
【机器学习】随机森林是我最喜欢的模型
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
TensorFlow 决策森林 (TF-DF) 现已开源,该库集成了众多 SOTA 算法,不需要输入特征,可以处理数值和分类特征,为开发者节省了大量时间。


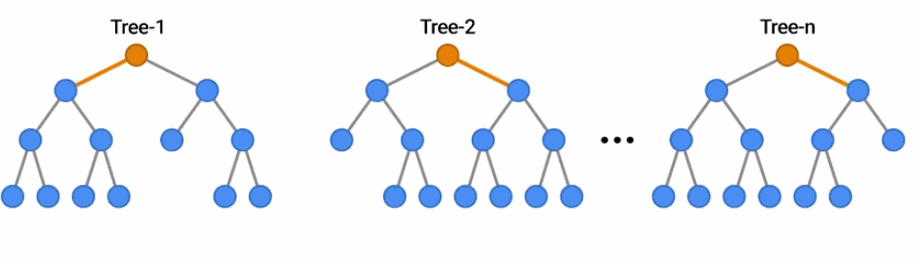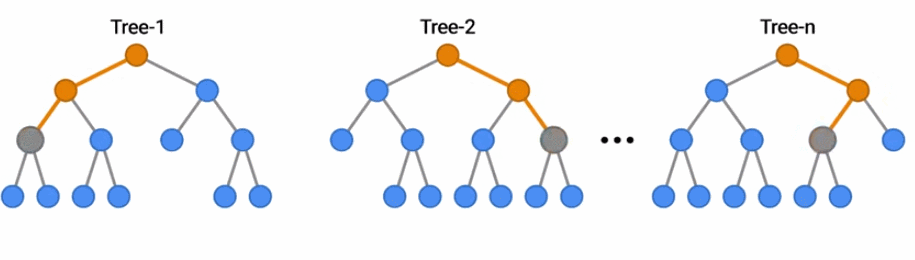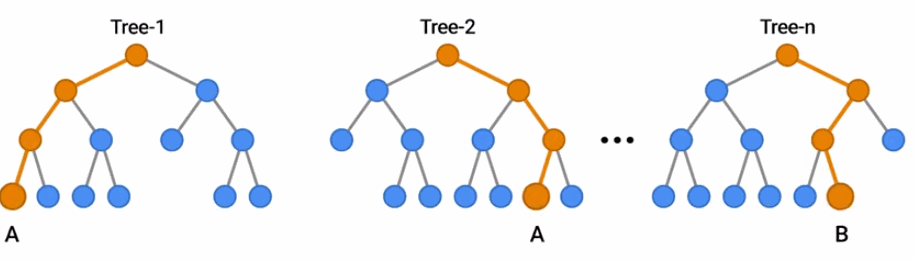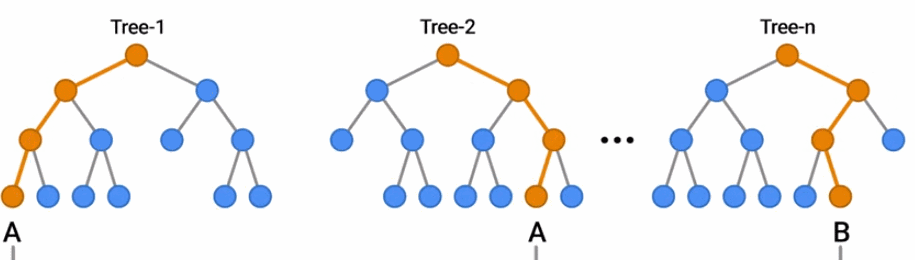
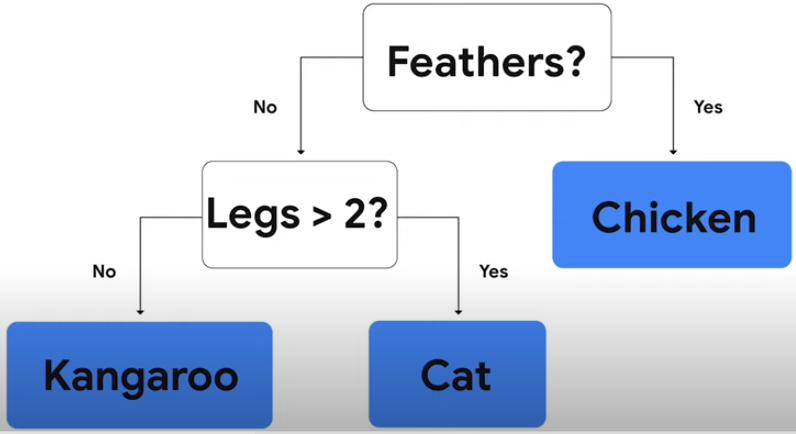
对初学者来说,开发和解释决策森林模型更容易。不需要显式地列出或预处理输入特征(因为决策森林可以自然地处理数字和分类属性)、指定体系架构(例如,通过尝试不同的层组合,就像在神经网络中一样),或者担心模型发散。一旦你的模型经过训练,你就可以直接绘制它或者用易于解释的统计数据来分析它。
高级用户将受益于推理时间非常快的模型(在许多情况下,每个示例的推理时间为亚微秒)。而且,这个库为模型实验和研究提供了大量的可组合性。特别是,将神经网络和决策森林相结合是很容易的。

TF-DF 提供了一系列 SOTA 决策森林训练和服务算法,如随机森林、CART、(Lambda)MART、DART 等。
基于树的模型与各种 TensorFlow 工具、库和平台(如 TFX)更容易集成,TF-DF 库可以作为通向丰富 TensorFlow 生态系统的桥梁。
对于神经网络用户,你可以使用决策森林这种简单的方式开始 TensorFlow,并继续探索神经网络。
项目地址:https://github.com/tensorflow/decision-forests
TF-DF 网站地址:https://www.tensorflow.org/decision_forests
Google I/O 2021 地址:https://www.youtube.com/watch?v=5qgk9QJ4rdQ

# Install TensorFlow Decision Forests!pip install tensorflow_decision_forests# Load TensorFlow Decision Forestsimport tensorflow_decision_forests as tfdf# Load the training dataset using pandasimport pandastrain_df = pandas.read_csv("penguins_train.csv")# Convert the pandas dataframe into a TensorFlow datasettrain_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_df, label="species")# Train the modelmodel = tfdf.keras.RandomForestModel()model.fit(train_ds)
# Load the testing datasettest_df = pandas.read_csv("penguins_test.csv")# Convert it to a TensorFlow datasettest_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df, label="species")# Evaluate the modelmodel.compile(metrics=["accuracy"])print(model.evaluate(test_ds))# >> 0.979311# Note: Cross-validation would be more suited on this small dataset.# See also the "Out-of-bag evaluation" below.# Export the model to a TensorFlow SavedModelmodel.save("project/my_first_model")
tfdf.model_plotter.plot_model_in_colab(model, tree_idx=0)
每个特性使用了多少次?
模型训练的速度有多快(树的数量和时间)?
节点在树结构中是如何分布的(比如大多数 branch 的长度)?
# Print all the available information about the modelmodel.summary()Input Features (7):>> bill_depth_mmbill_length_mmbody_mass_g>>...Variable Importance:1. "bill_length_mm" 653.000000 ################...Out-of-bag evaluation: accuracy:0.964602 logloss:0.102378Number of trees: 300Total number of nodes: 4170...# Get feature importance as a arraymodel.make_inspector().variable_importances()["MEAN_DECREASE_IN_ACCURACY"][("flipper_length_mm", 0.149),>> ("bill_length_mm", 0.096),>> ("bill_depth_mm", 0.025),>> ("body_mass_g", 0.018),>> ("island", 0.012)]
# List all the other available learning algorithmstfdf.keras.get_all_models()[tensorflow_decision_forests.keras.RandomForestModel,>> tensorflow_decision_forests.keras.GradientBoostedTreesModel,>> tensorflow_decision_forests.keras.CartModel]# Display the hyper-parameters of the Gradient Boosted Trees model? tfdf.keras.GradientBoostedTreesModelA GBT (Gradient Boosted [Decision] Tree) is a set of shallow decision trees trained sequentially. Each tree is trained to predict and then "correct" for the errors of the previously trained trees (more precisely each tree predicts the gradient of the loss relative to the model output).....Attributes:num_trees: num_trees: Maximum number of decision trees. The effective number of trained trees can be smaller if early stopping is enabled. Default: 300.max_depth: Maximum depth of the tree. `max_depth=1` means that all trees will be roots. Negative values are ignored. Default: 6....# Create another model with specified hyper-parametersmodel = tfdf.keras.GradientBoostedTreesModel(num_trees=500,growing_strategy="BEST_FIRST_GLOBAL",max_depth=8,split_axis="SPARSE_OBLIQUE",)# Evaluate the modelmodel.compile(metrics=["accuracy"])print(model.evaluate(test_ds))#0.986851
也可以加一下老胡的微信 围观朋友圈~~~
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
评论