
视觉导航定位系统工作原理及过程
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自 | 新机器视觉
当今,由于数字图像处理和计算机视觉技术的迅速发展,越来越多的研究者采用摄像机作为全自主用移动机器人的感知传感器。这主要是因为原来的超声或红外传感器感知信息量有限,鲁棒性差,而视觉系统则可以弥补这些缺点。而现实世界是三维的,而投射于摄像镜头(CCD/CMOS)上的图像则是二维的,视觉处理的最终目的就是要从感知到的二维图像中提取有关的三维世界信息。
简单说来就是对机器人周边的环境进行光学处理,先用摄像头进行图像信息采集,将采集的信息进行压缩,然后将它反馈到一个由神经网络和统计学方法构成的学习子系统,再由学习子系统将采集到的图像信息和机器人的实际位置联系起来,完成机器人的自主导航定位功能。

(1)摄像头标定算法:2D-3D映射求参。
传统摄像机标定主要有 Faugeras 标定法、Tscai 两步法、直接线性变换方法、张正友平面标定法和 Weng迭代法。自标定包括基于 Kruppa 方程自标定法、分层逐步自标定法、基于绝对二次曲面的自标定法和 Pollefeys 的模约束法。视觉标定有马颂德的三正交平移法、李华的平面正交标定法和 Hartley 旋转求内参数标定法。
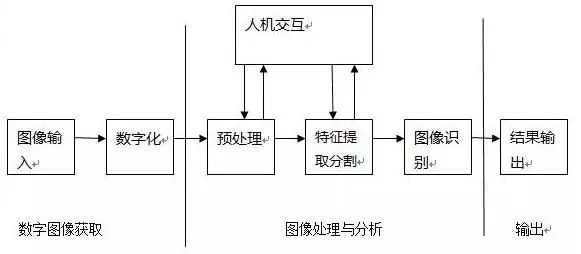
(2)机器视觉与图像处理:
a.预处理:灰化、降噪、滤波、二值化、边缘检测。。。
b.特征提取:特征空间到参数空间映射。算法有HOUGH、SIFT、SURF。
c.图像分割:RGB-HIS。
d.图像描述识别
也可以使用单目视觉和里程计融合的方法。以里程计读数作为辅助信息,利用三角法计算特征点在当前机器人坐标系中的坐标位置,这里的三维坐标计算需要在延迟一个时间步的基础上进行。根据特征点在当前摄像头坐标系中的三维坐标以及它在地图中的世界坐标,来估计摄像头在世界坐标系中的位姿。这种降低了传感器成本,消除了里程计的累积误差,使得定位的结果更加精确。此外,相对于立体视觉中摄像机间的标定,这种方法只需对摄像机内参数进行标定,提高了系统的效率。
(4)定位算法基本过程:
简单的算法过程,可基于OpenCV进行简单实现。
输入
通过摄像头获取的视频流(主要为灰度图像,stereo VO中图像既可以是彩色的,也可以是灰度的 ),记录摄像头在t和t+1时刻获得的图像为It和It+1,相机的内参,通过相机标定获得,可以通过matlab或者opencv计算为固定量。
输出
计算每一帧相机的位置+姿态
基本过程
1.获得图像It,It+1
2.对获得图像进行畸变处理
3.通过FAST算法对图像It进行特征检测,通过KLT算法跟踪这些特征到图像It+1中,如果跟踪特征有所丢失,特征数小于某个阈值,则重新进行特征检测
4.通过带RANSAC的5点算法来估计两幅图像的本质矩阵
5.通过计算的本质矩阵进行估计R,t
6.对尺度信息进行估计,最终确定旋转矩阵和平移向量
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~