
对比SQL,学习Pandas操作:group_concat如何实现?
本文主要讲解的是如何利用pandas来实现SQL中的group_concat操作。
group_concat
SQL或者MySQL中的group_concat到底实现的什么功能呢?看例子来说明。
下面是表information中存储的一份简单数据,两个字段id和name:
+----+-----+
| id | name |
+------+---+
|1 | 10 |
|1 | 20 |
|1 | 20 |
|2 | 20 |
|3 | 200 |
|3 | 500 |
方式1:默认情形
我们以id来进行分组,将name放在同一行,同时用逗号隔开:
select
id
,group_concat(name) as name
from information
group by id;
结果为:
|id| name|
|1 |10,20,20|
|2 |20 |
|3 |200,500|
方式2:指定符号
上面的结果中默认是逗号(英文逗号)隔开的,我们还可以自己指定符号:
select
id
,group_concat(name separator ';') as name
from information
group by id;
结果则显示为:
|id| name|
|1 |10;20;20| -- 分号隔开
|2 |20 |
|3 |200;500|
方式3:去重显示
我们还可以以id分组,将冗余(重复的)的数据去掉,然后将剩下的放在一起;比如id=1的数据重复了20,我们希望只显示一个20:
加上了关键词distinct :
select
id
,group_concat(distinct name) as name
from information
group by id;
相应的结果显示为:
|id| name|
|1 |10,20| -- 只显示了一个20
|2 |20 |
|3 |200,500|
方式4:降序排列
在上面的全部情形中,数据都是升序排列,我们还可以降序:
select
id
,group_concat(name order by name desc) as name
from information
group by id;
那么显示的结果为:
-- 结果已经降序排列了
|id| name|
|1 |20,20,10|
|2 |20 |
|3 |500,200|
上面介绍的就是各种group_concat实现的效果,下面利用pandas来实现。
模拟数据
import pandas as pd
import numpy as np
df = pd.DataFrame({
"name":["小明","小明","小明","小红","小张","小张"],
"score":[10,20,20,20,200,500]
})
df
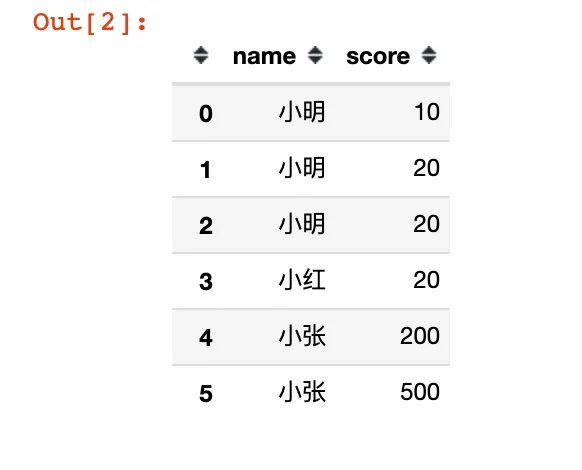
很清楚,我们需要将小明、小红、小张的score分组放在一起。
方式1:默认分组
实现默认分组情形,升序排列且不去重。主要是3个步骤:
1、通过groupby进行分组
2、分组之后通过list将score全部放在一个列表中
3、第三步只是进行了索引重排

方式2:指定符号
指定特定的符号,我们使用的join函数。因为这个函数只能操作字符串,所以我们需要将df中的数值型数据转成字符串:
df.astype(str)

方式3:去重显示
通过name字段进行分组,再对score采用unique函数。下面只是进行所以重排

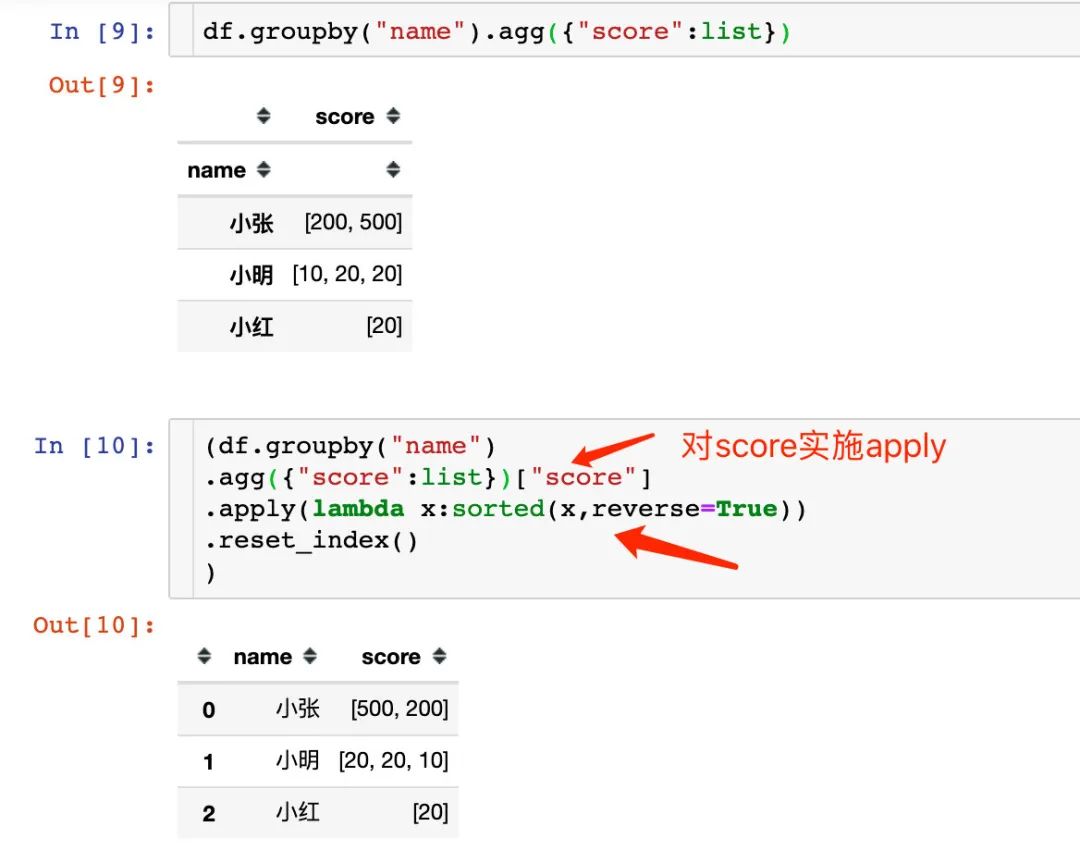
方式4:降序排列
1、我们先实现默认的升序排列
2、对score字段再次使用apply函数,通过对列表使用sorted函数来实现降序排列
亲爱的朋友,学会了吗?
评论