
【NLP】如何提升BERT在下游任务中的性能
作者 | 许明
整理 | NewBeeNLP公众号
随着Transformer 在NLP中的表现,Bert已经成为主流模型,然而大家在下游任务中使用时,是不是也会发现模型的性能时好时坏,甚至相同参数切换一下随机种子结果都不一样,又或者自己不管如何调,模型总达不到想象中的那么好,那如何才能让Bert在下游任务中表现更好更稳呢?本文以文本分类为例,介绍几种能帮你提高下游任务性能的方法。
Further Pre-training
最稳定也是最常用的提升下游任务性能的手段就是继续进行预训练了。继续预训练目前有以下几种模式。
二阶段
首先回顾一下,Bert 是如何使用的呢?
我们假设通用泛化语料为 ,下游任务相关的数据为 , Bert 即在通用语料 上训练一个通用的Language Model, 然后利用这个模型学到的通用知识来做下游任务,也就是在下游任务上做fine-tune,这就是二阶段模式。
大多数情况下我们也都是这么使用的:下载一个预训练模型,然后在自己的数据上直接fine-tune。
三阶段
在论文Universal Language Model Fine-tuning for Text Classification[1]中,作者提出了一个通用的范式ULMFiT:
在大量的通用语料上训练一个LM(Pretrain); 在任务相关的小数据上继续训练LM(Domain transfer); 在任务相关的小数据上做具体任务(Fine-tune)。
那我们在使用Bert 时能不能也按这种范式,进行三阶段的fine-tune 从而提高性能呢?答案是:能!
比如邱锡鹏老师的论文How to Fine-Tune BERT for Text Classification?[2]和Don't Stop Pretraining: Adapt Language Models to Domains and Tasks[3]中就验证了,在任务数据 继续进行pretraining 任务,可以提高模型的性能。
那如果我们除了任务数据没有别的数据时,怎么办呢?简单,任务数据肯定是相同领域的,此时直接将任务数据看作相同领域数据即可。所以,在进行下游任务之前,不妨先在任务数据上继续进行pre-training 任务继续训练LM ,之后再此基础上进行fine-tune。
四阶段
我们在实际工作上,任务相关的label data 较难获得,而unlabeled data 却非常多,那如何合理利用这部分数据,是不是也能提高模型在下游的性能呢?答案是:也能!
在大量通用语料上训练一个LM(Pretrain); 在相同领域 上继续训练LM(Domain transfer); 在任务相关的小数据上继续训练LM(Task transfer); 在任务相关数据上做具体任务(Fine-tune)。
而且上述两篇论文中也给出了结论:先Domain transfer 再进行Task transfer 最后Fine-tune 性能是最好的。
如何further pre-training
how to mask
首先,在further pre-training时,我们应该如何进行mask 呢?不同的mask 方案是不是能起到更好的效果呢?
在Roberta 中提出,动态mask 方案比固定mask 方案效果更好。此外,在做Task transfer 时,由于数据通常较小,固定的mask 方案通常也容易过拟合,所以further pre-training 时,动态随机mask 方案通常比固定mask 效果更好。
而ERNIE 和 SpanBert 中都给出了结论,更有针对性的mask 方案可以提升下游任务的性能,那future pre-training 时是否有什么方案能更有针对性的mask 呢?
刘知远老师的论文Train No Evil: Selective Masking for Task-Guided Pre-Training[4]就提出了一种更有针对性的mask 方案Selective Mask,进行further pre-training 方案,该方案的整体思路是:
在 上训练一个下游任务模型 ; 利用 判断token 是否是下游任务中的重要token,具体计算公式为:, 其中 为完整句子(序列), 为一个初始化为空的buffer,每次将句子中的token 往buffer中添加,如果加入的token 对当前任务的表现与完整句子在当前任务的表现差距小于阈值,则认为该token 为重要token,并从buffer 中剔除; 利用上一步中得到的token label,训练一个二分类模型 ,来判断句子中的token 是否为重要token; 利用 ,在domain 数据上进行预测,根据预测结果进行mask ; 进行Domain transfer pre-training; 在下游任务进行Fine-tuning。
上述方案验证了更有针对性的mask 重要的token,下游任务中能得到不错的提升。综合下来,Selective Mask > Dynamic Mask > Static Mask
虽然selective mask 有提升,但是论文给出的思路太过繁琐了,本质上是判断token 在下游任务上的影响,所以这里给出一个笔者自己脑洞的一个方案:「通过 在unlabeled 的Domain data 上直接预测,然后通过不同token 下结果的熵的波动来确定token 对下游任务的影响」。这个方案我没有做过实验,有兴趣的可以试试。
when to stop
在further pretraining 时,该何时停止呢?是否训练的越久下游任务就提升的越多呢?答案是否定的。在进行Task transfer 时,应该训练多少步,论文How to Fine-Tune BERT for Text Classification?[5]进行了实验,最后得出的结论是100k步左右,下游任务上提升是最高的,这也与我自己的实验基本吻合,训练过多就会过拟合,导致下游任务上提升小甚至降低。
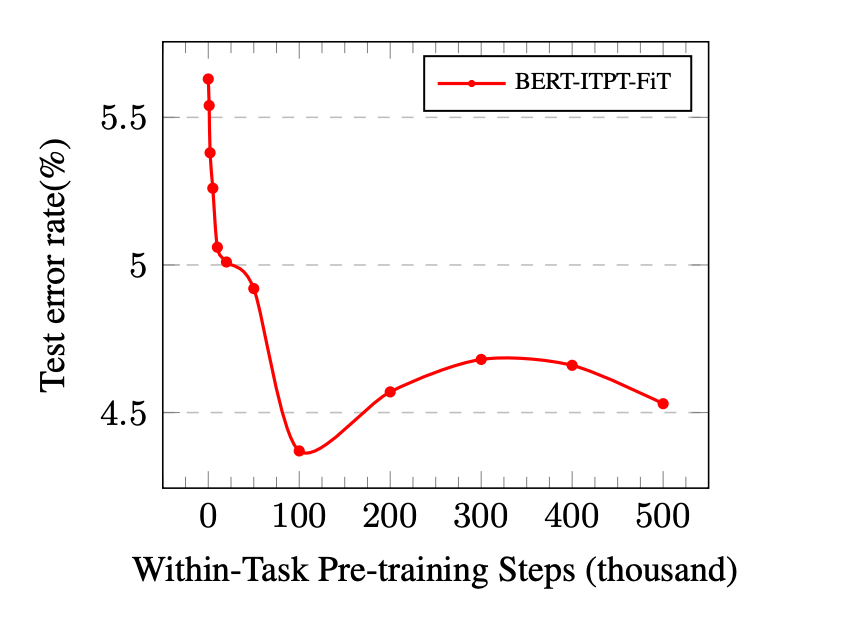
此外,由于下游任务数据量的不同,进行多少步结果是最优的也许需要实验测试。这里给出一个更快捷稳妥的方案:借鉴PET本质上也是在训练MLM 任务,我们可以先利用利用PET做fine-tuning,然后将最优模型作为预训练后的模型来进行分类任务fine-tuning,这种方案我实验后的结论是与直接进行Task transfer性能提升上相差不大。不了解PET的可以查看我之前博文PET-文本分类的又一种妙解[6].
how to fine-tuning
不同的fine-tuning 方法也是影响下游任务性能的关键因素。
optimizer
关于优化方案上,Bert 的论文中建议使用与bert 预训练时一致的方案进行fine-tuning,即使用weighted decay修正后的Adam,并使用warmup策略 搭配线性衰减的学习率。不熟悉的同学可以查看我之前的博文optimizer of bert[7]
learning rate
不合适的learning rate可能会导致灾难性遗忘,通常learning rate 在 之间,更大的learning rate可能就会发生灾难性遗忘,不利于优化。
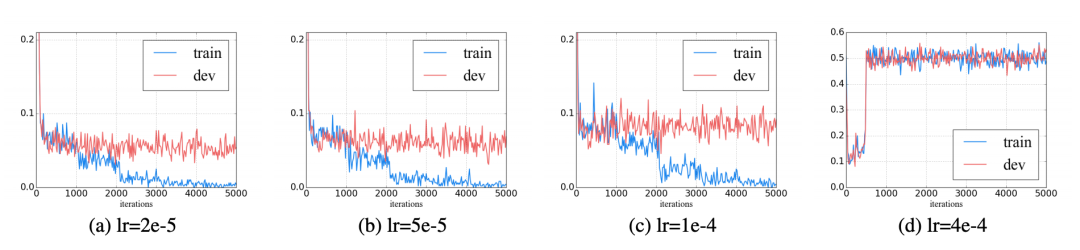
此外,对transformer 逐层降低学习率也能降低发生灾难性遗忘的同时提升一些性能。
multi-task
Bert在预训练时,使用了两个task:NSP 和 MLM,那在下游任务中,增加一个辅助的任务是否能带来提升呢?答案是否定的。如我之前尝试过在分类任务的同时,增加一个相似性任务:让样本与label desc的得分高于样本与其他样本的得分,但是最终性能并没有得到提升。具体的实验过程请看博文模型增强之从label下手[8]。
此外,论文How to Fine-Tune BERT for Text Classification?[9]也任务multi-task不能带来下游任务的提升。
which layer
Bert的结构上是一个12层的transformer,在做文本分类时,通常我们是直接使用最后一层的[CLS]来做fine-tuning,这样是最优的吗?有没有更好的方案?
论文How to Fine-Tune BERT for Text Classification?[10]中针对这个问题也做了实验,对比了不同的layer不同的抽取策略,最终结论是所有层拼接效果最好,但是与直接使用最后一层差距不大。
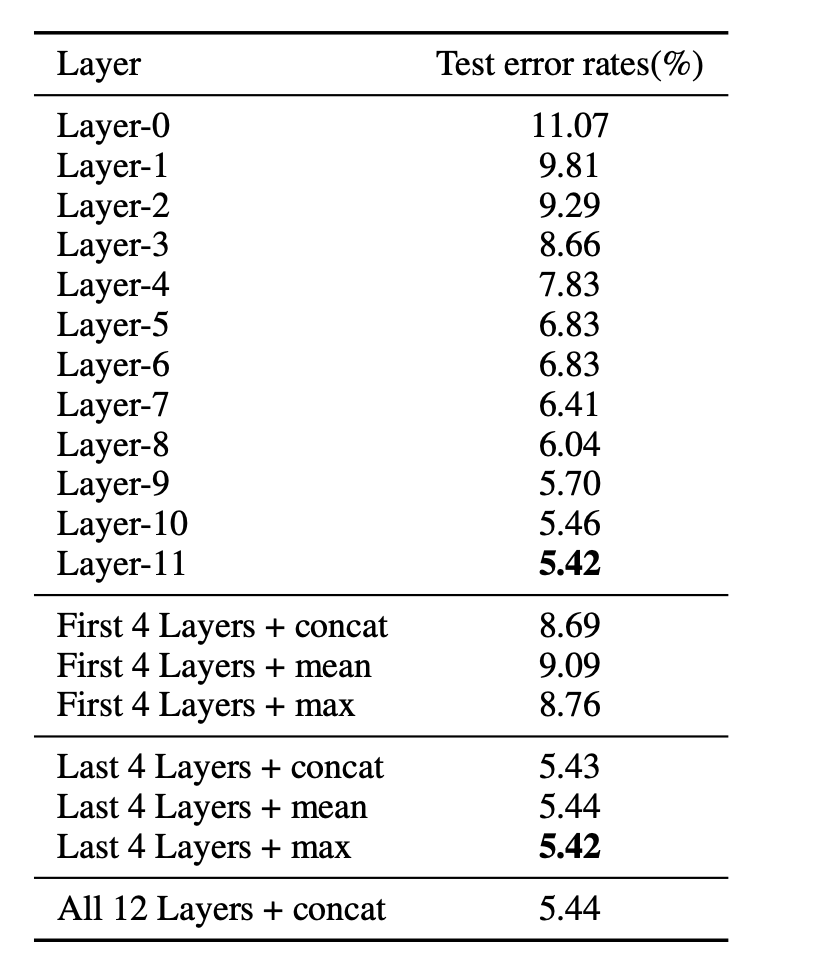
而论文Hate Speech Detection and Racial Bias Mitigation in Social Media based on BERT model[11]中,作者通过组合多种粒度的语义信息,即将12层的[CLS]拼接后,送人CNN,在Hate Speech Detection 中能带来8个点的提升!cnn.png)
所以在fine-tuning时,也可以想一想到底是哪种粒度的语义信息对任务更重要。
Self-Knowledge Distillation
self-knowledge distillation(自蒸馏)也是一种常用的提升下游任务的手段。做法是先在Task data上fine-tuning 一个模型,然后通过模型得到Task data 的soft labels,然后使用soft labels 代替hard label 进行fine-tuning。更多细节可以查看之前的博文Knowledge Distillation之知识迁移[12]
知识注入
通过注入外部知识到bert中也能提升Bert的性能,常用的方式主要有两种:
在bert embedding 层注入:通过将外部Embedding 与Bert token-embedding 拼接(相加)进行融合,然后进行transformer一起作用下游; 在transformer的最后一层,拼接外部embedding,然后一起作用下游。
如Enriching BERT with Knowledge Graph Embeddings for Document Classification[13]中,通过在
transformer的最后一层中拼接其他信息,提高模型的性能。

数据增强
NLP中数据增强主要有两种方式:一种是保持语义的数据增强,一种是可能破坏语义的局部扰动增强。
保持语义通常采用回译法,局部扰动的通常使用EDA,更多细节可以查看之前博文NLP中的数据增强[14]
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定要备注信息才能通过)
本文参考资料
Universal Language Model Fine-tuning for Text Classification: http://arxiv.org/abs/1801.06146
[2]How to Fine-Tune BERT for Text Classification?: http://arxiv.org/abs/1905.05583
[3]Don't Stop Pretraining: Adapt Language Models to Domains and Tasks: https://arxiv.org/abs/2004.10964
[4]Train No Evil: Selective Masking for Task-Guided Pre-Training: http://arxiv.org/abs/2004.09733
[5]How to Fine-Tune BERT for Text Classification?: http://arxiv.org/abs/1905.05583
[6]PET-文本分类的又一种妙解: https://xv44586.github.io/2020/10/25/pet/
[7]optimizer of bert: https://xv44586.github.io/2020/08/01/optimizer-in-bert/
[8]模型增强之从label下手: https://xv44586.github.io/2020/09/13/classification-label-augment/
[9]How to Fine-Tune BERT for Text Classification?: http://arxiv.org/abs/1905.05583
[10]How to Fine-Tune BERT for Text Classification?: http://arxiv.org/abs/1905.05583
[11]Hate Speech Detection and Racial Bias Mitigation in Social Media based on BERT model: http://arxiv.org/abs/2008.06460
[12]Knowledge Distillation之知识迁移: https://xv44586.github.io/2020/08/31/bert-01/
[13]Enriching BERT with Knowledge Graph Embeddings for Document Classification: http://arxiv.org/abs/1909.08402
[14]NLP中的数据增强: https://xv44586.github.io/2020/11/10/eda/
- END -
往期精彩回顾
本站qq群851320808,加入微信群请扫码: