对比Excel,学习pandas数据透视表
↑↑↑关注后"星标"简说Python
人人都可以简单入门Python、爬虫、数据分析 简说Python推荐 来源:凹凸数据 作者:黄同学
大家好,我是老表,今天给大家分享下Excel里的透视表操作,以及如何利用python实现,记得看完点赞。
Excel中做数据透视表
① 选中整个数据源;

② 依次点击“插入”—“数据透视表”
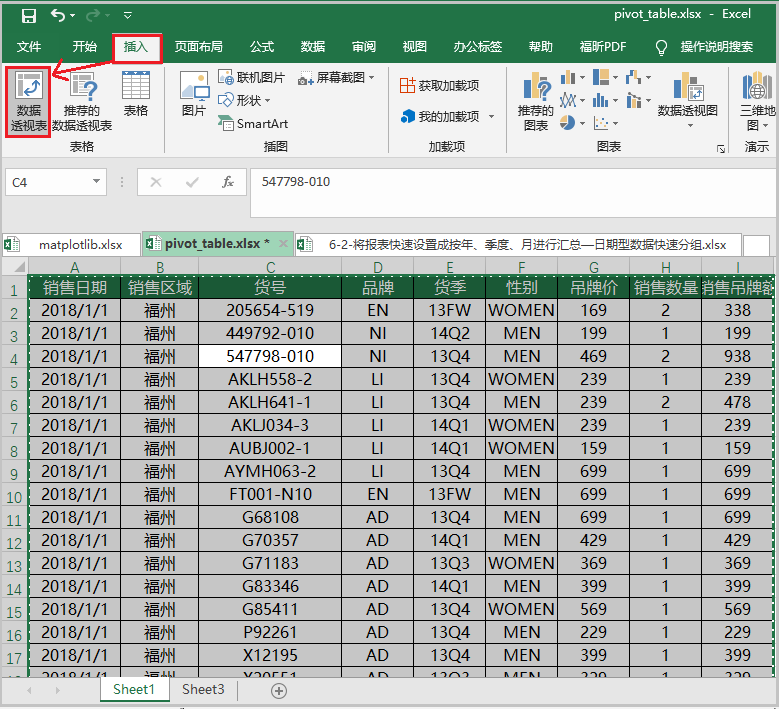
③ 选择在Excel中的哪个位置,插入数据透视表

④ 然后根据实际需求,从不同维度展示结果
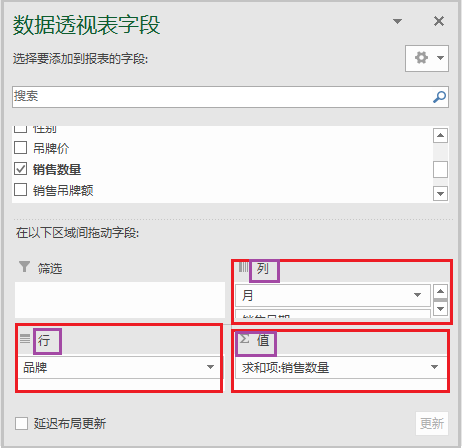
⑤ 结果如下
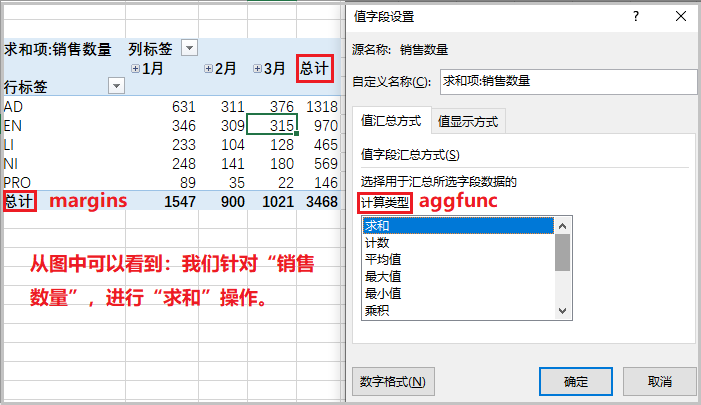
pandas用pivot_table()做数据透视表
1)语法格式
pd.pivot_table(data,index=None,columns=None,
values=None,aggfunc='mean',
margins=False,margins_name='All',
dropna=True,fill_value=None)
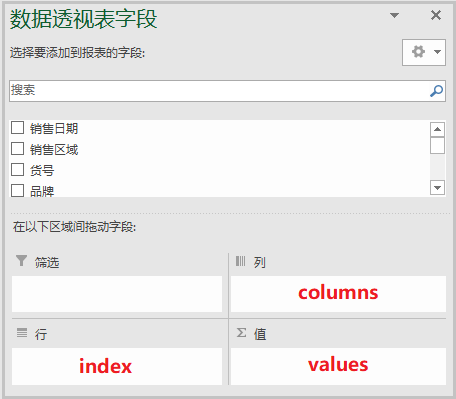
2)对比excel,说明上述参数的具体含义
参数说明:
data 相当于Excel中的"选中数据源";
index 相当于上述"数据透视表字段"中的行;
columns 相当于上述"数据透视表字段"中的列;
values 相当于上述"数据透视表字段"中的值;
aggfunc 相当于上述"结果"中的计算类型;
margins 相当于上述"结果"中的总计;
margins_name 相当于修改"总计"名,为其它名称;
下面几个参数,用的较少,记住干嘛的,等以后需要就百度。
dropna 表示是否删除缺失值,如果为True时,则把一整行全作为缺失值删除;
fill_value 表示将缺失值,用某个指定值填充。
案例说明
1)求出不同品牌下,每个月份的销售数量之和
① 在Excel中的操作结果如下
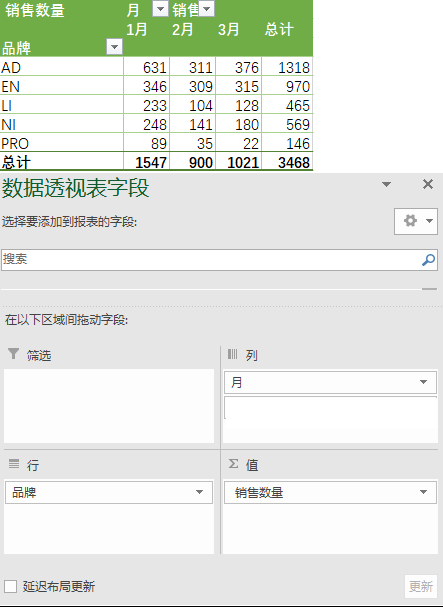
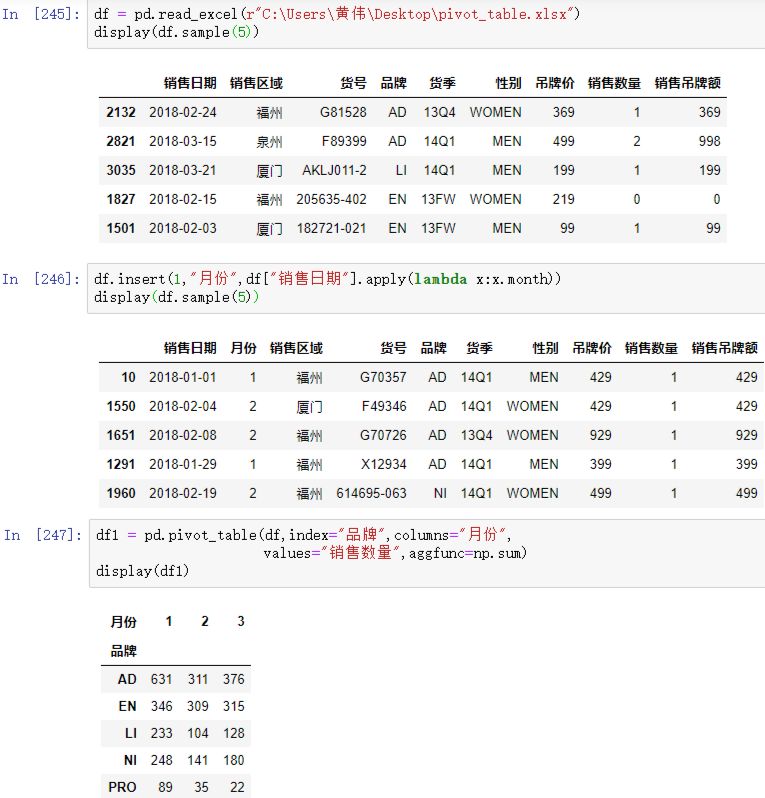
② 在pandas中的操作如下
df = pd.read_excel(r"C:\Users\黄伟\Desktop\pivot_table.xlsx")
display(df.sample(5))
df.insert(1,"月份",df["销售日期"].apply(lambda x:x.month))
display(df.sample(5))
df1 = pd.pivot_table(df,index="品牌",columns="月份",
values="销售数量",aggfunc=np.sum)
display(df1)结果如下:
2)求出不同品牌下,每个地区、每个月份的销售数量之和
① 在Excel中的操作结果如下
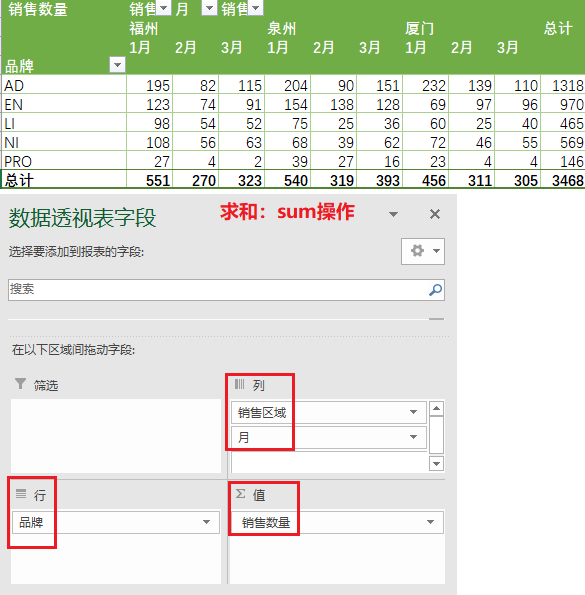
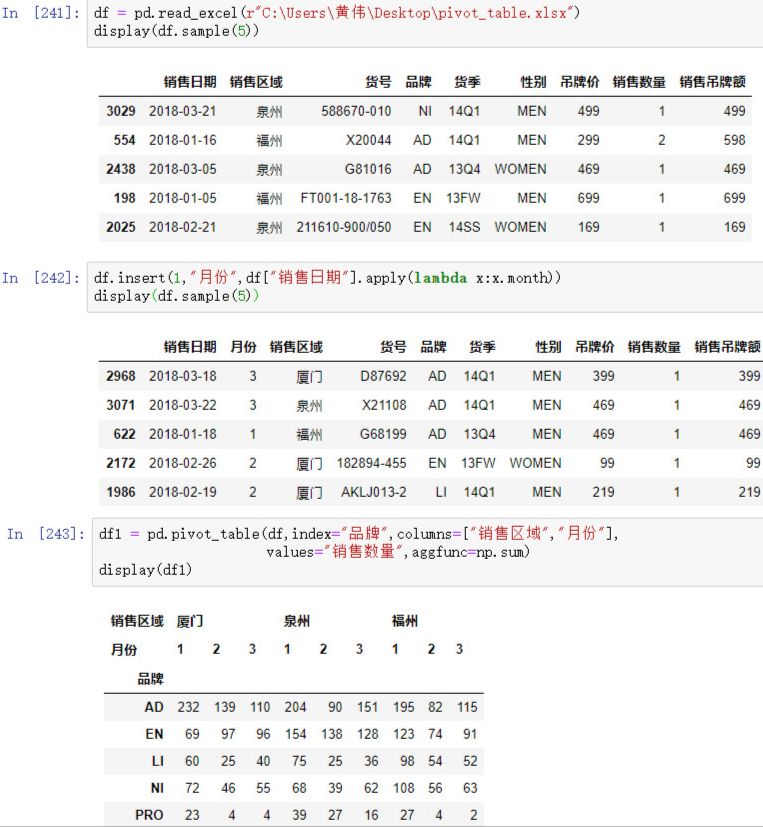
② 在pandas中的操作如下
df = pd.read_excel(r"C:\Users\黄伟\Desktop\pivot_table.xlsx")
display(df.sample(5))
df.insert(1,"月份",df["销售日期"].apply(lambda x:x.month))
display(df.sample(5))
df1 = pd.pivot_table(df,index="品牌",columns=["销售区域","月份"],
values="销售数量",aggfunc=np.sum)
display(df1)
结果如下:
3)求出不同品牌不同地区下,每个月份的销售数量之和
① 在Excel中的操作结果如下
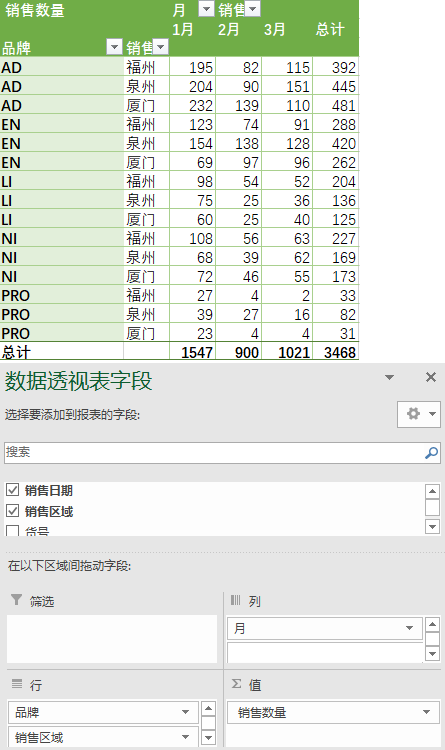
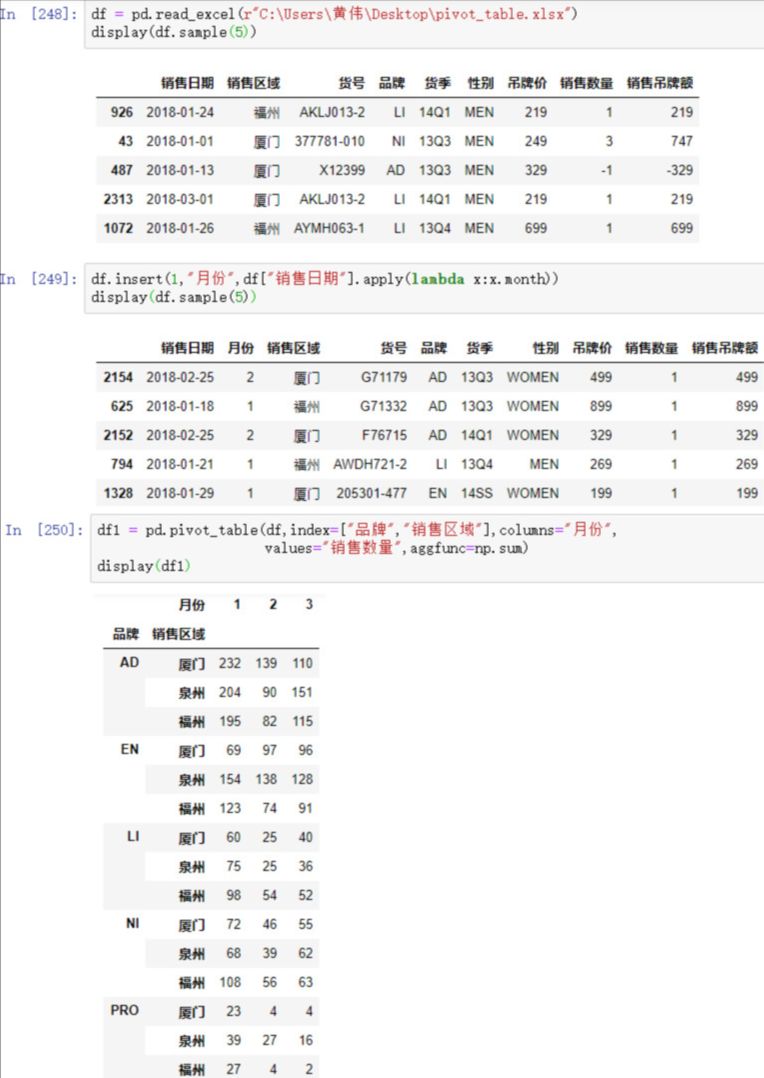
② 在pandas中的操作如下
df = pd.read_excel(r"pivot_table.xlsx")
display(df.sample(5))
df.insert(1,"月份",df["销售日期"].apply(lambda x:x.month))
display(df.sample(5))
df1 = pd.pivot_table(df,index=["品牌","销售区域"],columns="月份",
values="销售数量",aggfunc=np.sum)
display(df1)
结果如下:
4)求出不同品牌下的“销售数量之和”与“货号计数”
① 在Excel中的操作结果如下
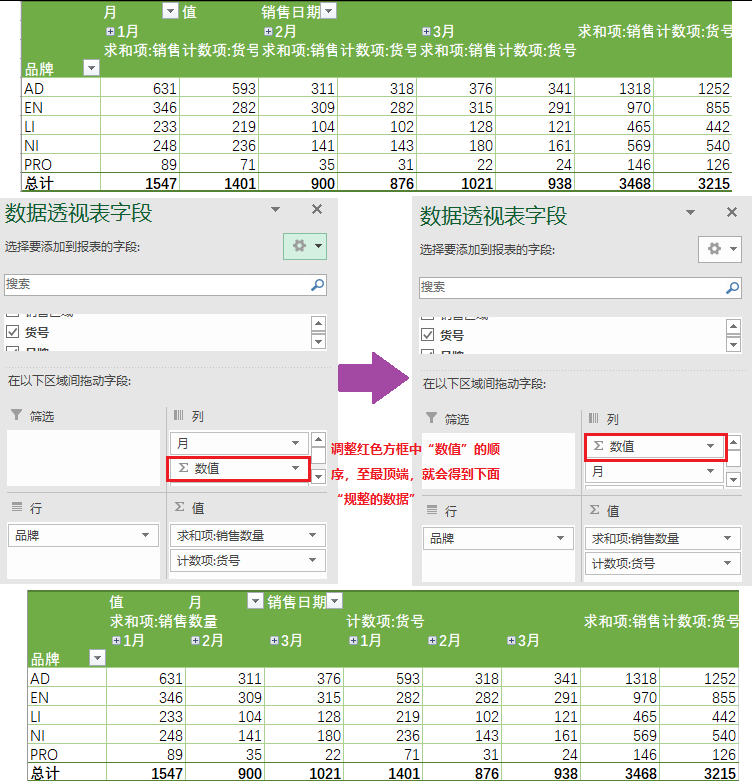
② 在pandas中的操作如下
df = pd.read_excel(r"pivot_table.xlsx")
display(df.sample(5))
df.insert(1,"月份",df["销售日期"].apply(lambda x:x.month))
display(df.sample(5))
df1 = pd.pivot_table(df,index="品牌",columns="月份",
values=["销售数量","货号"],
aggfunc={"销售数量":"sum","货号":"count"},
margins=True,margins_name="总计")
display(df1)
结果如下:

--END--
留言赠书
赠书规则:给本文点赞("在看"不作要求),扫描下方二维码,添加老表的微信。把点赞截图发给我,我会发送抽奖码给大家,时间截止至05月24号 20:00。可获得《海量数据处理与大数据技术实战》赠书一本。
扫码即可加我微信
观看朋友圈,获取最新学习资源
注意:中奖者24小时内,微信私聊我回复:书名+姓名+电话+收件地址即可领取,逾期不候!为了大家都有机会中奖,本月已经中过书的朋友,再次中奖将不再赠书。
本批书籍由 北京大学出版社 赞助,再次致谢。也欢迎大家自行前往购买支持。
简说Python 投稿规则及激励
规则:必须是自己的原创文章,和Python相关技术文章,形式不限制(文字、图文、漫画等),字数800+,在微信公众号首发。
激励
根据文章内容 字数 分为两种基础和深度
基础文章:每投稿两篇可以获得技术相关图书一本 从书单里选
深度文章:每1k字50-100元(代码不算)
额外激励
文章阅读量超过2000,激励50元
文章被同量级大号转载次数5次及以上,激励100元
长期投稿作者还有额外激励,技术能力可以的,还可以一起做项目,接私活,内推等。
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
“点赞”传统美德不能丢