
全新池化方法AdaPool | 让ResNet、DenseNet、ResNeXt等在所有下游任务轻松涨点


池化层是卷积神经网络的基本构建模块,它不仅可以减少网络的计算开销,还可以扩大卷积操作的感受野。池化的目标是产生与下采样效用,同时,在理想情况下,还要具有计算和存储效率。但是同时满足这两个要求是一个挑战。
为此,本文提出了一种自适应指数加权池化方法AdaPool。所提出的方法使用两组池化核的参数化融合,这两组池核分别基于dice-Sørensen系数的指数和指数最大值。
AdaPool的一个关键属性是它的双向性。与普通的池化方法不同,权值可以用于对下采样的激活映射进行上采样。作者将此方法命名为AdaUnPool。
作者还演示了AdaPool如何通过一系列任务改进细节保存,包括图像和视频分类以及目标检测。然后,评估AdaUnPool在图像和视频帧的超分辨率和帧插值任务。为了进行基准测试,作者提出了Inter4K,这是一种新颖的高质量、高帧率视频数据集。
通过实验表明,AdaPool在任务和主干架构之间实现了更好的结果,只引入了少量额外的计算和内存开销。
1简介
池化方法将空间输入采样到更低的分辨率。目标是通过捕捉最重要的信息和保留结构方面,如对比度和纹理,最大限度地减少信息的损失。池化操作在图像和视频处理方法中是必不可少的,包括那些基于卷积神经网络的方法。在cnn中,池化操作有助于减少计算负担,同时增加较深部分卷积的感受野。池化实际上就是所有流行的CNN架构中的一个关键组件,它们具有较低的计算和内存开销。
已经提出的一系列的池化方法,每一种方法都有不同的属性。而大多数网络架构使用最大池化或平均池化,这两种方法都快速且内存高效,但在保留信息方面仍有改进的空间。另一种方法是使用可训练的子网络。这些方法比平均池化或最大池化有一定的改进,但它们通常效率较低,而且一般适用,因为它们的先验参数。

在这项工作中,作者研究如何利用基于指数加权的低计算量方法来解决池化方法的缺点。本文方法引入了加权kernel regions 的方法,通过Dice-Sørensen系数获得基于每个kernel activation 与mean kernel activation之间的相似度指数。然后,如图1所示,作者建议将 AdaPool 作为这两种方法的参数化融合方法。
许多任务,包括实例分割、图像生成和超分辨率等任务需要对输入进行向上采样,而这与池化的目标相反。除了LiftPool 之外,很多池化操作都不能被反转,因为这会导致稀疏的上采样结果出现。常见的上采样方法如插值、转置卷积和反卷积,但是都不是重构高维特征。缺乏包含先验知识是一个阻碍,因为将信息编码到较低的维数时,会丢失较高维数中的局部信息。相反,作者认为包含先验局部知识有利于上采样。基于与AdaPool相同的公式引入了向上采样过程 AdaUnPool。
本文证明了AdaPool在保留描述性激活特性方面的良好效果。因此,这允许使用AdaPool的模型持续改进分类和识别性能。AdaPool保持了较低的计算成本,并提供了一种保留先验信息的方法。作者进一步介绍AdaUnPool并解决超分辨率和插值任务。综上所述,本文做出了以下贡献:
通过逆距离加权(IDW)引入了一种近似的平均池化方法。通过Dice-Sørensen系数(DSC)将基于向量距离的IDW扩展为基于向量相似的IDW,并利用其指数eDSC对核元素进行加权; 提出了 AdaPool,这是一种参数化的可学习融合,融合了最大值和平均值的平滑近似。利用逆公式开发了向上采样过程 AdaUnPool; 在多个基于全局和局部的任务上进行了实验,包括图像和视频分类、目标检测,并通过使用AdaPool替换原来的池化层显示出一致的改进。还展示了AdaUnPool在图像和视频超分辨率和视频帧插值方面的性能提升; 介绍了一个高分辨率和帧速率视频处理数据集Inter4K,用于对帧超分辨率和插值算法进行基准测试。
2相关工作
2.1 Pooling hand-crafted features
降采样在手工编码特征提取中得到了广泛的应用。在Bag-of-Words中,图像被表示为一组局部patch,这些局部patch被合并,然后被编码为向量。基于此方法,空间金字塔匹配(Spatial Pyramid Matching,SPM)的目标是尽可能地保留空间信息。后来的工作扩展了这种方法,线性 SPM 选择空间区域的最大 SIFT 特征。关于特征池化的早期工作大多集中在基于生物皮层信号最大样行为的最大池化。在信息保存方面的最大池化和平均池化研究表明,在低特征激活状态下,最大池化产生的结果更加具有代表性。
2.2 Pooling in CNNs
随着学习特征方法在各种计算机视觉任务中的流行,池化方法也被适应于基于kernel的操作,如早期的CNN模型中,池化主要用于创建具有代表性的特征表示进而减少模型的计算需求,同时支持创建更深层次的架构。
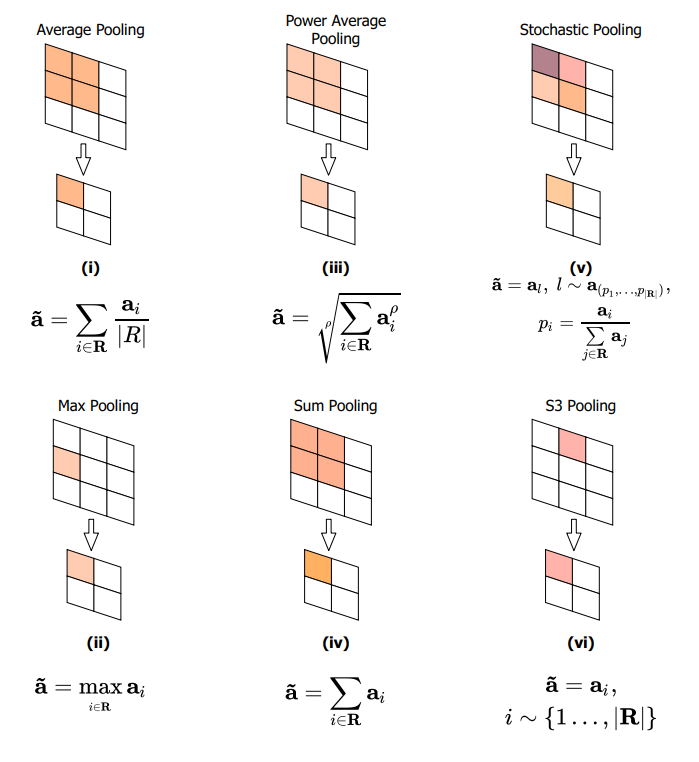
近年来,降采样过程中相关特征的保存发挥着越来越重要的作用。最初的方法包括随机池化,它使用kernel区域内概率加权采样。其他池化方法(如混合池化)基于最大池化和平均池化的组合,要么是概率性的,要么是每个方法的某些部分的组合。Power Average()利用一个学习参数 来确定平均池化和最大池化的相对重要性。当 时对应 sum pooling,而 对应max-pooling。
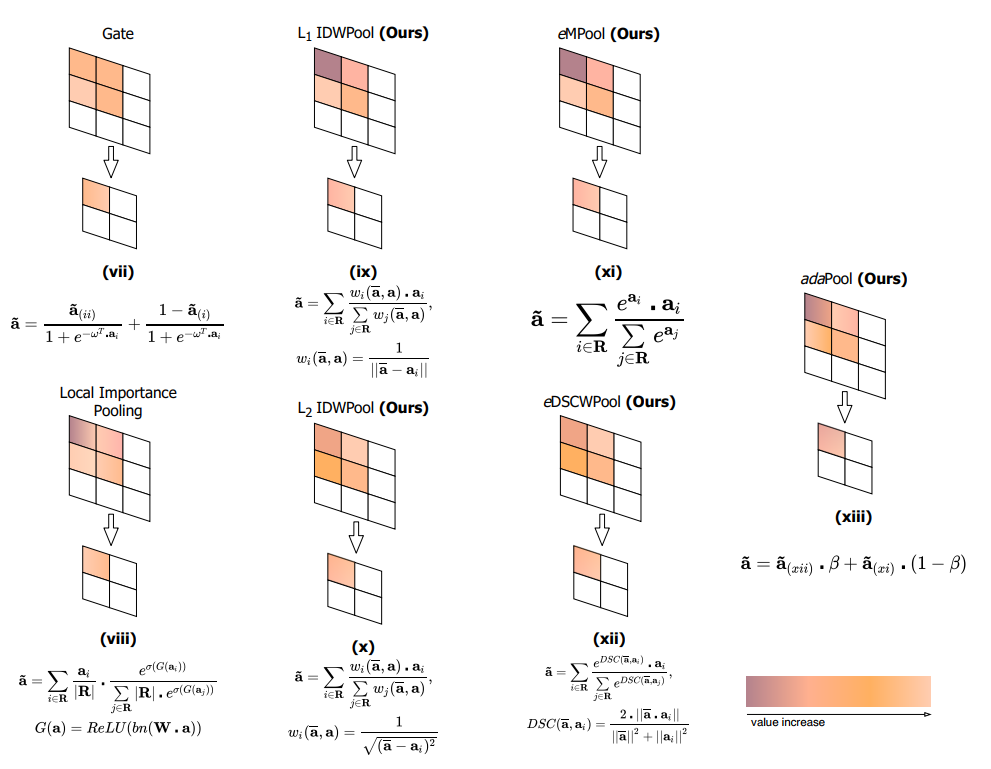
一些方法是基于网格采样的。S3Pool 对原始特性映射网格的行和列使用随机采样来创建下采样。也有一些方法使用可以学习的权重,如 Detail Preserving Pooling (DPP),它使用平均池化,同时用高于平均值的值增强激活。Local Importance Pooling (LIP)利用在子网络注意力机制中学习权重。图2中可以看到不同池化方法执行操作的可视化和数学概述。
前面提到的大多数池化工作不能对向上采样进行倒置。Badrinarayanan等人提出了一种最大池化操作的反转,通过跟踪所选的最大像素的kernel位置,而其他位置则由上采样输出中的零值填充。这将导致使用原始值,但输出本质上是稀疏的。
最近,Zhao和Snoek提出了基于输入的4个可学习 sub-bands 的 LiftPool。产生的输出由发现的 sub-bands 的混合组成。同时还提出了 LiftUpPool 的向上采样反转。这两种方法都基于 sub 网络结构,这也限制了它们作为计算和内存效率高的池化技术的可用性。
前面提到的大多数方法依赖于最大池化和平均池化的组合,或者包含限制低计算和高效下采样的 sub-net。而本文的工作不是结合现有的方法,而是基于一种自适应指数加权方法来提高信息的保留,并更好地保留原始信号的细节。
本文提出的方法AdaPool是受到 的启发。因此,根据它们的相关性对kernel region进行加权,而不受相邻kernel item的影响,这与平均池化和最大池化形成了对比。
AdaPool使用两组池化kernel。第一种方法依赖于 softmax 加权方法来放大更强特征激活值;第二种方法使用单个 kernel item 的通道相似度与它们的平均值来确定它们的相关性。相似性是基于 Dice-Sørensen 系数获得的。最后,两个kernel操作的输出被参数化地融合到单个 volume 中。每个kernel位置的参数都是特定的,也因此本文的方法具有区域适应性。
AdaPool 的一个关键属性是,在反向传播期间为每个kernel item计算梯度,这也提高了网络的连通性。此外,下采样区域不太可能表现出激活的消失趋势,正如Avg pool或sum pool等贡献方法观察到的那样。
在图3中可以看到 AdaPool 如何自适应地捕获细节,其中放大的区域显示了一个签名。AdaPool 改进了字母和数字的清晰度和可识别性。

3本文方法 AdaPool
这里首先介绍在池化方法中共享的操作。在一个大小为C×H×W的激活映射 中定义了局部 kernel 区域 R,其中包含C个通道,高度为H,宽度为W。为了简化表示法,省略通道维数,并假设R是尺寸为k × k的二维空间区域中激活的相对位置指标集合(即激活)。将池化输出表示为 ,对应的梯度表示为 ,其中为R区域内的坐标集。
A. Inverse Distance Weighting pooling
首先引入Inverse Distance Weighting pooling(IDW)池化。IDW 作为一种加权平均方法广泛应用于多变量插值。假设在几何上接近的观察比在几何上更遥远的观察表现出更高的相似度。为了分配一个权重值,IDW 依赖于该区域内测量到的观测距离。图4显示了这个加权过程的可视化表示。
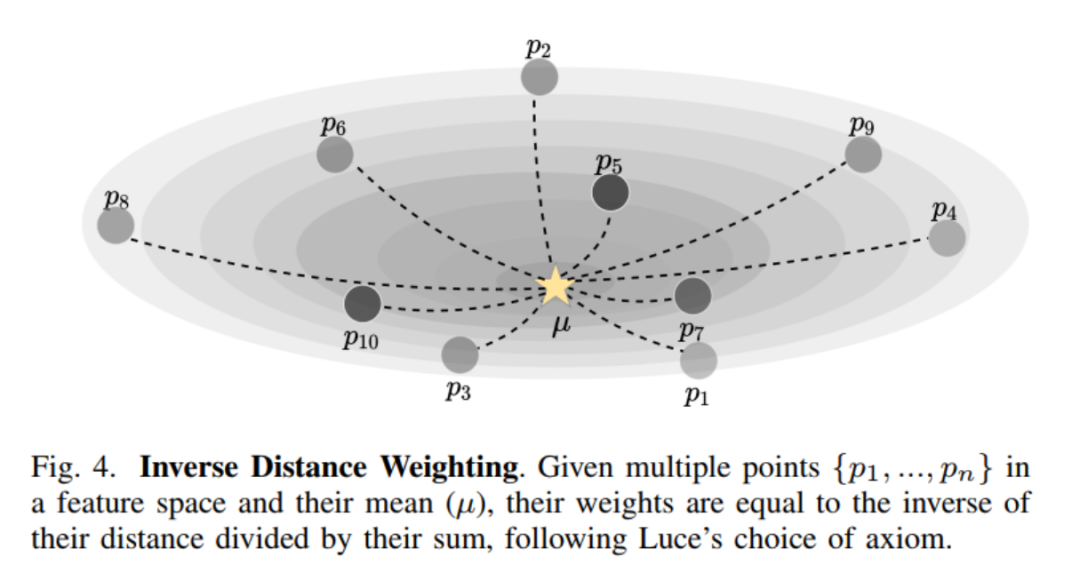
作者认为改进区域平均计算可以限制异常输入值在前向通道和后向通道的梯度计算中对 pooled volumes 的产生的影响。目前池化的平均计算对一个kernel区域内的所有输入向量使用相同的权重。这意味着,就其特征激活而言,所有向量都被认为是同等重要的。其结果是受离群值(离群值在几何上比该区域平均值更远)影响较大的产出区域的组成。为了克服均匀加权区域平均的局限性,作者提出了一种基于IDW的加权方法,并将其称为IDWPool。
作者这里将 IDW 的概念扩展到 kernel 加权,利用每个激活 的相对像素坐标指数 的距离,得到R的平均激活 ,得到的合并区域 公式为:
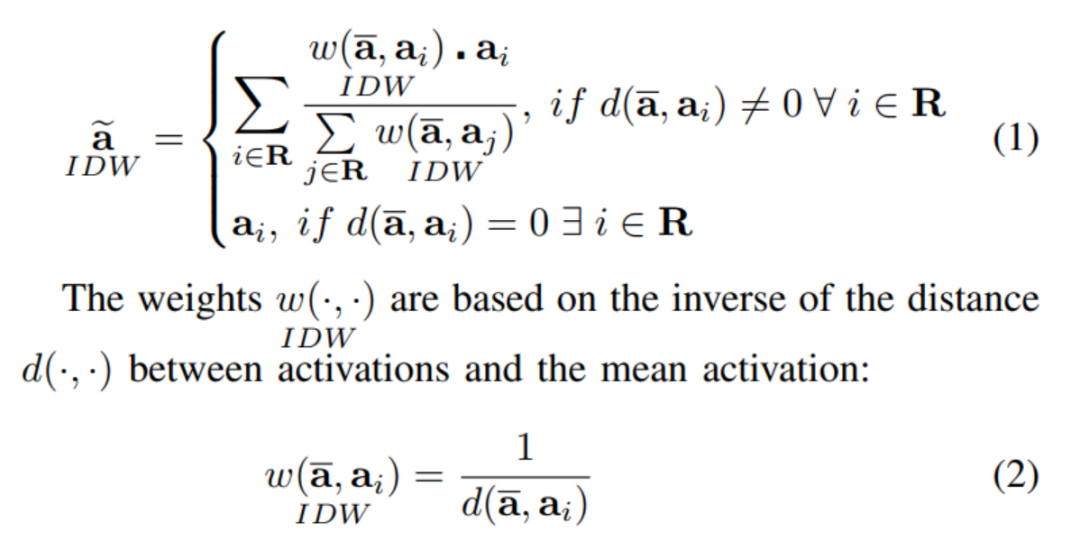
距离函数 可以用任何几何距离方法计算,如下距离形式:

与平均加权相比,IDWPool 生成的归一化结果在几何上更接近均值的特征激活向量具有更高的权重。这也适用于梯度的计算、减少了离群值的影响,为特征激活相关性提供了更好的代表性更新率。在这方面,IDWPool 的工作方式与平均所有激活的常见方法不同,在这种方法中,输出激活没有被规范化。
B. Smooth approximated average pooling
本文以两种方式扩展加权平均的使用。首先,在多维空间中,基于距离的加权平均虽然比统一方法有优势,但它是次优的。特征激活向量与区域内平均值之间的 L1 或 L2 距离是根据每个通道对的平均值、SUM或最大值计算的。结果距离是无界的,因为成对的距离也是无界的。
此外,计算的距离对每通道距离对离群值敏感。这一效果可以通过图5中池化的反向距离加权方法看到。当使用距离方法时,某些通道中的距离可能比其他通道中的距离大得多。这就产生了权值接近于零的问题。

或者,使用相似度度量可以绕过边界问题。但是,特别是对于广泛使用的余弦相似度面临的问题是,即使其中一个向量是无限大的两个向量之间的相似度也可以是1。幸运的是,其他向量点积方法可以解决这个问题,如Dice-Sørensen系数(DSC),通过考虑向量长度,克服了这一限制。
改进一:
作者还考虑了其他基于相似度的方法来寻找两个向量的相关性。除了余弦相似度外,还可以将Kumar和Hassebrook Peak-Correlation Energy (PCE) 应用于 vector volumes (如表II所示)。图5展示了不同相似度方法在池化质量上的差异。考虑到前面提到的余弦相似度的不足,作者在 PCE 上使用 DSC 主要是由于 PCE 的非单调性质和值分布。

改进二:
第二个扩展是使用激活向量和平均激活量之间相似度的指数(e)。对于式1的IDW方法,零值距离的权重为零。这导致池化方法在反向传播期间不可微分,因为不是每个位置的所有梯度都将被计算。这也增加了当权重接近于零时出现消失梯度问题的可能性。通过算术下溢,它们的梯度可以变为零。在引入相似系数指数的基础上将式1重新表述为:
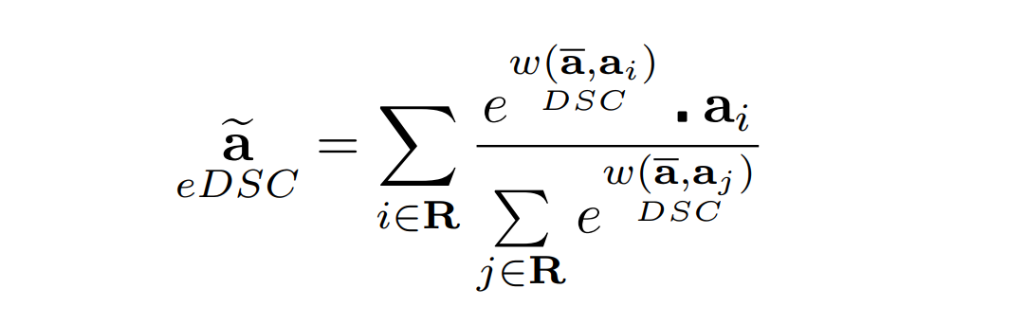
下采样的关键目标之一是在保持信息特征的同时降低输入的空间分辨率。
创建不能完全捕获结构和特性外观的下采样可能会对性能产生负面影响。图3中可以看到这种丢失的详细示例。平均池化将统一地产生一个减少的激活。IDWpool可以通过权重值提高激活保持。但权值是无界的,可能导致渐变消失。相反,使用 Dice-Sørensen 系数(eDSCWPool)的指数提供了一种非零权重值的平衡方法,同时保持IDW的有益属性。
C. Smooth approximated maximum pooling
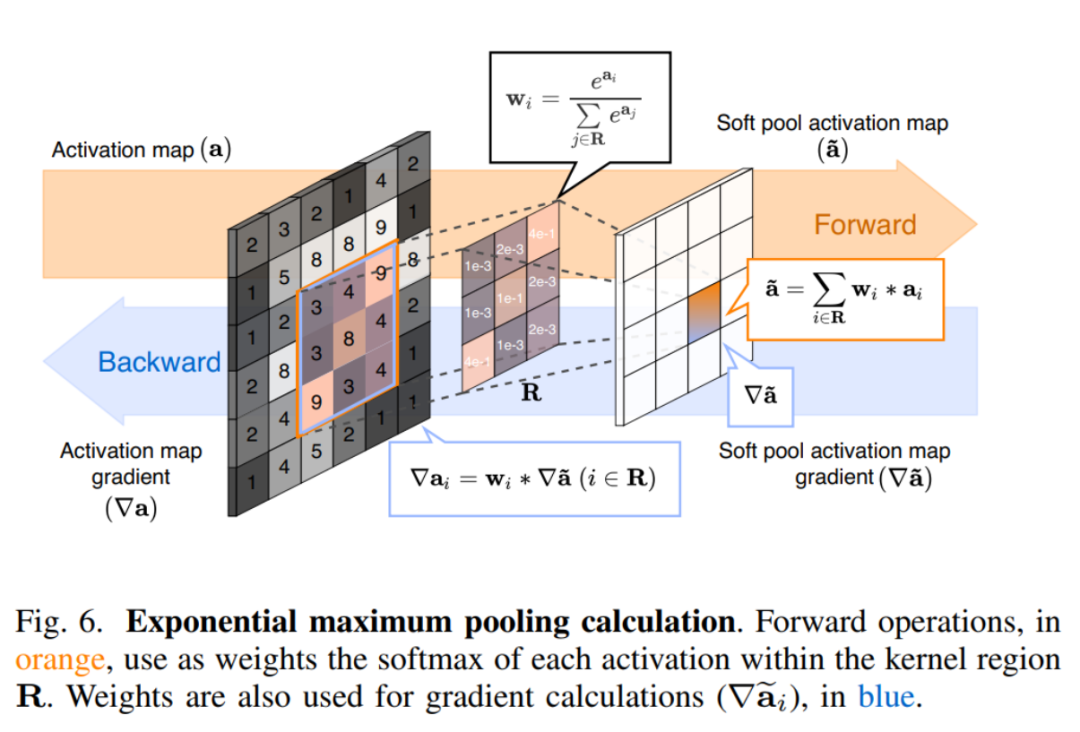
类似于创建一种在kernel区域内发现平滑近似平均值的方法,作者还讨论了基于平滑近似最大值的下采样公式,该公式最近被引入到了SoftPool之中。为了清晰,并且符合所使用的术语,将SoftPool称为指数最大值(eM)。
使用指数最大值背后的动机受到下采样手工编码特征的皮层神经模拟的影响。这种方法是以自然指数为基础的(e),以确保更大的激活将对最终产出产生更大的影响。该操作是可微的,类似于指数平均值,在反向传播过程中,kernel区域激活分配了相应比例的梯度。
指数最大池(eMPool)中的权值被用作基于相应激活值的非线性转换。高信息量的激活将比低信息量的更占主导地位。由于大多数池操作都是在高维特征空间上执行的,因此突出显示效果更佳的激活要比选择最大激活更为平衡。在后一种情况下,丢弃大部分激活会带来丢失重要信息的风险。
eMPool的输出是通过对kernel区域R内所有加权激活的总和产生的:
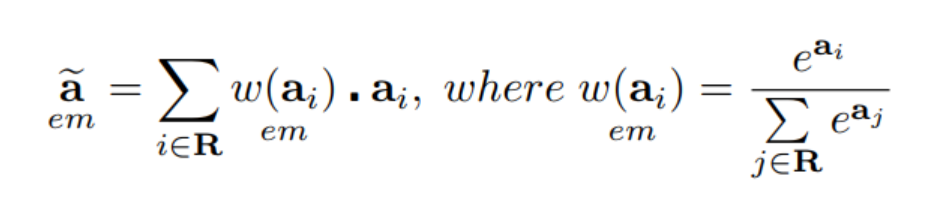
与其他基于最大值的池化方法相比,激活区域softmax产生标准化结果,类似于eDSCWPool。但与平滑的指数平均值不同,归一化结果基于一个概率分布,该概率分布与kernel区域内每个激活相对于相邻激活的值成比例。完整的信息向前和向后传递的可视化如下图所示。
D. AdaPool: Adaptive exponential pooling
最后,提出了两种基于平滑近似的池化方法的自适应组合。基于它们的属性eMPool或eDSCWPool都演示了在有效保存特性细节方面的改进。
从图3中可以看出,这两种方法中没有一种通常优于另一种。基于这一观察结果,并使用可训练参数 来创建平滑近似平均值和平滑近似最大值的组合 volume 。在这里, 是用来学习的比例,将使用从每两种方法。引入 作为网络训练过程的一部分,具有创建一个综合池化策略的优势,该策略依赖于eMPool和eDSCWPool属性的结合。
将该方法定义为下采样平滑逼近平均值()和平滑逼近最大值()的加权组合:
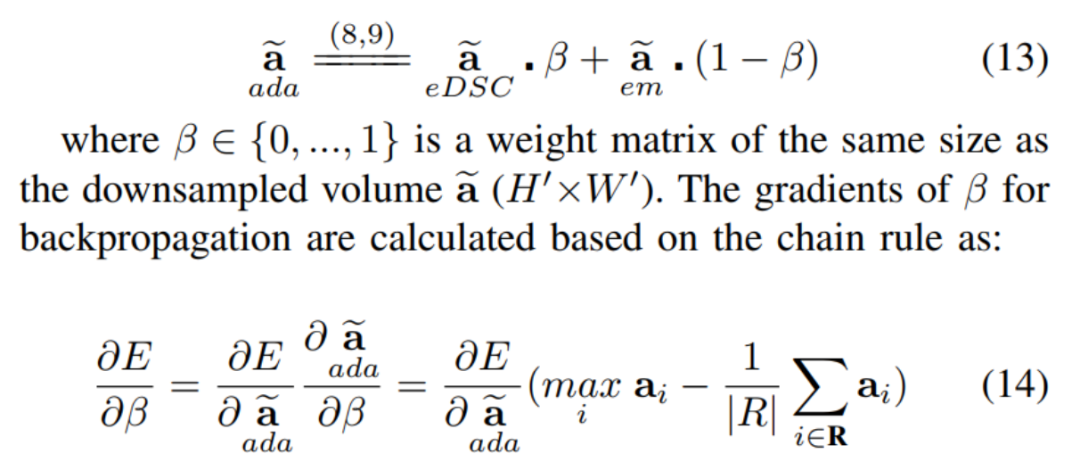
class CUDA_ADAPOOL2d(Function):
@staticmethod
@torch.cuda.amp.custom_fwd(cast_inputs=torch.float32)
def forward(ctx, input, beta, kernel=2, stride=None, return_mask=False):
assert input.dtype==beta.dtype, '`input` and `beta` are not of the same dtype.'
beta = torch.clamp(beta , 0., 1.)
no_batch = False
if len(input.size()) == 3:
no_batch = True
input.unsqueeze_(0)
B, C, H, W = input.shape
kernel = _pair(kernel)
if stride is None:
stride = kernel
else:
stride = _pair(stride)
oH = (H - kernel[0]) // stride[0] + 1
oW = (W - kernel[1]) // stride[1] + 1
output = input.new_zeros((B, C, oH, oW))
if return_mask:
mask = input.new_zeros((B, H, W))
else:
mask = input.new_zeros((1))
adapool_cuda.forward_2d(input.contiguous(), beta, kernel, stride, output, return_mask, mask)
ctx.save_for_backward(input, beta)
ctx.kernel = kernel
ctx.stride = stride
if return_mask:
mask_ = mask.detach().clone()
mask_.requires_grad = False
CUDA_ADAPOOL2d.mask = mask_
output = torch.nan_to_num(output)
if no_batch:
return output.squeeze_(0)
return output
@staticmethod
@torch.cuda.amp.custom_bwd
def backward(ctx, grad_output):
grad_input = torch.zeros_like(ctx.saved_tensors[0])
grad_beta = torch.zeros_like(ctx.saved_tensors[1])
saved = [grad_output] + list(ctx.saved_tensors) + [ctx.kernel, ctx.stride, grad_input, grad_beta]
adapool_cuda.backward_2d(*saved)
return torch.nan_to_num(saved[-2]), torch.nan_to_num(saved[-1]), None, None, None
def adapool2d(x, beta=None, kernel_size=2, stride=None, return_mask=False, native=False):
if stride is None:
stride = kernel_size
kernel_size = _pair(kernel_size)
stride = _pair(stride)
assert beta is not None, 'Function called with `None`/undefined `beta` parameter.'
shape = [(x.shape[-2] - kernel_size[-2]) // stride[-2] + 1 ,
(x.shape[-1] - kernel_size[-1]) // stride[-1] + 1]
beta_shape = list(beta.shape)
shape_d = [s*kernel_size[i] for i,s in enumerate(shape)]
assert shape == beta_shape or beta_shape==[1,1], 'Required `beta` shape {0} does not match given shape {1}'.format(shape, beta_shape)
assert x.is_cuda, 'Only CUDA implementation supported!'
if not native:
x = beta*CUDA_ADAPOOL2d_EDSCW.apply(x, kernel_size, stride, return_mask) + (1.-beta)*CUDA_ADAPOOL2d_EM.apply(x, kernel_size, stride, return_mask)
else:
x = CUDA_ADAPOOL2d.apply(x, beta, kernel_size, stride, return_mask)
# Replace `NaN's
if not return_mask:
return torch.nan_to_num(x)
else:
if not native:
return torch.nan_to_num(x), (CUDA_ADAPOOL2d_EDSCW.mask,CUDA_ADAPOOL2d_EM.mask,beta)
else:
return torch.nan_to_num(x), CUDA_ADAPOOL2d.mask
class AdaPool2d(torch.nn.Module):
def __init__(self, kernel_size=2, beta=None, stride=None,
beta_trainable=True,return_mask=False, device=None,
dtype=None, native=False):
factory_kwargs = {'device': device, 'dtype': dtype}
super(AdaPool2d, self).__init__()
if stride is None:
stride = kernel_size
self.kernel_size = _pair(kernel_size)
self.stride = _pair(stride)
assert isinstance(native, bool), 'Argument `native` should be boolean'
self.native = native
assert isinstance(beta, tuple) or torch.is_tensor(beta), 'Agument `beta` can only be initialized with Tuple or Tensor type objects and should correspond to size (oH, oW)'
if isinstance(beta, tuple):
beta = torch.randn(beta, **factory_kwargs)
else:
beta = beta.to(**factory_kwargs)
beta = torch.clamp(beta, 0., 1.)
self.return_mask = return_mask
if beta_trainable:
self.register_parameter(name='beta', param=torch.nn.Parameter(beta))
else:
self.register_buffer(name='beta', param=torch.nn.Parameter(beta))
def forward(self, x):
self.beta.data.clamp(0., 1.)
return adapool2d(x, beta=self.beta, kernel_size=self.kernel_size, stride=self.stride, return_mask=self.return_mask, native=self.native)
E. Upsampling using adaUnPool
在池化过程中,kernel 区域中的信息被压缩为一个输出。大多数子采样方法不建立从子采样到原始输入的映射。大多数任务都不需要这个链接,但其他任务,如语义分割,超分辨率或帧插值都受益于它。由于AdaPool是可微的,并且使用一个最小的权重值分配,发现的权重可以作为上行采样时的先验知识。将给定AdaPool权重的上采样操作称为AdaUnPool。
在 pooled volume ()的情况下,使用平滑的近似最大值()和平滑近似平均权值( )具有学习值。第个kernel区域()的最终 unpooled 输出()计算如下:
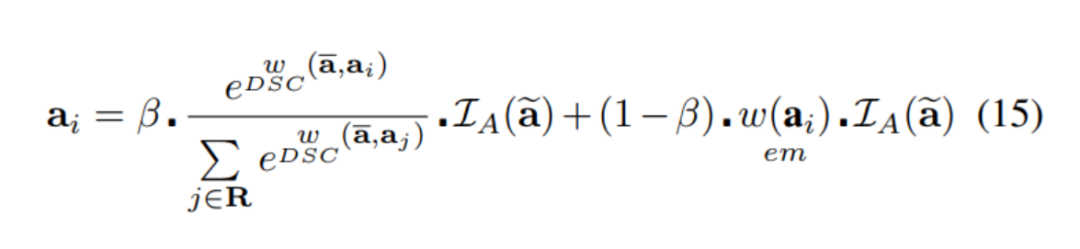
其中,通过分配 pooled volume 进行插值()在kernel区域内每个位置I处的初始kernel区域。方法是用来放大 volume 。然后用相应的平滑近似平均 Mask 或最大 Mask 来确定 volume 。
def adaunpool(x, mask=None, interpolate=True):
assert mask is not None, 'Function called with `None`/undefined `mask` parameter.'
if interpolate:
if isinstance(mask, tuple):
mask_edscw = torch.clamp(mask[0], 0., 1.)
mask_em = torch.clamp(mask[1], 0., 1.)
x1 = F.interpolate(x*mask[2], size=mask[0].shape[1:], mode='area').transpose(0,1)
x2 = F.interpolate(x*(1.-mask[2]), size=mask[1].shape[1:], mode='area').transpose(0,1)
return (x1*mask_edscw.unsqueeze(0) + x2*mask_em.unsqueeze(0)).transpose(0,1)
else:
mask = torch.clamp(mask, 0., 1.)
x = F.interpolate(x, size=mask.shape[1:], mode='area').transpose(0,1)
return (x*mask.unsqueeze(0) + x*(1.- mask.unsqueeze(0))).transpose(0,1)
else:
if isinstance(mask, tuple):
mask_edscw = torch.clamp(mask[0], 0., 1.)
mask_em = torch.clamp(mask[1], 0., 1.)
return (x.transpose(0,1)*mask_edscw.unsqueeze(0) + x.transpose(0,1)*mask_em.unsqueeze(0)).transpose(0,1)
else:
mask = torch.clamp(mask, 0., 1.)
return (x.transpose(0,1)*mask.unsqueeze(0) + x.transpose(0,1)*(1.- mask.unsqueeze(0))).transpose(0,1)
class AdaUnpool2d(torch.nn.Module):
def __init__(self, mask=None):
super(AdaUnpool2d, self).__init__()
if stride is None:
stride = kernel_size
assert mask != None, '`mask` cannot be `None`!'
self.mask = mask
def forward(self, x):
return adaunpool(x, mask=self.mask)
4实验
分类
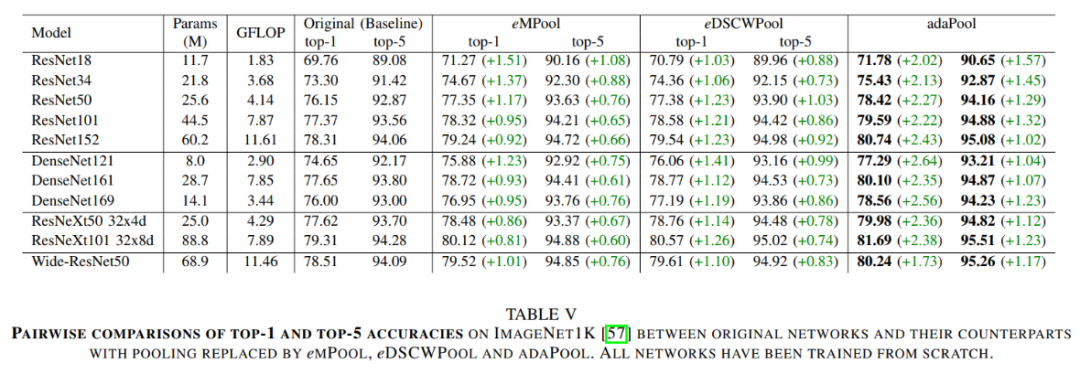
从上表可以看出,使用AdaPool后,在ImageNet数据集上,无论是ResNet、DenseNet还是ResNeXt都有不同程度的性能提升(+2.x%),可见AdaPool方法的有效性。
目标检测
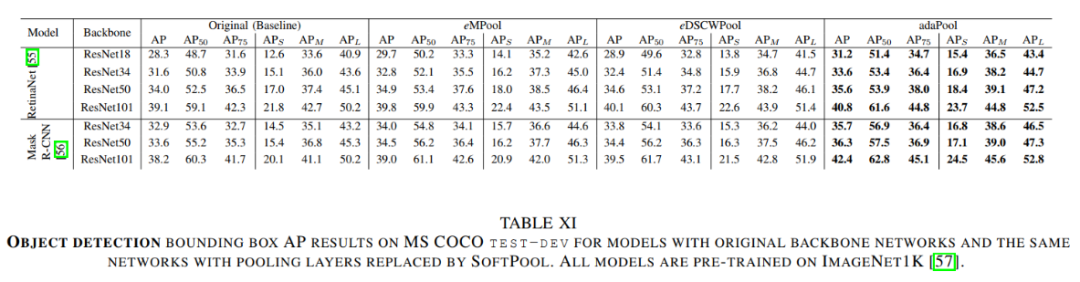
从上表可以看出,使用AdaPool后,在COCO数据集上,无论是基于ResNet的目标检测还是实例分割都有不同程度的性能提升(+2.x% AP),可见AdaPool方法的有效性。
5参考
[1]. AdaPool: Exponential Adaptive Pooling for Information-Retaining Downsampling.
6推荐阅读

NWD-Based Model | 小目标检测新范式,抛弃IoU-Based暴力涨点(登顶SOTA)

SMU激活函数 | 超越ReLU、GELU、Leaky ReLU让ShuffleNetv2提升6.22%

迟到的 HRViT | Facebook提出多尺度高分辨率ViT,这才是原汁原味的HRNet思想
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
