
GPU起源、工作原理及计算库


导读:GPU缩写为Graphics Processing Unit的,一般称为视觉处理单元。GPU被广泛用于嵌入式系统、移动电话、个人电脑、工作站和电子游戏解决方案当中。现代的GPU对图像和图形处理是十分高效率的,这是因为GPU被设计为很高的并行架构这样使得比通用处理器CPU在大的数据块并行处理算法上更具有优势。
《GPU高性能计算概述》
《GPU深度学习基础介绍》
《OpenACC基本介绍》
《CUDA CC 编程介绍》
《CUDA Fortr基本介绍》
1、GPU的起源
1985年 8月20日 ATi公司成立,同年10月ATi使用ASIC技术开发出了第一款图形芯片和图形卡,1992年 4月 ATi发布了 Mach32 图形卡集成了图形加速功能,1998年 4月 ATi被IDC评选为图形芯片工业的市场领导者,但那时候这种芯片还没有GPU的称号,很长的一段时间ATI都是把图形处理器称为VPU,直到AMD收购ATI之后其图形芯片才正式采用GPU的名字。
NVIDIA公司在1999年发布GeForce 256图形处理芯片时首先提出GPU的概念。从此NVIDIA显卡的芯片就用这个新名字GPU来称呼。GPU使显卡削减了对CPU的依赖,并执行部分原本CPU的工作,尤其是在3D图形处理时。GPU所采用的核心技术有钢体T&L、立方环境材质贴图与顶点混合、纹理压缩及凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬体T&L技术能够说是GPU的标志。
2、工作原理
2.1、GPU工作流程简介
GPU的图形(处理)流水线完成如下的工作:(并不一定是按照如下顺序):
顶点处理:这阶段GPU读取描述3D图形外观的顶点数据并根据顶点数据确定3D图形的形状及位置关系,建立起3D图形的骨架。在支持DX8和DX9规格的GPU中,这些工作由硬件实现的VertexShader(定点着色器)完成。
光栅化计算:显示器实际显示的图像是由像素组成的,我们需要将上面生成的图形上的点和线通过一定的算法转换到相应的像素点。把一个矢量图形转换为一系列像素点的过程就称为光栅化。例如,一条数学表示的斜线段,最终被转化成阶梯状的连续像素点。
纹理帖图:顶点单元生成的多边形只构成了3D物体的轮廓,而纹理映射(texturemapping)工作完成对多变形表面的帖图,通俗的说,就是将多边形的表面贴上相应的图片,从而生成“真实”的图形。TMU(Texturemapping unit)即是用来完成此项工作。
像素处理:这阶段(在对每个像素进行光栅化处理期间)GPU完成对像素的计算和处理,从而确定每个像素的最终属性。在支持DX8和DX9规格的GPU中,这些工作由硬件实现的Pixel Shader(像素着色器)完成最终输出,由ROP(光栅化引擎)最终完成像素的输出,1帧渲染完毕后,被送到显存帧缓冲区。
在GPU出现之前,CPU一直负责着计算机中主要的运算工作,包括多媒体的处理工作。CPU的架构是有利于X86指令集的串行架构,CPU从设计思路上适合尽可能快的完成一个任务。
但是如此设计的CPU在多媒体处理中的缺陷也显而易见:多媒体计算通常要求较高的运算密度、多并发线程和频繁地存储器访问,而由于X86平台中CISC(Complex Instruction Set Computer)架构中暂存器数量有限,CPU并不适合处理这种类型的工作。
以Intel为代表的厂商曾经做过许多改进的尝试,从1999年开始为X86平台连续推出了多媒体扩展指令集SSE(Streaming SIMD Extensions)的一代到四代版本,但由于多媒体计算对于浮点运算和并行计算效率的高要求,CPU从硬件本身上就难以满足其巨大的处理需求,仅仅在软件层面的改并不能起到根本效果。
对于GPU来说,它的任务是在屏幕上合成显示数百万个像素的图像,也就是同时拥有几百万个任务需要并行处理,因此GPU被设计成可并行处理很多任务,而不是像CPU那样完成单任务。
因此CPU和GPU架构差异很大,CPU功能模块很多,能适应复杂运算环境;GPU构成则相对简单,目前流处理器和显存控制器占据了绝大部分晶体管。
CPU中大部分晶体管主要用于构建控制电路(比如分支预测等)和Cache,只有少部分的晶体管来完成实际的运算工作。而GPU的控制相对简单,且对Cache的需求小,所以大部分晶体管可以组成各类专用电路、多条流水线,使得GPU的计算速度有了突破性的飞跃,拥有了更强大的处理浮点运算的能力。

图2-1 CPU和GPU架构
从硬件设计上来讲,CPU 由专为顺序串行处理而优化的几个核心组成。另一方面,GPU则由数以千计的更小、更高效的核心组成,这些核心专为同时处理多任务而设计。
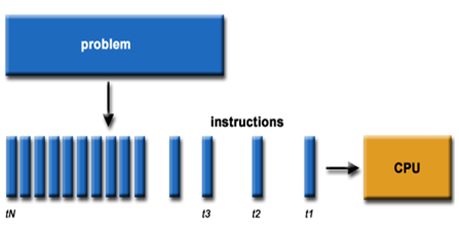
图2-2 串行运算示意图

图2-3 并行运算示意图
通过上图我们可以较为容易地理解串行运算和并行运算之间的区别。传统的串行编写软件具备以下几个特点:要运行在一个单一的具有单一中央处理器(CPU)的计算机上;一个问题分解成一系列离散的指令;指令必须一个接着一个执行;只有一条指令可以在任何时刻执行。
而并行计算则改进了很多重要细节:要使用多个处理器运行;一个问题可以分解成可同时解决的离散指令;每个部分进一步细分为一系列指示;每个部分的问题可以同时在不同处理器上执行。提高了算法的处理速度。
3、GPU加速技术
3.1、CUDA
为充分利用GPU的计算能力,NVIDIA在2006年推出了CUDA(ComputeUnifiedDevice Architecture,统一计算设备架构)这一编程模型。CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。开发人员现在可以使用C语言来为CUDA架构编写程序。
通过这个技术,用户可利用NVIDIA的GeForce 8以后的GPU和较新的QuadroGPU进行计算。以GeForce 8800 GTX为例,其核心拥有128个内处理器。利用CUDA技术,就可以将那些内处理器串通起来,成为线程处理器去解决数据密集的计算。而各个内处理器能够交换、同步和共享数据。
从CUDA体系结构的组成来说,包含了三个部分:开发库、运行期环境和驱动。
开发库是基于CUDA技术所提供的应用开发库。CUDA的1.1版提供了两个标准的数学运算库:CUFFT (离散快速傅立叶变换)和CUBLAS(离散基本线性计算)的实现。这两个数学运算库所解决的是典型的大规模的并行计算问题,也是在密集数据计算中非常常见的计算类型。开发人员在开发库的基础上可以快速、方便的建立起自己的计算应用。此外,开发人员也可以在CUDA的技术基础上实现出更多的开发库。
运行期环境提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。基于CUDA开发的程序代码在实际执行中分为两种,一种是运行在CPU上的宿主代码(HostCode),一种是运行在GPU上的设备代码(Device Code)。
不同类型的代码由于其运行的物理位置不同,能够访问到的资源不同,因此对应的运行期组件也分为公共组件、宿主组件和设备组件三个部分,基本上囊括了所有在GPGPU开发中所需要的功能和能够使用到的资源接口,开发人员可以通过运行期环境的编程接口实现各种类型的计算。
由于目前存在着多种GPU版本的NVIDIA显卡,不同版本的GPU之间都有不同的差异,因此驱动部分基本上可以理解为是CUDA-enable的GPU的设备抽象层,提供硬件设备的抽象访问接口。CUDA提供运行期环境也是通过这一层来实现各种功能的。由于体系结构中硬件抽象层的存在,CUDA今后也有可能发展成为一个通用的GPU标准接口,兼容不同厂商的GPU产品。
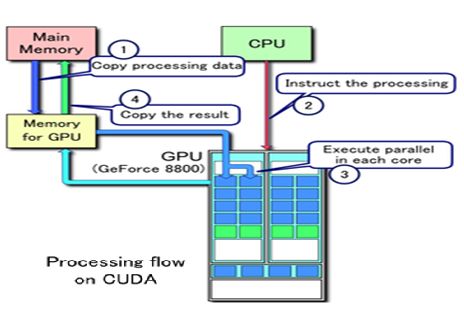
图3-1 CUDA处理流程
对于软件开发者来说,使用Cuda平台调用Cuda的加速库使用的语言包括:C、C++和Fortran。C/C++编程者使用UDAC/C++并用nvcc进行编译。
Nvidia的LLVM库是基于C/C++编译器的。Fortran的开发者能够使用CUDA Fortran,编译使用PGI CUDA Fortran。当然CUDA平台也支持其他的编程接口,包括OpenCL,微软的DirectCompute、OpenGL ComputeShaders和 C++ AMP。第三方的开发者也可以使用Python、Perl、Fortran、Java、Ruby、Lua、Haskell、R、MATLAB、IDL由曼赛马提亚原生支持。
3.2、OpenCL
OpenCL全称Open Computing Language即开放计算语言。OpenCL为异构平台提供了一个编写程序,尤其是并行程序的开放的框架标准。OpenCL所支持的异构平台可由多核CPU、GPU或其他类型的处理器组成。
CUDA只能够在NVIDIA的GPU硬件上运行。但是,OpenCL的目标是面向任何一种并行处理器,OpenCL是第一种真正的开放自由版权编程标准,适用于异构系统上的通用计算。而异构平台可由CPU、GPU、DSP、FPGA或其他类型的处理器搭建。
OpenCL程序同CUDA程序一样,也是分为两部分,一是用于编写内核程序(在OpenCL设备上运行的代码) 的语言,二是定义并控制平台的API。OpenCL提供了基于任务和基于数据两种并行计算机制,它极大地扩展了GPU 的应用范围,使之不再局限于图形领域。
OpenCL由Khronos Group维护。Khronos Group是一个非盈利性技术组织,维护着多个开放的工业标准,例如OpenGL和OpenAL。这两个标准分别用于三维图形和计算机音频方面。OpenCL源程序既可以在多核CPU上也可以在GPU上编译执行,这大大提高了代码的性能和可移植性。OpenCL标准由相应的标准委员会制订,委员会的成员来自业界各个重要厂商。作为用户和程序员期待已久的东西,OpenCL带来两个重要变化:一个跨厂商的非专有软件解决方案;一个跨平台的异构框架以同时发挥系统中所有计算单元的能力。
OpenCL是一个用于异构平台上编程的开放性行业标准。这个平台可以包括 CPU GPU和其他各类计算设备,OpenCL会将各类计算设备组织成一个统一的平台。OpenCL不仅仅是一种编程语言,更是一个完整的并行编程框架,它包括编程语言,API,函数库以及运行时系统来支持软件在整个平台上的开发。
相关下载:
《GPU高性能计算概述》
《GPU深度学习基础介绍》
《OpenACC基本介绍》
《CUDA CC 编程介绍》
《CUDA Fortr基本介绍》
本号资料全部上传至知识星球,加入智能计算芯世界(知识星球)下载全部资料。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号跟踪技术动态,点击“阅读原文”获取更多技术和精彩内容。
