数量的图像。在数据增强时,我们旋转并翻转数据集中的每幅图像。在数据增强后,我们总共有2751幅图像,其中‘yes’类中有1380幅图像,‘no’类中有1371幅图像。
Number of examples: 2751Percentage of positive examples: 50.163576881134134%, number of pos examples: 1380Percentage of negative examples: 49.836423118865866%, number of neg examples: 1371
我们将我们的数据分割成训练集和测试集,训练集中包含将要被CNN模型训练的图像,测试集中包含将要被我们模型测试的图像。
在此,我们取split_size=0.8,这意味着80%的图像将进入训练集,其余20%的图像将进入测试集。
The number of images with facemask in the training set labelled 'yes': 1104The number of images with facemask in the test set labelled 'yes': 276The number of images without facemask in the training set labelled 'no': 1096The number of images without facemask in the test set labelled 'no': 275
在分割后,我们看到图像已经按照分割的百分比分配给训练集和测试集。
在这一步中,我们将使用Conv2D,MaxPooling2D,Flatten,Dropout和Dense等各种层构建顺序CNN模型。在最后一个Dense层中,我们使用‘softmax’函数输出一个向量,给出两个类中每个类的概率。
model = tf.keras.models.Sequential([tf.keras.layers.Conv2D(100, (3,3), activation='relu', input_shape=(150, 150, 3)),tf.keras.layers.MaxPooling2D(2,2),tf.keras.layers.Conv2D(100, (3,3), activation='relu'),tf.keras.layers.MaxPooling2D(2,2),tf.keras.layers.Flatten(),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(50, activation='relu'),tf.keras.layers.Dense(2, activation='softmax')])model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
在这里,我们使用 ‘adam’ 优化器和‘binary_crossentropy’ 作为我们的损失函数,因为只有两个类。此外,也甚至可以使用MobileNetV2以获得更高的精度。
在构建我们的模型之后,我们创建“train_generator”和“validation_generator”,以便在下一步将它们与我们的模型相匹配。 我们看到训练集中总共有2200张图像,测试集中有551张图像。
Found 2200 images belonging to 2 classes.Found 551 images belonging to 2 classes.
这一步是主要的步骤,我们使用训练集中的图像来训练我们的模型,并使用测试集中的数据来测试我们的训练结果,给出准确率。我们进行了30次迭代,我们训练的输出结果在下面给出。同时,我们可以训练更多的迭代,以获得更高的精度,以免发生过拟合。
history = model.fit_generator(train_generator,epochs=30,validation_data=validation_generator,callbacks=[checkpoint])>>Epoch 30/30[==============================] - 231s 1s/step - loss: 0.0368 - acc: 0.9886 - val_loss: 0.1072 - val_acc: 0.9619
我们看到,在第30个时期之后,我们的模型中训练集的精度为98.86%,测试集的精度为96.19%。 这意味着它是训练结果很好,没有任何过度拟合。
在建立模型后,我们为我们的结果标记了两个概率
[‘0’ 作为‘without_mask’ 和‘1’作为‘with_mask’]。我们还使用RGB值设置边界矩形颜色。 [‘RED’ 代表 ‘without_mask’ 和‘GREEN’ 代表 ‘with_mask]
labels_dict={0:'without_mask',1:'with_mask'}color_dict={0:(0,0,255),1:(0,255,0)}
在此之后,我们打算使用PC的网络摄像头来检测我们是否佩戴口罩。为此,首先我们需要实现人脸检测。在此,我们使用基于Haar特征的级联分类器来检测人脸的特征。
face_clsfr=cv2.CascadeClassifier('haarcascade_frontalface_default.xml')这种级联分类器是由OpenCV设计的,通过训练数千幅图像来检测正面的人脸。代码中需要的.xml文件可以在公众号后台回复“口罩检测”获得。
在最后一步中,我们通过OpenCV库运行一个无限循环程序,使用我们的网络摄像头,在其中我们使用Cascade Classifier检测人脸。代码是webcam = cv2.VideoCapture(0)表示使用网络摄像头。
该模型将预测两类中每一类的可能性([without_mask, with_mask])。基于概率的大小,标签将被选择并显示在我们脸的区域。
此外,还可以下载用于手机和PC的DroidCam 应用程序来使用我们的移动相机,并将代码中的0改为1 webcam= cv2.VideoCapture(1).
测试:
我们来看一下测试的结果
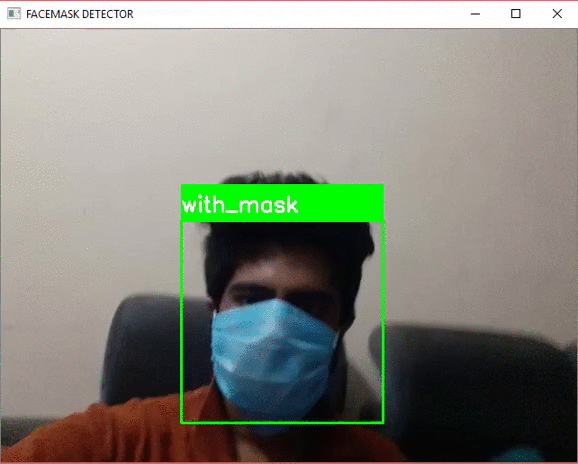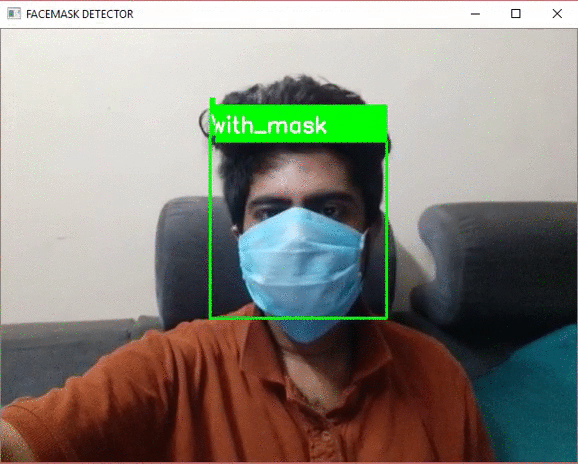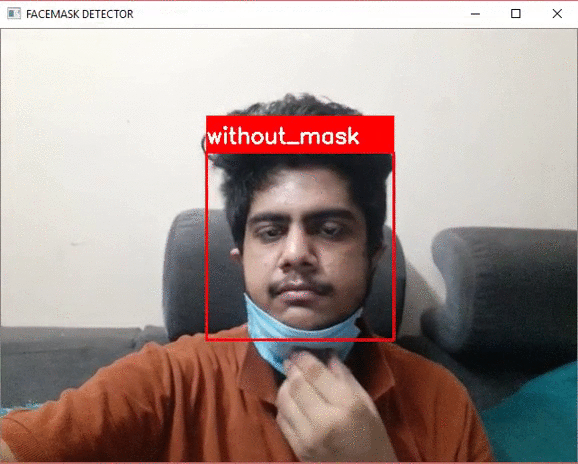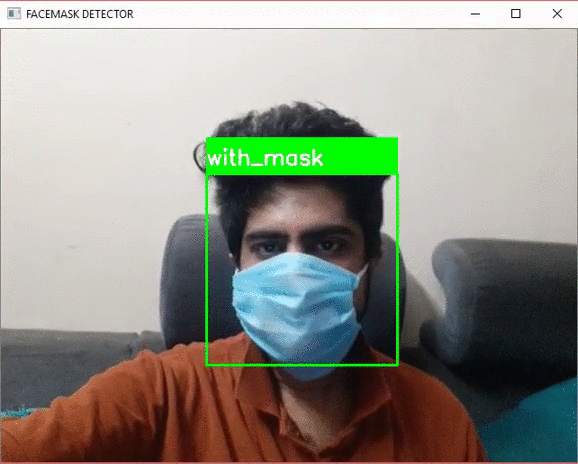
从上面的演示视频中,我们看到模型能够正确地检测是否佩戴面具并在标签上显示相同的内容。
如果小伙伴需要本文的相关代码和文件,可以在公众号后台回复【口罩检测】获得。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~