
SQL、Pandas和Spark:如何实现数据透视表?
导读
数据透视表是一个很重要的数据统计操作,最有代表性的当属在Excel中实现(甚至说提及Excel,个人认为其最有用的当属三类:好用的数学函数、便捷的图表制作以及强大的数据透视表功能)。所以,今天本文就围绕数据透视表,介绍一下其在SQL、Pandas和Spark中的基本操作与使用,这也是沿承这一系列的文章之一。

在上述简介中,有两个关键词值得注意:排列和汇总,其中汇总意味着要产生聚合统计,即groupby操作;排列则实际上隐含着使汇总后的结果有序。当然,如果说只实现这两个需求还不能完全表达出数据透视表与常规的groupby有何区别,所以不妨首先看个例子:
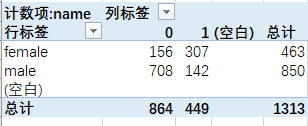
通过上表,明显可以看出女性中约有2/3的人得以生还,而男性中则仅有不到20%的人得以生还。当然,这是数据透视表的最基本操作,大家应该也都熟悉,本文不做过多展开。
值得补充的是:实际上为了完成不同性别下的生还人数,我们完全可以使用groupby(sex, survived)这两个字段+count实现这一需求,而数据透视表则仅仅是在此基础上进一步完成行转列的pivot操作而已。理解了数据透视表的这一核心功能,对于我们下面介绍数据透视表在三大工具中的适用将非常有帮助!

可以明显注意到该函数的4个主要参数:
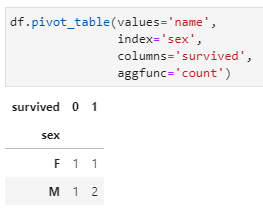
values:对哪一列进行汇总统计,在此需求中即为name字段;
index:汇总后以哪一列作为行,在此需求中即为sex字段;
columns:汇总后以哪一列作为列,在此需求中即为survived;
aggfunc:执行什么聚合函数,在此需求中即为count,该参数的默认参数为mean,但只适用于数值字段。
而后,分别传入相应参数,得到数据透视表结果如下:
上述需求很简单,需要注意以下两点:
pandas中的pivot_table还支持其他多个参数,包括对空值的操作方式等;
上述数据透视表的结果中,无论是行中的两个key("F"和"M")还是列中的两个key(0和1),都是按照字典序排序的结果,这也呼应了Excel中关于数据透视表的介绍。
Spark作为分布式的数据分析工具,其中spark.sql组件在功能上与Pandas极为相近,在某种程度上个人一直将其视为Pandas在大数据中的实现。在Spark中实现数据透视表的操作也相对容易,只是不如pandas中的自定义参数来得强大。
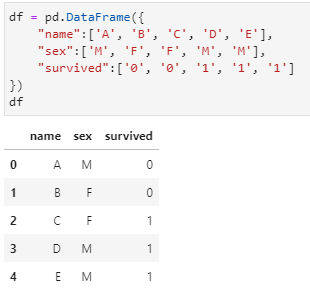
首先仍然给出在Spark中的构造数据:

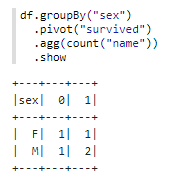
当然,注意到这里仍然是保持了数据透视表结果中行key和列key的有序。
这一系列的文章中,一般都是将SQL排在首位进行介绍,但本文在介绍数据透视表时有意将其在SQL中的操作放在最后,这是因为在SQL中实现数据透视表是相对最为复杂的。实际上,SQL中原生并不支持数据透视表功能,只能通过衍生操作来曲线达成需求。
上述在分析数据透视表中,将其定性为groupby操作+行转列的pivot操作,那么在SQL中实现数据透视表就将需要groupby和行转列两项操作,所幸的是二者均可独立实现,简单组合即可。
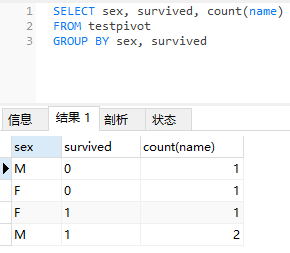
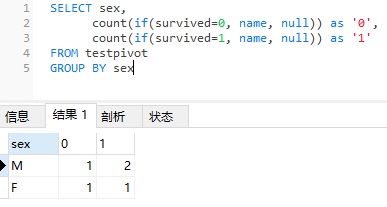
上述SQL语句中,仅对sex字段进行groupby操作,而后在执行count(name)聚合统计时,由直接count聚合调整为两个count条件聚合,即:
如果survived字段=0,则对name计数,否则不计数(此处设置为null,因为count计数时会忽略null值),得到的结果记为survived=0的个数;
如果survived字段=1,则对name计数,否则不计数,此时得到的结果记为survived=1的个数。
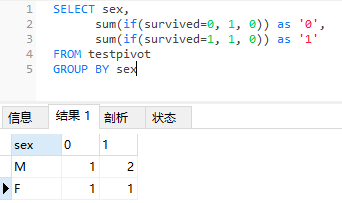
当然,二者的结果是一样的。
以上就是数据透视表在SQL、Pandas和Spark中的基本操作,应该讲都还是比较方便的,仅仅是在SQL中需要稍加使用个小技巧。希望能对大家有所帮助,如果觉得有用不妨点个在看!
相关阅读: