
轻松学Pytorch – 全局池化层详解
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

大家好,这是轻松学Pytorch系列的第九篇分享,本篇你将学会什么是全局池化,全局池化的几种典型方式与pytorch相关函数调用。
卷积神经网络可以解决回归跟分类问题,但是常见的卷积神经网络到最后都要通过全连接层实现分类,这个其实会导致很多时候神经元数目跟计算量在全连接层暴增,特别对一些回归要求比较高的网络往往会带来一些后遗症。所以陆陆续续有人提出了不同全连接层解决方案,最常见的两个就是把最后卷积层flatten改为全局最大/均值池化,对比一下这两种方式,图示如下:
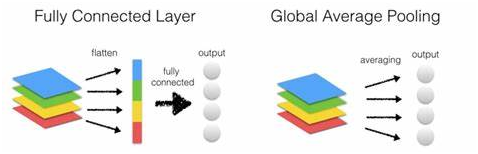
可以看到全局池化会根据需要产生神经元,神经元个数可控,可调。而flatten方式就是一个硬链接,无法在flatten的时候调整链接数目。全局均值池化输出最常见的做法是把每个通道feature map输出一个神经元(均值结果输出),图示如下:
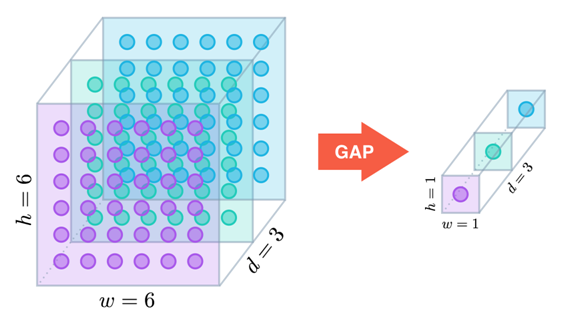
全局最大池化图示如下,它是取每个feature map的最大值:
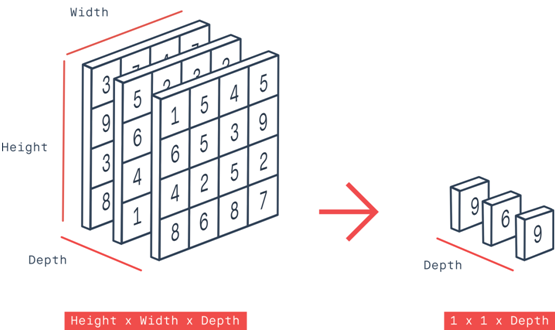
全局均值池化跟全局最大池化的输入一般为NxCxHxW,输出为NxCx1x1但是实际上有时候我们还会有另外一个需求,就是全局深度池化,它的输出是Nx1xHxW。这个方式的池化通常会先把数据转换为NxH*WxC的方式,然后使用一维度最大/均值池化在C上完成,最后在转换为Nx1xHxW即可。了解常见几种全局池化方式之后,下面就来一起看看Pytorch中支持的相关函数。
Pytorch函数支持全局最大池化与均值池化,相关函数分别为:
全局最大池化
torch.nn.AdaptiveMaxPool2d(output_size, return_indices=False)全局均值池化
torch.nn.AdaptiveAvgPool2d(output_size)其中output_size表示输出HxW正常设为HxW=1x1=(1, 1)。代码演示如下:
# 全局均值池化avg_pooling = torch.nn.AdaptiveAvgPool2d((1,1))B, C, H, W = input.size()output = avg_pooling(input).view(B, -1)print("全局均值池化:", output.size())print(output, "\n")# 全局最大池化avg_pooling = torch.nn.AdaptiveMaxPool2d((1, 1))B, C, H, W = input.size()output = avg_pooling(input).view(B, -1)print("全局最大池化:", output.size())print(output, "\n")
输入为NxCxHxW=1x8x4x4输出结果如下:

但是pytorch中没有全局深度池化函数支持,这个是我在写一个程序时候才发现,后来经过一番折腾,在别人代码的基础上我改写了一个符合我要求的全局深度池化函数。经过测试工作良好。演示如下:
class DeepWise_Pool(torch.nn.MaxPool1d):def __init__(self, channels, isize):super(DeepWise_Pool, self).__init__(channels)self.kernel_size = channelsself.stride = isizedef forward(self, input):n, c, w, h = input.size()input = input.view(n,c,w*h).permute(0,2,1)pooled = torch.nn.functional.max_pool1d(input, self.kernel_size, self.stride,self.padding, self.dilation, self.ceil_mode,self.return_indices)_, _, c = pooled.size()pooled = pooled.permute(0,2,1)return pooled.view(n,c,w,h).view(w, h)input = torch.randn(1, 8, 4, 4)print("input data:/n", input)print("input data:", input.size())B, C, W, H = input.size()dw_max_pool = DeepWise_Pool(C, W*H)output = dw_max_pool(input)print("全局深度池化:", output.view(-1, 16).size())print(output, "\n")
针对输入为NxCxHxW=1x8x4x4深度最大池化运行结果如下:

关于使用GAP或者全局池化的好处,卷积神经网络在图像分类中,把卷积层作为特征提取,全链接层+softmax作为归回分类,这样方式会导致在全连接层输入神经元太多容易导致过拟合,所以Hinton等人提出了Dropout概念,提高网络泛化能力防止了过拟合发生。但是GAP是另外方式避免全连接层的处理,直接通过全局池化+softmax进行分类,它的优点是更加符合卷积层最后的处理,另外一个优点是GAP不会产生额外的参数,相比全连接层的处理方式,降低整个计算量,此外全局池化还部分保留来输入图像的空间结构信息,所以全局池化在有些时候会是一个特别有用的选择。更多请读该论文:
https://arxiv.org/pdf/1312.4400.pdf好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~