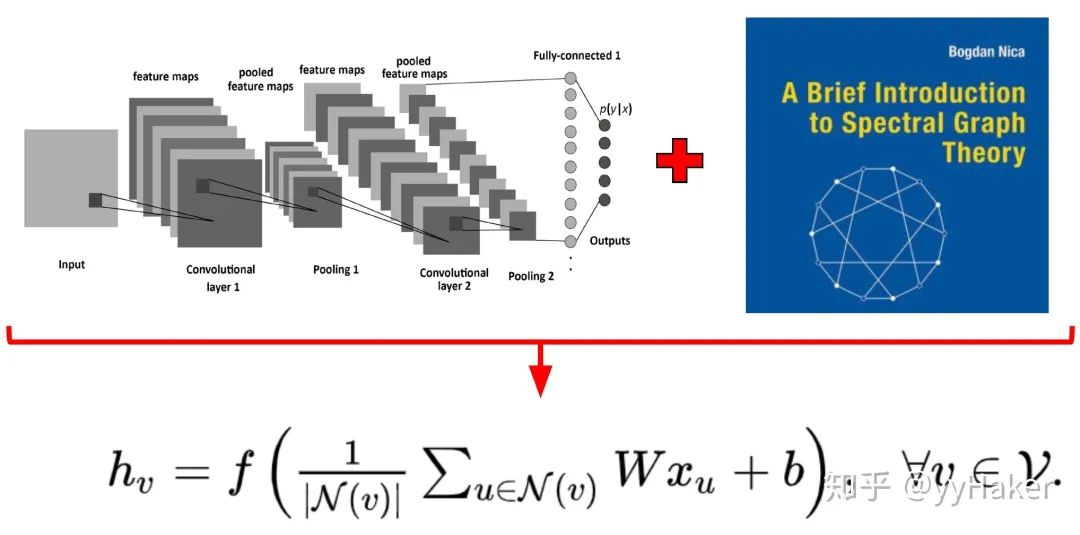
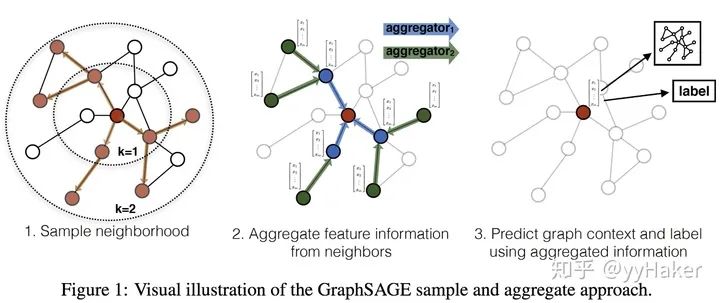
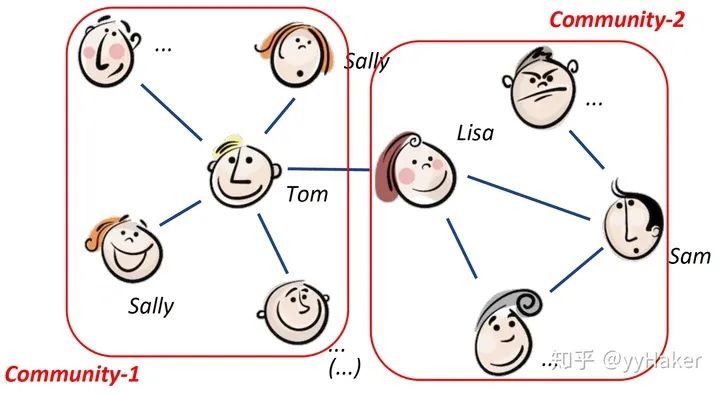
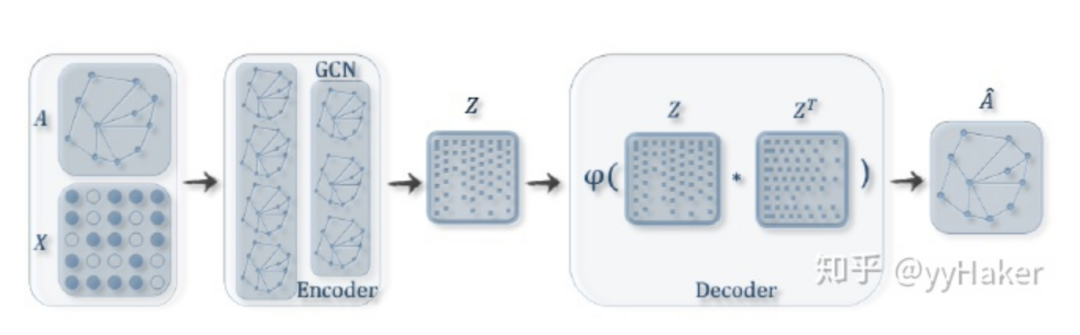
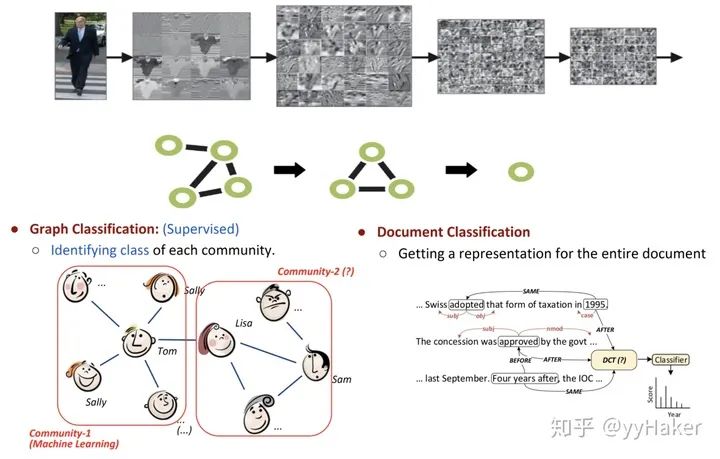
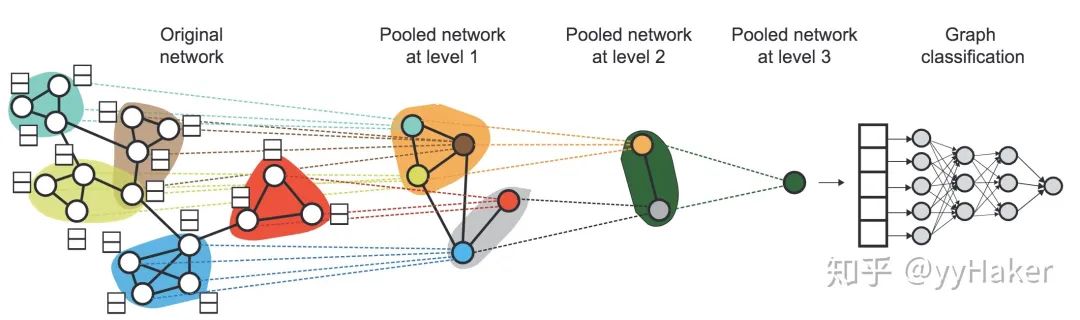
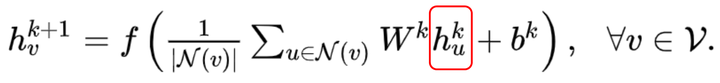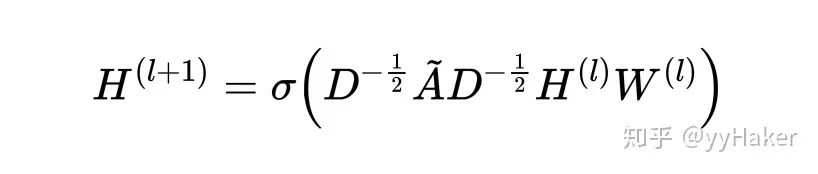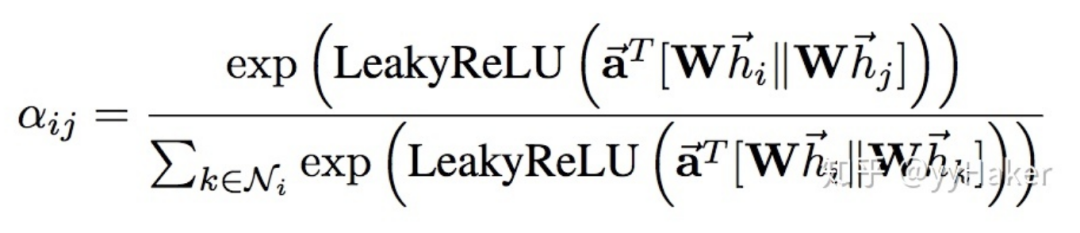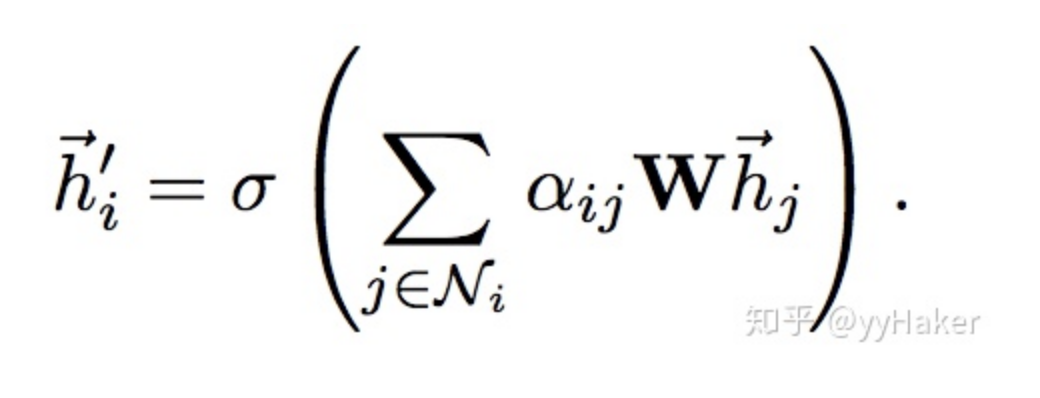【1】^Graph Neural Networks: A Review of Methods and Applications. arxiv 2018 https://arxiv.org/pdf/1812.08434.pdf
【2】^A Comprehensive Survey on Graph Neural Networks. arxiv 2019. https://arxiv.org/pdf/1901.00596.pdf
【3】^Deep Learning on Graphs: A Survey. arxiv 2018. https://arxiv.org/pdf/1812.04202.pdf
【4】^GNN papers https://github.com/thunlp/GNNPapers/blob/master/README.md
【5】^Semi-Supervised Classification with Graph Convolutional Networks(ICLR2017) https://arxiv.org/pdf/1609.02907
【6】^如何理解 Graph Convolutional Network(GCN)?https://www.zhihu.com/question/54504471
【7】^GNN 系列:图神经网络的“开山之作”CGN模型 https://mp.weixin.qq.com/s/jBQOgP-I4FQT1EU8y72ICA
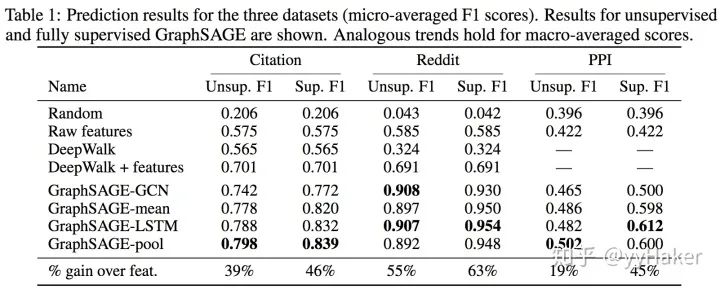
【8】^Inductive Representation Learning on Large Graphs(2017NIPS) https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf
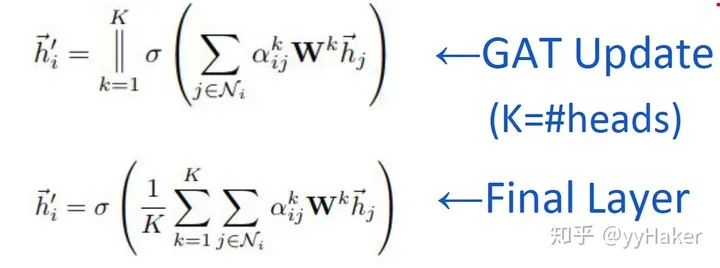
【9】^Graph Attention Networks(ICLR2018) https://arxiv.org/pdf/1710.10903
【10】^Variational Graph Auto-Encoders(NIPS2016) https://arxiv.org/pdf/1611.07308
【11】^VGAE(Variational graph auto-encoders)论文详解 https://zhuanlan.zhihu.com/p/78340397
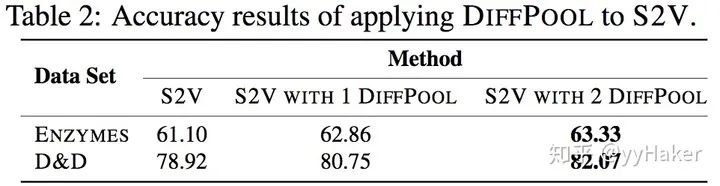
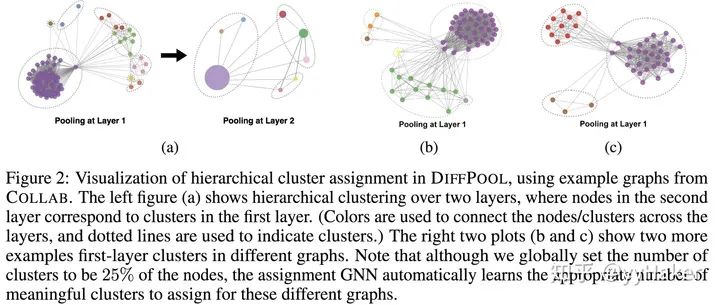
【12】^Hierarchical Graph Representation Learning withDifferentiable Pooling(NIPS2018) https://arxiv.org/pdf/1806.08