
用C++ 和OpenCV 实现视频目标检测(YOLOv4模型)

据说,现在很多小区都上线了AI抓拍高空抛物的黑科技,可以自动分析抛物轨迹,用来协助检查很多不文明行为。
你想不想知道,这类检测视频中目标物的黑科技是怎么实现的呢?
虽然不同场景下的目标检测模型训练不同,但底层技术都是一样的。
这里就一步步来教一下大家如何用C++ 和OpenCV 实现视频目标检测(YOLOv4模型)。
1. 实现思路
读取视频流,载入模型,执行推理,找出所有目标及其位置,最后绘制检测结果。
2. 实现步骤
读取摄像头视频流或本地视频文件:
cv::VideoCapture cap;cap.open(0); //打开摄像头//cap.open("TH1.mp4"); //读取视频文件
载入模型:
cv::dnn::Net net = cv::dnn::readNet(config, model, framework);net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
执行推理:
net.forward(outs, outNames); //前向传播找出所有目标及其位置:
for (size_t i = 0; i < outs.size(); ++i) {data = (float*)outs[i].data;for (int j = 0; j < outs[i].rows; ++j, data += outs[i].cols){scores = outs[i].row(j).colRange(5, outs[i].cols);cv::minMaxLoc(scores, 0, &confidence, 0, &classIdPoint);
绘制检测结果:
void drawPred(cv::Mat &frame,vector<cv::Rect> &boxes,vector<int> &classIds,vector<int> &indices,vector<string> &classNamesVec)

(a)测试图1YOLOv4
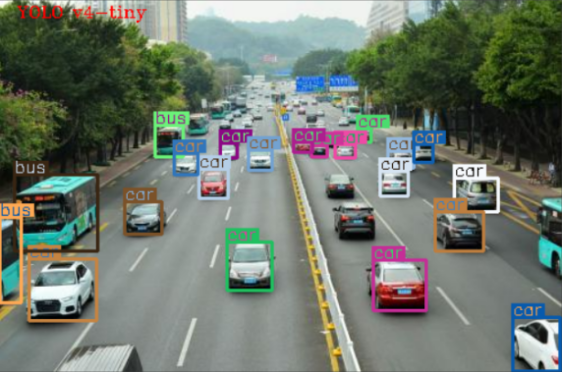
(b)测试图1YOLOv4-tiny
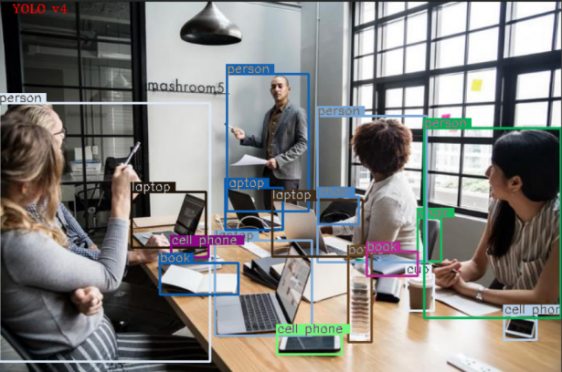
(c)测试图2YOLOv4
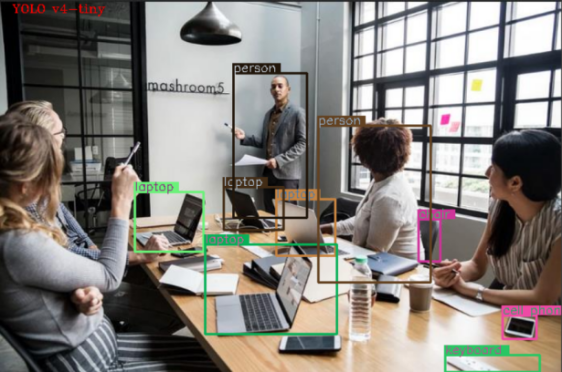
(d)测试图2YOLOv4-tiny
图 YOLOv4与YOLOv4-tiny模型的检测结果
3. 总结
YOLOv4的检测精度优于YOLOv4-tiny。经GPU 加速后,模型推理速度明显提升,YOLOv4 的推理速度提高了约10倍,YOLOv4-tiny的推理速度提高了约4.8倍。
若想了解更多关于视频检测或文本检测的内容,可以阅读《OpenCV 4机器学习算法原理与编程实战》一书。


▊《OpenCV 4机器学习算法原理与编程实战》
朱斌 著
注重理论结合实战
兼顾经典与前沿算法
应用案例翔实
学习路线清晰
本书主要面向OpenCV领域的研究与开发人员,采用原理结合实战的方式,介绍OpenCV 4的机器学习算法模块与深度神经网络模块中的核心算法原理与C++编程实战。全书共10章, 第1~3章, 介绍OpenCV 4的基础知识、基本图像操作和机器学习基础知识;第4~8章,介绍K-means、KNN、决策树、随机森林、Boosting算法和支持向量机等机器学习算法与编程实战;第9~10章,介绍神经网络与深度神经网络的基本原理与编程实战,并提供了不同深度学习模型的部署示例代码。
本书基本聚焦于机器学习在计算机视觉领域的应用,不要求读者具有相应的知识背景,在必要时书中会介绍相关的基本概念。因此,本书既可以作为相关专业学生的实验教材,也可以作为研究人员或工程技术人员的参考资料。
(扫码了解本书详情)
如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐
▼点击阅读原文,获取本书详情~