一文读懂Image matting(图像抠图)

导读
本文为图像抠图的入门版介绍,作者详细阐述了图像抠图的三种方法并介绍了一个图像抠图应用仓库,附有安装以及使用步骤详解。
今天礼拜六休息一天,闲着没事干想给证件照换张背景颜色。上网随手搜了下发现是属于图像抠图的领域,本想着下个项目来玩玩,没想到很多还要收费,要不然就是要会员。本着敬业的精神(为了省钱),特地花费一天研究下什么是图像抠图。
1. What's the Image Matting?
图像抠图(Image Matting),是指从图像中提取出我们所感兴趣的前景目标,同时过滤掉背景部分。一张图像可以简单的看成是由两部分组成,即前景(Foreground)和背景(Background)。简单来说,抠图,就是将一张给定图像的前景和背景区分开来。

版权所有,请勿盗用
假设原始图像用 来表示, 表示对应的Alpha通道, 和 分别表示对应的前景图像和背景图像。那么,如上所示,我们可以看出,一张具有RGBA通道的图像,它可以分解为如下几部分的组合,即
上述公式最早出自于《Blue screen matting》[9],由Smith, Alvy Ray, and James F. Blinn两人提出。Smith也算是图形学的先驱,同时也是HSV颜色空间的作者,据说乔帮主第一款Mac的图像界面就是他所设计的。Smith在1978年还创建了的一种著名的颜色空间HSV,也称六角锥体模型(Hexcone Model)注:HSV即Hue(色调色相)、 Saturation(饱和度、色彩纯净度)和Value(明度)。关于更多内容大家有兴趣的可以自行查阅。
当 为0时,图像为背景图像;当 为1时,图像为前景图像。因此,对于图像中的每个像素点,均可以表示为一个类似于上述的线性方程组。因此,抠图的主要目标是根据原始输入图像,来获得前景、背景和透明度。
Alpha通道,指的是一张图片的透明度。比如真彩色图像,它是24bit,含有RGB三彩色通道,每个通道占8位。在这个基础上,我们可以给它扩充到32bit,增加一个独立的通道,即α通道(黑白灰通道),来控制图片显示的透明度,从而得到RGBA四个通道。其中,值越大,图像的透明度越低。我们知道二进制下的8位可以表示的范围是0-255,即255代表不透明(白色),0表示完全透明(黑色),中间值则为半透明(灰色);因此只有当α=255时叠加到原始图像上才会显示其真正的颜色。一般来说,TIFF、PNG和GIF均是支持Alpha通道的,我们经常会利用Alpha通道的性质来实现抠图或者获得具有透明背景的图片。
2. Methods
2.1 Bayesian-based matting
贝叶斯抠图是一种交互式的输入抠图,其中,对于一些像素点F(前景)、B(背景)及图片C的alpha值我们是已知的。我们的目标便是根据这些已知的值使求解出来的未知值F、B、C和alpha满足最大概率。
argmax是一种函数,用于对函数求参数(集合)的函数。求比如对于argmax(f(x)),可以简单理解为使得函数f(x)取得最大值所对应的变量x,如果由多个变量均能满足条件,则为变量点x的集合。
Bayesian Formula
这里 。对于多个概率连乘的形式,我们一般会求对数,将其转化为加法方便运算。因此,我们需要求解出使上述公式概率最大化的最优参数F、B和alpha的数值。
Grab cut算法是基于高斯混合模型对已知的前景和背景对象进行建模。为了保证空间的连续性,基于贝叶斯的方法采用的是对每个未知像素的N个邻域点进行聚类。对于上述公式,右边第一项反映的是图像颜色被赋予F、B和alpha值的可能性。因此,为了获得一个更优解,我们应该保持抠图方程不变,即第一项可以建模为:
注意到,这里 是一个可调参数,它反映了与抠图假设的预期偏差值。
对于公式中其它的三项,则分别代表了前景、背景和α通道分布上的先验概率,这里我们可以根据用户输入的已知像素点,计算出当前颜色值属于前景的概率。
是前景、背景和α分布上的先验概率。我们可以通过用户输入的已知像素来计算一个颜色值属于前景的概率。如此一来,我们便可以将高斯分布拟合到每个强度值的集合。对于颜色B,我们可以根据以下公式进行估计:
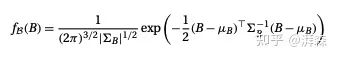
Gaussian distribution
上述其实是一个高斯分布的近似公式。这里均值和标准差分别为:
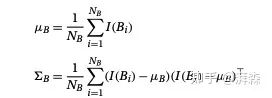
其实,这些都是可以算出来的。这样一来,我们便可以得到前景和背景的先验分布估计:
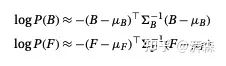
对于最后一项,即 ,可以假设它是一个常数项。这样我们可以通过概率最大化方程求解偏导数并将其置为0即可,所以可以直接忽略掉。下面,我们通过最熟悉的联立方程组,便可以解决贝叶斯抠图问题。:
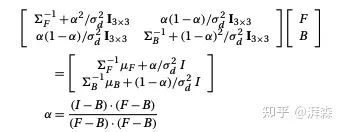
最后,让我们来梳理下整个流程的步骤吧:
对每个像素的alpha值进行预估; 交替求解方程得到前景F和背景B; 固定F和B的值,联立方程求解到alpha的值; 重复上述步骤,直至这三个变量值(F、B and Alpha)收敛。
2.2 Laplacian-based matting
首先,假设有一个小窗口 ,我们考虑其周围的每个像素 :
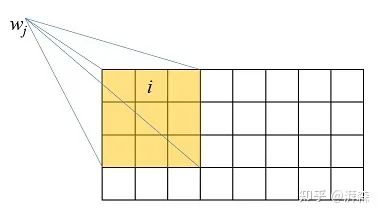
那么在这个窗口上,我们可以近似地建立第1节所述的方程关系,即:
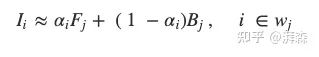
接下来,化简、移项,可得:
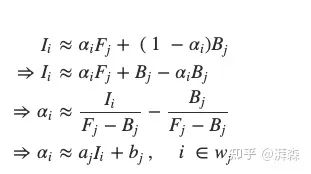
为了简要表述,这里我们令:
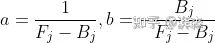
从上面公式也可以看出来,我们近似的将其表达成一个线性方程,参数是a和b。假设一个窗口内的α值和颜色是相关的,我们可以将其延申为一个带成本函数(cost function)的抠图问题:
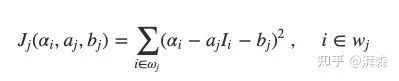
Laplace's equation
由于整张图像是由许多重叠的窗口所组成的,所以整体的目标函数可以表示为窗口的集合:
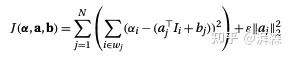
N is the number of windows
下面我们要做的工作便是最小化成本函数J,来寻找最佳的 以及每一个像素点 所对应的窗口 的系数值 和 。为了防止0值,可以引入正则化,即对应公式右边的偏差项。根据经验值,当所有的颜色通道像素值范围为[0, 1]时,我们可以将 设置为1e-7。
接下来,我们将上述公式写成矩阵的形式:
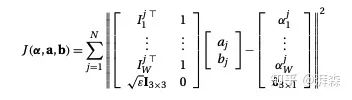
再简化下,可以写成:
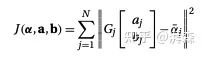
假设这个矩阵是已知的,那么这个向量即为一个常量,我们可以单独将 的方程最小化为一个标准的线性系统:
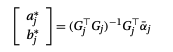
对于给定的对于给定的α值,每个窗口中最优的a和b是关于α的线性函数。当我们把上式代入原式得到:

注意,这里 表示单位矩阵,其维度等于窗口大小。通过代数运算,我们可以计算出拉普拉斯算子中的元素:
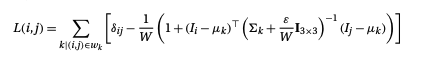
其中 和 是第k个窗口颜色的均值和协方差矩阵,而 是克罗内克尔函数。
Kronecker delta,即克罗内克函数,是一个二元函数,是由德国数学家利奥波德·克罗内克所提出来的。克罗内克函数的自变量一般时两个整数,当两者相等时输出为1,否则为0。
下面,根据当前像素点是属于前景像素或者背景像素,给出两个约束条件:
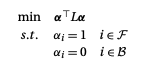
通过使用拉格朗日乘数法求解这个问题,首先建立拉格朗日函数:
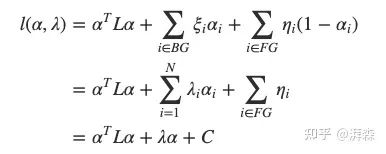
拉格朗日乘数法是一种寻找变量受一个或多个条件所限制的多元函数的极值的方法。
到这里就好办了,把高数用起来哈哈。求导,令其等于0,完美解决:
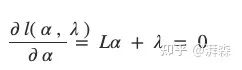
最后,我们便能将问题转化为线性方程组进行解决即可:
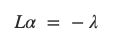
2.3 deep learning-based matting
传统算法除了上述两种,其实还有不少,比如基于KNN的matting等。由于篇幅内容就不展开了,有兴趣的可以参考下相关领域大佬[10]发表的综述文章。下面介绍下深度学习相关的抠图方法。基于深度学习的抠图算法也属于图像分割(Image Segmentation)的范畴,只不过是一种软分割。今天主要介绍的是CVPR 2020上的一篇抠图相关的文章——U2-Net[6],框架图如下所示:
硬分割(Hard Segmentation):一个像素点要么是前景,要么是背景;
软分割(Soft Segmentation):一个像素点除了是前景和背景,还可能使由两者共同决定
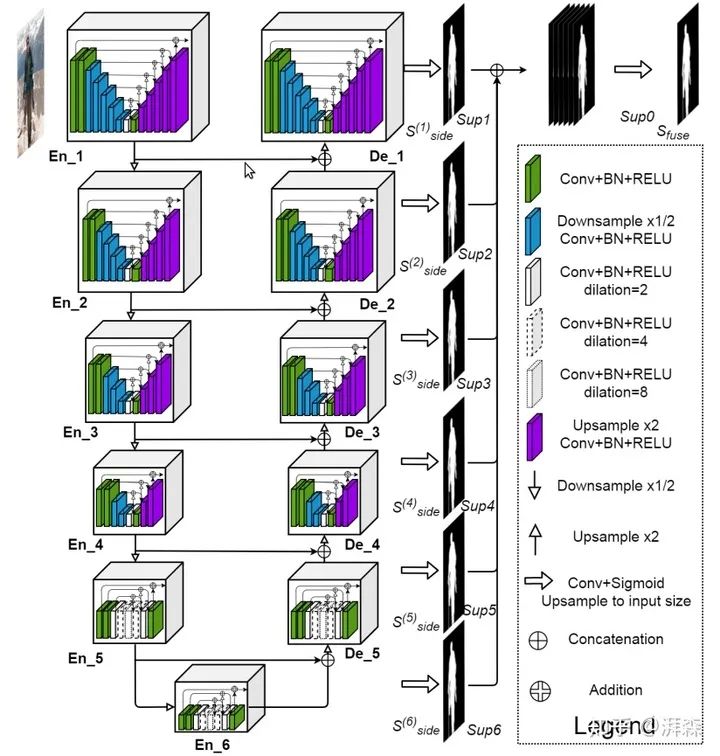
Schematic diagram of U2-Net framework
emmm,没错!就是多个U-Net的的级联,将U-Net视为一个独立的特征提取模块,类似于Residual block。U2-Net由于抠图效果超群,思想简单,效率又高,一提出在Reddit上就被热议,不然我们怎么能关注到它呢?
Reddit是一个集娱乐、社交及新闻的网站, 大家有空也可以多关注关注。
好了,废话有点多,言归正传。在介绍U2-Net时我们先简单的回顾下U-Net。U-Net是和FCN在同一个时期出的产物,一个主攻数据量大样本较为简单的自然图像领域,另一个则主攻数据量小样本较为困难的医学图像领域,只不过FCN比U-Net早提出。当然,后面还出了还多基准网络,比如提拉米苏网络,将U-Net中的concatenate操作替换为element-wise sum操作。此外,还有类似的很多网络,不多大同小异。U-Net可以看出是继承了FCN的思想,为了进一步地改善FCN分割粗糙的特点,U-Net在FCN的基础上,在编码器和解码器之间引入了长距离跳跃连接(Long-range skip connection),通过结合来自底层的细节,有效的弥补了因下采样操作过程中空间信息缺失,帮助网络恢复更加精确的定位,这对于医学图像分割、遥感图像分割以及抠图这种对细节非常看重的密集型分割任务来说是至关重要的。当然U-Net也有很多可以改进的地方,下面列举一些关键的突破口:
特征提取。关于特征提取能力,原始的U-Net用的是两个连续的plain卷积来提取特征。我们可以将其替换为Residual block、Recurrent block、Dilated conv、Dynamid conv等等。除此之外,还可以自己根据任务来设计。笔者前段时间也自行尝试设计了一个,在参数量和计算量更少的情况下提高了2-3个点。其实现在顶会顶刊上出现的绝大多数卷积都大同小异:如何在保证时间或空间复杂度的情况,尽可能地增强特征的表示能力。关于节省复杂度,我们可以结合到利用基(Radix)的优势以及1x1卷积之类的操作进行降维再生维的操作。而增强特征的表示能力也有好多种方式,最核心的两点便是感受野和信息的有效利用。 特征抑制。许多图像在成像过程中由于外部环境的因素总是不可避免的会遭到许多背景噪声的干扰。不知道大家观察到,U-Net类型的网络在引入跳跃连接操作时,来自底层的信息如果我们直接利用,这时候或多或少会伴随许多噪声的干扰。关于抑制或去除噪声,主要可以通过在数据上或模型上进行改进。数据改进的话一般时通过一些CLAHE、Gamma增加等操作来增强对比度和抑制噪声,或者对于一些肉眼可见的噪声可以直接通过crop操作来去除。你会发现很多竞赛获胜选手的方案里边都会花费大力气对数据进行清洗,纯净的数据往往是获得高分性能的关键。而模型上的改进也有不少,比如可以借助光流的思想通过高级特征的语义信息来校准低级特征的分布。比较常规的方法可以是通过一些类似于注意力的方式来进行背景抑制,使用注意力方法可以对前景特征进行加权输出使模型更加关注,另一方面降低背景特征的权重,不失为一种良好的解决方案。关于不同的注意力方法笔者也做了一个总结,可以参考下这篇文章:
特征融合。特征融合旨在融合尽可能多的信息来获得更具有判别力的特征表示。一般可分为模块内的特征融合以及模块间的特征融合。这里的模块可以理解为特征提取器,好比如Residual block和Dense block,形式上可以看成是将前一级的信息和后一级或多级的信息融合起来,以加强信息的传递。模块间的融合方式可以参考深监督的形式,本文的U2Net就利用到了多层级(multi-level)的融合,来学习更多的语义表示,获得更加精确化的分割结果。再比如UNet++,直接再编解码器之间进行多层级融合。又或者HR-Net,将高、低分辨率特征的信息进行融合。当然,并不是说融合越多的信息越好,毕竟不同层级的特征之间存在一个语义偏差(bias)。顺着这一点我们又可以做很多工作,比如给不同层级的特征加不同的权重,设置几个超参数让网络按照既定的规则进行融合。如果不想调参,再改进的话也不是不可以。
说回U2-Net。其实上面分析了很多,能吸收的基本看一眼框架图一眼就秒懂创新点。非要重述的话,无非就是在保证计算效率的同时,堆叠已有的经过验证切实有效的模块来融合具有不同尺度的感受野,捕获更加充足的上下文信息,最后再通过融合多层级的特征获得一个更加精细化的更具有判别力的特征。虽说简单,不过笔者本人信奉“大道至简”的原则,越有效的东西往往是越简洁的,成天写一堆花里胡哨的话是秀给Reviewer看的,大家不用过度当真,只需取其精华,去其糟粕即可。
3. How to implement Image Matting?
写了这么多理论(废话),关键还是要用一用才舒坦。先给出U2-Ne的源github链接:NathanUA/U-2-Net。这是原作者的仓库链接,代码看起来也很好理解。除了图像抠图以外,作者还列出了其它研究人员很多基于U2-Net开发的有趣应用,比如人像绘画、肖像生成等,有兴趣的可以自己去源仓库看看。不过今天给大家介绍另外一个图像抠图应用仓库,我们也不浪费时间重复造轮子了,直接用rembg来生成即可。
rembg是一个外国小伙子基于U2-Net用python和flask开发出来的背景移除工具。
好了,都到这里了,好人做到底,下面给出小白保姆级教程。注意:下面教程是针对Wins操作系统如何完美运行rembg,Linux或Mac OS系统由于基本没什么坑直接安装即可。
3.1 Miniconda
第一步是安装Miniconda,顺手整理一波常用的配置指令,详情可参考这篇:
Anaconda下conda的创建、激活、退出、删除、配置虚拟环境以及pip的相关操作_Jack_0601的博客
https://blog.csdn.net/weixin_43509263/article/details/112097511
3.2 Pakages
第二步是安装相关包,笔者电脑显卡是基于CUDA 10.1版本,下面给出具体的操作步骤:
下载源代码:
如果本地有安装git,可以直接打开cmd窗口,进入到要保存文件的目录,运行:
git clone https://github.com/danielgatis/rembg.git
如果下载速度堪忧,可以直接打开github,复制网址,直接用迅雷下载压缩包,解压放到本地。
按下快捷键Win+S,输入Anaconda Prompt,打开窗口新建一个虚拟环境:
conda create -n matting python=3.7 -y
激活环境:
conda activate matting
安装pytorch:
大家先上pytorch官网查看自己适配的版本,比如我的:
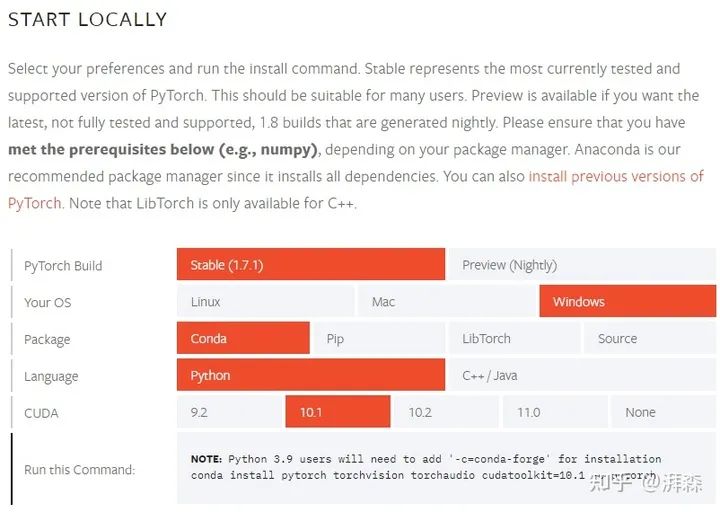
可以把你的版本号对应改下,使用以下指令进行下载:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda install pytorch torchvision torchaudio cudatoolkit=10.1
如果下载速度太慢,或者网络不稳定,由于Pytorch等包太大,很大概率会失败。如果出现:An HTTP error occurred when trying to retrieve this URL.错误,可以参考下这篇博客(https://blog.csdn.net/weixin_36465540/article/details/111242733)。
安装requirements.txt文件下的pkgs
将以下包替换掉requirements.txt这个文件下的包:
flask==1.1.2
numpy==1.19.3
pillow==8.0.1
scikit-image==0.17.2
waitress==1.4.4
tqdm==4.51.0
requests==2.24.0
scipy==1.5.4
pymatting==1.1.1
filetype==1.0.7
hsh==1.1.0
opencv-python==4.5.1.48
进入到requirements.txt文件所在目录,执行一键安装指令,体验飞一般的下载安装速度:
pip install -r requirements.txt -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
下载训练好的U2-Net权重文件:
百度网盘链接:https://pan.baidu.com/s/11KD_r5dY-YOlOL9AE9PorQ
提取码:6qjo
下载后在根目录下新建一个u2net目录,并将权重文件放置到该文件下,具体可参考:
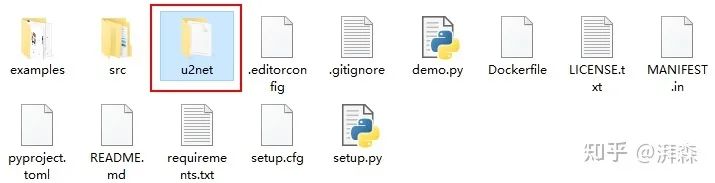
3.3 Running
测试图像
这个Project作者仅提供抠图,而且作者并没有提供script,随便写了个,不会写的可以参考下我的demo.py文件。将你想要测试的图像放置到examples文件目录下,具体文件目录和名称可自行修改:
"""
demo.py
authored by @湃森 [https://www.zhihu.com/people/peissen]
"""
import io
import os
import cv2
import numpy as np
from PIL import Image, ImageFile
from src.rembg.bg import remove
ImageFile.LOAD_TRUNCATED_IMAGES = True
def show(img):
cv2.imshow("img", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def get_mask(img):
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 图像灰度化处理
img_gray = cv2.GaussianBlur(img_gray, (3, 3), 0) # 用(3, 3)的高斯核进行模糊化处理
img_mask = cv2.threshold(img_gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1] # 使用自适应阈值二值化处理
return img_mask
def get_path(file_path, file_name, extension):
"""
:param file_path: 文件路径
:param file_name: 文件名
:param extension: 扩展名
:return:
"""
total_name = file_name + extension
path = os.path.join(file_path, total_name)
return path
def get_background(img_src, img_1_alpha):
"""
:param img_src: 源图像
:param img_1_alpha: 1-alpha
:return: 背景图像
"""
img_src_np = np.array(img_src)
img_alpha_np = np.array(img_1_alpha)
img_alpha_np = np.expand_dims(img_alpha_np, axis=2)
img_merge = np.concatenate((img_src_np, img_alpha_np), axis=2)
res = Image.fromarray(img_merge)
return res
def get_foreground(path):
"""
:param path: 源文件输入路径
:return: 前景图像
"""
file = np.fromfile(path) # 用numpy加载源图像
img_fg = remove(file) # 实现抠图
img_rgba = Image.open(io.BytesIO(img_fg)).convert("RGBA") # 转换为RGBA的图像格式
assert img_rgba.mode == 'RGBA' # 判断是否成功转换
return img_rgba
def joint_img_horizontal(img_list):
w, h = img_list[0].size
res = Image.new('RGBA', (w * len(img_list), h))
for idx, img in enumerate(img_list):
res.paste(img, box=(idx * w, 0))
return res
def background_color_transform(img_src_path, img_alpha_path, img_show=False):
# 获取二值图像
img_alpha = cv2.imread(img_alpha_path)
img_mask = get_mask(img_alpha)
if img_show:
show(img_mask)
# 加载源图像
img_src = cv2.imread(img_src_path, cv2.IMREAD_COLOR)
if img_show:
show(img_src)
# 背景颜色替换
# 注意,这里替换的颜色通道是(B,G,R)
img_src[img_mask == 0] = (0, 0, 255)
if img_show:
show(img_src)
return img_src
def main():
# 文件路径
file_path = './examples' # 文件所在目录
file_name = 'photo' # 文件名
input_path = get_path(file_path, file_name, '.jpg') # 源图像
background_path = get_path(file_path, 'back1', '.jpg') # 背景图
out_alpha_path = get_path(file_path, file_name, '_alpha.png') # alpha通道
out_1_alpha_path = get_path(file_path, file_name, '_1-alpha.png') # 1-alpha通道
out_fg_path = get_path(file_path, file_name, '_fg.png') # 前景图
out_bg_path = get_path(file_path, file_name, '_bg.png') # 背景图
out_joint_path = get_path(file_path, file_name, '_joint.png') # 多图拼接
out_bg_color_trans_path = get_path(file_path, file_name, '_bg_color_trans.png') # 背景替换
out_synthesis_path = get_path(file_path, file_name, '_synthesis.png') # 背景替换
# 加载源图像
img_src = Image.open(input_path)
# 获取并保存前景图像
img_fg = get_foreground(input_path)
# print(len(img_fg.split())) = 4
img_fg.save(out_fg_path)
# 获取并保存前景图像的alpha通道
img_alpha = img_fg.split()[-1] # 通道分离,R/G/B/A
# print(len(img_alpha.split())) = 1
img_alpha.save(out_alpha_path)
# 获取并保存对应的1-alpha通道
img_1_alpha = img_alpha.point(lambda i: 255 - i)
# print(len(img_1_alpha.split())) = 1
img_1_alpha.save(out_1_alpha_path)
# 获取并保存背景图像
img_bg = get_background(img_src, img_1_alpha)
img_bg.save(out_bg_path)
# 拼接图像
img_list = [img_src, img_fg, img_alpha, img_bg, img_1_alpha]
img_total = joint_img_horizontal(img_list)
img_total.save(out_joint_path)
# 背景迁移
img_bg_color_trans = background_color_transform(input_path, out_alpha_path, img_show=False)
cv2.imwrite(out_bg_color_trans_path, img_bg_color_trans)
if __name__ == '__main__':
main()
如果不出意外,可以得到结果:

源图地址:https://www.google.com.hk/url?sa=i&url=https%3A%2F%2Fwww.pi7.com%2Farticle%2Fv34951.html&psig=AOvVaw199Fu3dgbSuqkrloA8fT36&ust=1610877033087000&source=images&cd=vfe&ved=0CAIQjRxqFwoTCIDU6N-WoO4CFQAAAAAdAAAAABAD

要想图方便的话,作者使用了flask框架,提供了web端的接口测试,可以在终端执行rembg-server启动后台的相关服务。具体运行指令可以根据官方提供的op进行测试,我自己写了个还没用过,不过应该得到的结果是一样的。不过好像只提供抠图,其它要自己写脚本来操作。事先声明,未经本人允许不得私自转载。
有问题的可在评论区反馈,谢绝私聊问一堆问题,下面根据大家反馈的常见错误更新如下:
Attempted to compile AOT function without the compiler used by `numpy.distutils` present. Cannot find suitable msvc.
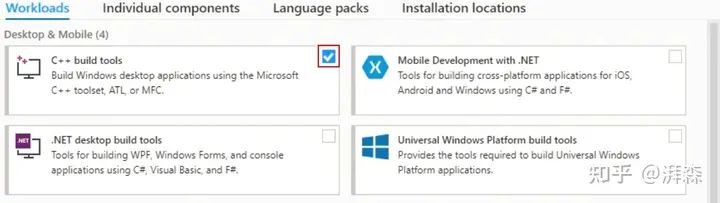
这个问题是因为本机还没有装C++ compiler,进入visualstudio官网(https://visualstudio.microsoft.com/zh-hans/downloads/)下载:

展开,选择Visual Studio 2019生成工具,点击下载:

一路默认,到这里勾选C++ bulid tools即可,继续安装,重启机器即可。
Reference
 End
End
声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。
 往期推荐
往期推荐