
Involution再思考:三大任务涨点明显
【GiantPandaCV导语】在被Transformer结构刷榜之前,CNN一直都是CV任务的标配。卷积有两个基本性质,分别是空间不变性 (spatial-agnostic)和通道特异性 (channel-specific)。空间不变性使得卷积能够在所有位置共享参数,并充分利用视觉特征的“平移等变性”。通道特异性使得卷积能够充分建模通道之间的关系,提高模型的学习能力。
但是任何事物其实都是有两面性的,这两个性质在具有优点的同时,也同样存在缺点(缺点会在Motivation中进行具体分析)。因此,作者脑洞打开,将卷积的性质进行了反转,提出了一个新的算子——Involution,这个算子具有空间特异性和通道不变性。最终,基于Involution结构,作者提出了实例化网络结构RedNet,并在分类、检测、分割任务上提点明显。
这篇工作其实是作者在rethink卷积的性质之后提出的一个新的结构,虽然相比于最近几篇ViT的文章,这篇文章在性能上显得有些无力。但是相比于ResNet结构,这篇文章无论是在参数量,还是计算量、性能上都有非常大的优越性。
另外,这篇文章其实是加强了空间上的建模,减弱了通道上建模关系。个人感觉视觉特征上的通道信息还是比较有用的,而相比之下,文本的通道信息作用就没有那么大,而文本上的空间关系是更加有用的。所以,个人觉得,按照这个思路,Involution在NLP 领域说不定提点效果会更加明显,有兴趣的同学也可是在NLP任务中试试Involution的效果,效果应该会比TextCNN会好一些,说不定能达到跟Transformer差不多的结果。
1. 论文和代码地址
Involution: Inverting the Inherence of Convolution for Visual Recognition
论文地址:https://arxiv.org/pdf/2103.06255.pdf
代码地址:https://github.com/d-li14/involution
核心代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/conv/Involution.py
2. Motivation
前面说到了CNN的空间不变性 (spatial-agnostic)和通道特异性 (channel-specific)有一些优点,但这些优点有时候也会变成缺点。
CNN在空间不变性表现在:卷积核在所有的空间位置上都共享参数,那就会导致不同空间位置的局部空间建模能力受限,并无法有效的捕获空间上长距离的关系。
CNN的通道特异性指的是:输出特征的每个通道信息是由输入特征的所有通道信息聚合而来,并且参数不共享,所以就会导致参数和计算量比较大。并且,也有一些工作表明了不同输出通道对应的卷积滤波器之间是存在信息冗余的,因此对每个输出通道都使用不同的卷积核这一方式其实是并不高效的。
因此,基于发现的这两个缺点,作者采用了一种非常“简单粗暴”的方式来解决这两个缺点——把整两个性质颠倒一下,提出一个“空间特异性”和“通道不变性”的算子。
3. 方法
3.1. 卷积的过程
在介绍Involution之前,我们先回顾一下正常卷积的过程:
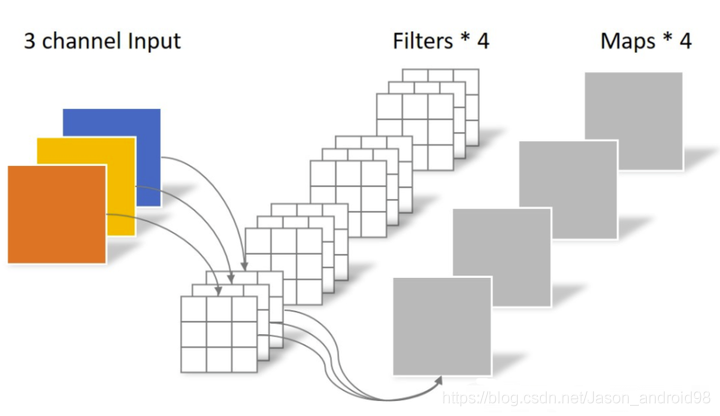 (图来自https://zhuanlan.zhihu.com/p/339835983)
(图来自https://zhuanlan.zhihu.com/p/339835983)
如上图所示,正常卷积的卷积核大小为,可以看出卷积核矩阵的大小,我们也可以看出,卷积的参数与输入特征的大小H和W是无关的,因此具有空间不变性;与输入和输出通道的数量是呈正比的,因此具有通道特异性。可以表示成下面的公式: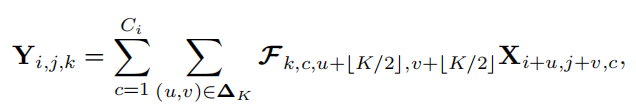
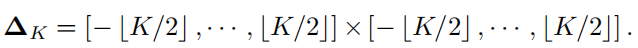
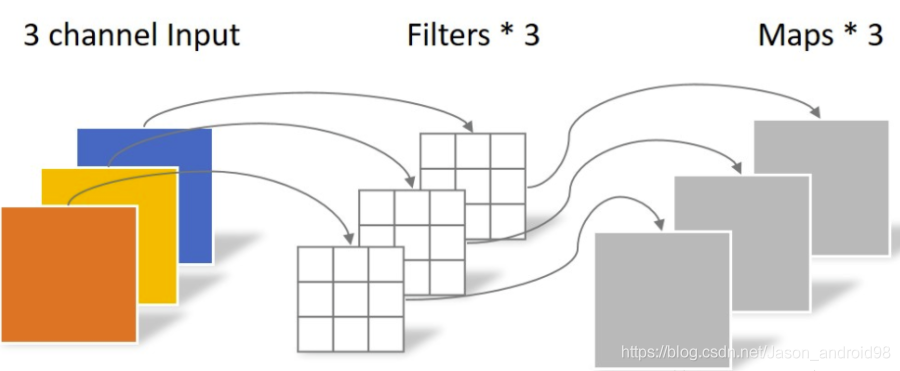
(图来自https://zhuanlan.zhihu.com/p/339835983)
除了正常的卷积,如上图所示,还有一种轻量级的卷积Depthwise Conv在深度学习中使用也非常多,Depthwise卷积是正常卷积的一种特殊情况(卷积的groups数等于输入通道的数量),可以用下面的公式表示: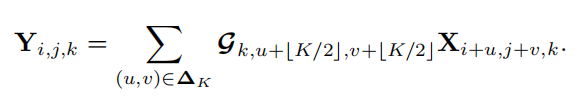
3.2. Involution生成kernel的过程
在每一个不同的位置,Involution都有不同的kernel,所以Involution的kernel是和输入特征的大小是相关的,特征大小为,计算方式和卷积很像:
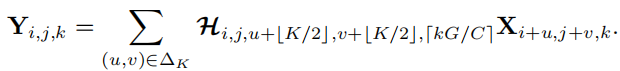
与卷积不同,Involution的kernel是根据输入特征自动生成的,本文的具体操作是对输入的特征进行特征的映射来形成动态的卷积核:
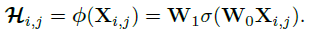
其中代表输入的特征,分别为特征映射的矩阵(具体实现的时候可以用卷积),代表Involution的kernel在上的参数。
和分别用来压缩和拓展通道数(类似SENet的第一个和第二个FC),将特征从个通道压缩为个通道,将特征从个通道拓展为个通道。这里是分组的数量,每个组内的kernel共享参数。
这一步的伪代码为:
# kernel generation, Eqn.(6)
kernel = span(reduce(o(x))) # B,KxKxG,H,W
kernel = kernel.view(B, G, K*K, H, W).unsqueeze(2)
卷积其实还有一个缺点就是,他的卷积核是静态的,与输入的特征无关,是一个Data-independent的操作;但是本文的Involution是根据输入特征,在不同的位置,动态生成不同的卷积核,是一个Data-dependent的操作。这一点也是能够提点的一个原因。
3.3. Involution的操作解析
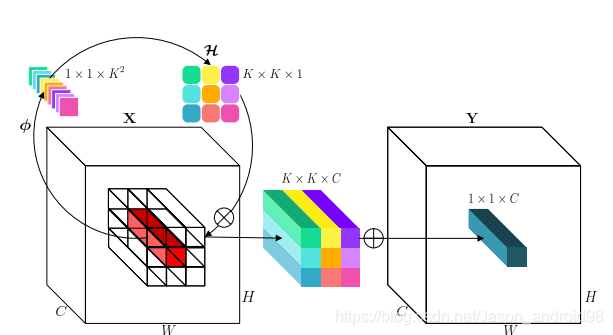
如上图所示,Involution的操作其实和Convolution的操作非常相似,都是用以当前点为中心的的区域与Involution的kernel的进行element-wise product操作,然后将区域内的信息进行求和,得到输出的特征。
那么,在实现上,怎么获取每个点的的的区域呢?作者采用的unfold操作,经过这个操作之后,就能够获得每个点对应的的的区域(有点类似手动卷积)。伪代码如下:

从上面的计算中,大家应该都发现了Involution的一个BUG,就是它不能像卷积一样灵活的改变的通道的数量。因为Involution其实就是对空间上,用不同的Data-dependent的卷积滤波器进行乘积、求和操作,在通道上并没有进行改变维度的映射,每个group里,通道维度上都是用了相同的kernel。如果需要改变通道维度,就需要在Involution的后面再接上一个1x1的卷积(Point-wise Conv),那这么做就相当于深度可分离卷积(先在空间上卷积,然后在通道上卷积,只不过这里的卷积是Data-dependent的卷积)。
3.4. Involution和Self-Attention的对比
Self-Attention可以表示成下面的公式:
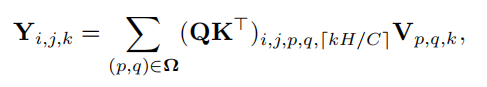
Involution可以表示成下面的公式:
我们可以发现:
1.Self-Attention的分head操作就是就是Involution的分组操作。
2.Self-Attention的操作是求权重的过程,Involution的也是求权重的过程。
这么说来,Self-Attention其实就是Involution的某一种特殊的情况。
但也不能完全这么说,Self-Attention中计算权重矩阵时通过Q和K进行点积来求相似度,但是Involution的求权重矩阵时通过两个可学习的矩阵,通过梯度更新来学习权重,所以本质上SA和Involution计算权重的时候还是有很大区别的。如果说相似,个人觉得这篇文章的方法还是跟SENet比较相似,都是根据输入的特征,通过两个可学习矩阵(FC)学出一个权重,然后将权重乘到原来的特征,这么看来Involution不就是空间维度上的SENet上吗?只不过Involution还引入了卷积的计算性质。所以个人觉得,这篇工作有点像是Spatial SENet+Convolution(如有不同的观点,欢迎大家一起交流) 。
4.实验
4.1. ImageNet分类
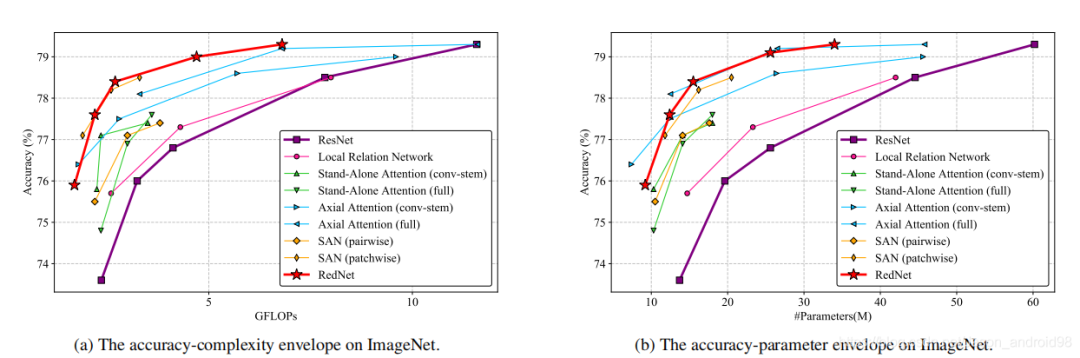
可以看出基于Involution的RedNet,性能和效率优于ResNet和其他self-attention做算子的SOTA模型。
4.2. COCO目标检测和实例分割
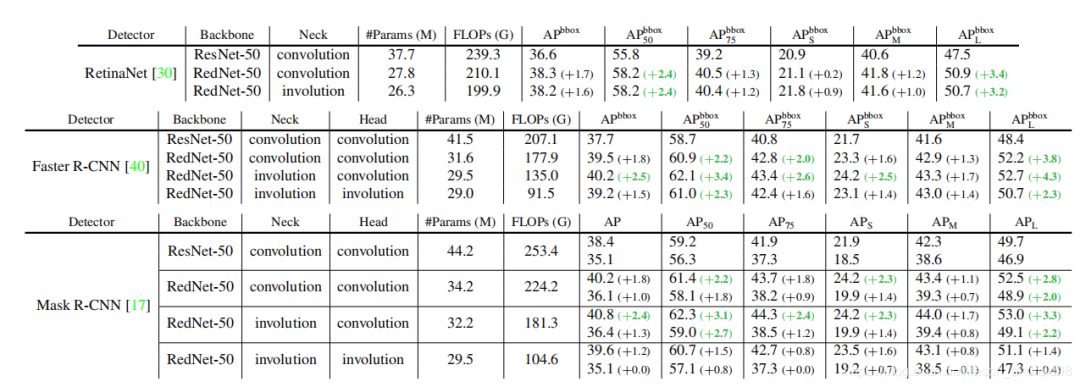
可以看出,相比于ResNet,RedNet在性能上都能有明显提升,或者在计算量上都有明显下降。
4.3. 语义分割

在Cityscapes分割任务中,RedNet相比于ResNet能够有明显的性能提升。
4.4. 可视化
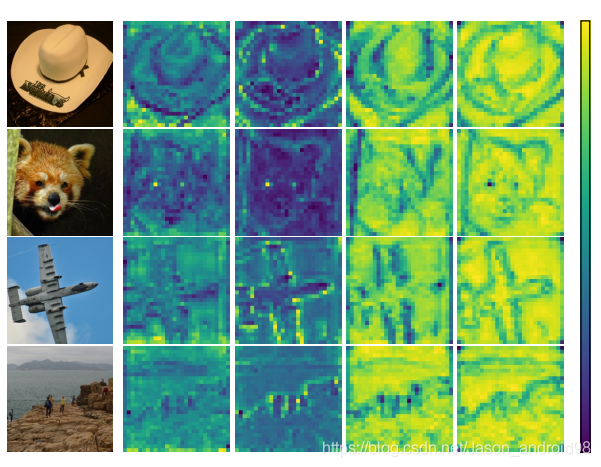
通过可视化,我们可以发现kernel对空间上不同位置是有不同的关注度的,这也证实了Involution空间特异性的有效性;基于每一行对比不同的group,我们发现,不同组的kernel编码不同的语义信息。
4.5. 消融实验
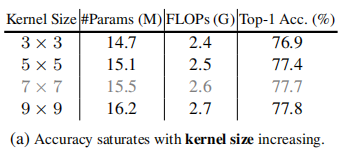
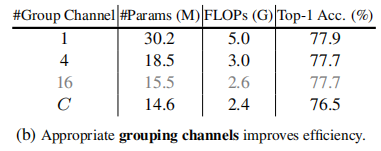
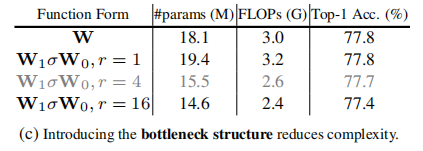
从消融实验可以看出,更大的kernel size、更少的分组数、更小的reduction ratio都有助于模型获得更好的性能。
5. 总结
作者对Convolution的形成进行了rethink,并提出了一种的新的算子,相比于ResNet,本文在三大任务上确实有比较大的优越性。在参数量和计算复杂度上,相比于Convolution,Involution有明显的优势。但是Involution也有一个很明显的缺点,由于Involution在通道维度上采用了参数共享,所以就会导致通道上的信息不能进行很好的交互。
个人觉得Convlution和Involution像是两种极端,前者更加关注于通道进行的交互,所以在空间维度上进行参数共享;后者更加关注于空间维度上的信息建模,所以在通道维度上进行了参数共享。(由于平移不变性这个假设偏置,所以看起来还是Convolution会更加合理一些。)但是在实际应用中真的是非A即B的吗?在实际应用中很可能是通道信息和空间信息都是非常重要的,所以如果能够在空间和通道维度上都基于一定的偏置进行必要的参数共享,达到更好的speed-accuracy trade off,这或许会是一个更有意思的工作。
关于文章有任何问题,欢迎在评论区留言或者添加作者微信: xmu_xiaoma