
YOLOv4 | 用C++ 和OpenCV 实现视频目标检测
转载自 | 我爱计算机视觉
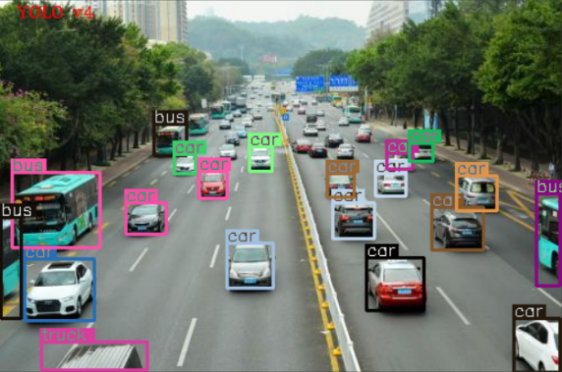
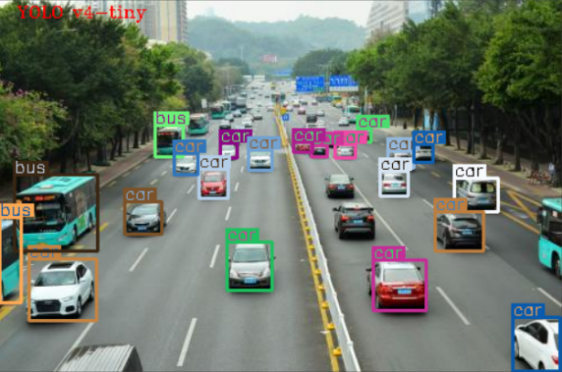
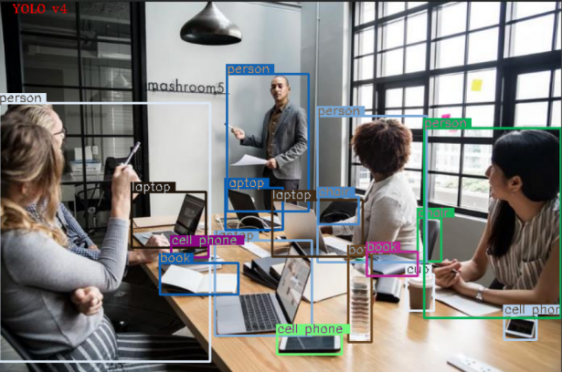
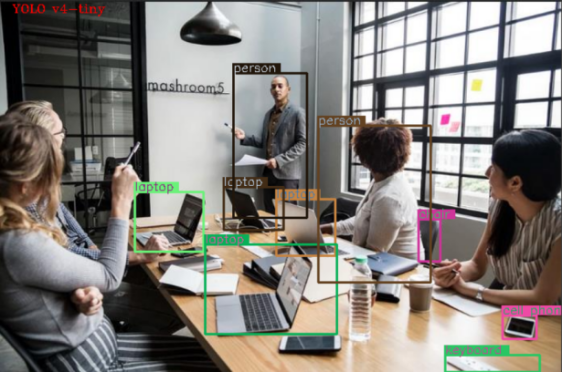
据说,现在很多小区都上线了AI抓拍高空抛物的黑科技,你想不想知道,这类检测视频中目标物的黑科技是怎么实现的呢?这里就一步步来教一下大家如何用C++ 和OpenCV 实现视频目标检测(YOLOv4模型)。
cv::VideoCapture cap;cap.open(0); //打开摄像头//cap.open("TH1.mp4"); //读取视频文件
cv::dnn::Net net = cv::dnn::readNet(config, model, framework);net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
net.forward(outs, outNames); //前向传播
for (size_t i = 0; i < outs.size(); ++i) {data = (float*)outs[i].data;for (int j = 0; j < outs[i].rows; ++j, data += outs[i].cols){scores = outs[i].row(j).colRange(5, outs[i].cols);cv::minMaxLoc(scores, 0, &confidence, 0, &classIdPoint);
void drawPred(cv::Mat &frame,vector<cv::Rect> &boxes,vector<int> &classIds,vector<int> &indices,vector<string> &classNamesVec)

注重理论结合实战
兼顾经典与前沿算法
应用案例翔实
学习路线清晰
✄------------------------------------------------
双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞

评论