多模态数据的行为识别综述
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
王帅琛, 黄倩, 张云飞, 李兴, 聂云清, 雒国萃. 2022. 多模态数据的行为识别综述. 中国图象图形学报, 27(11): 3139-3159.

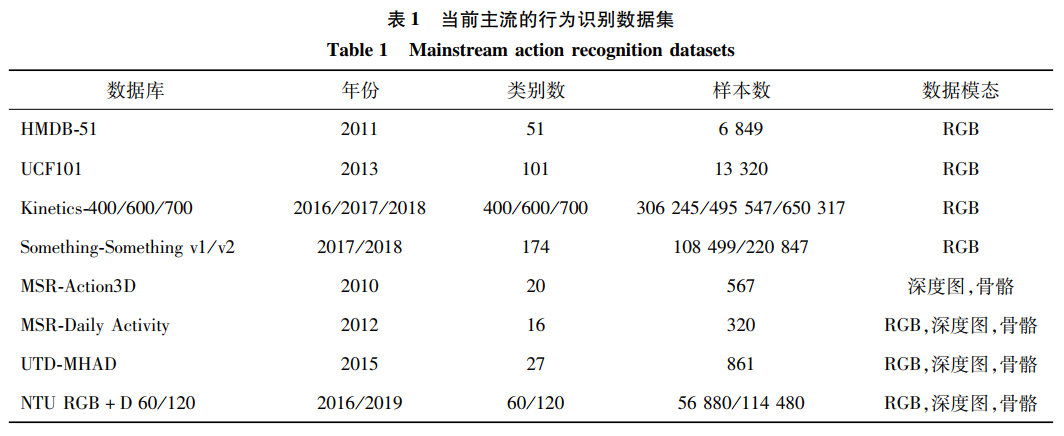


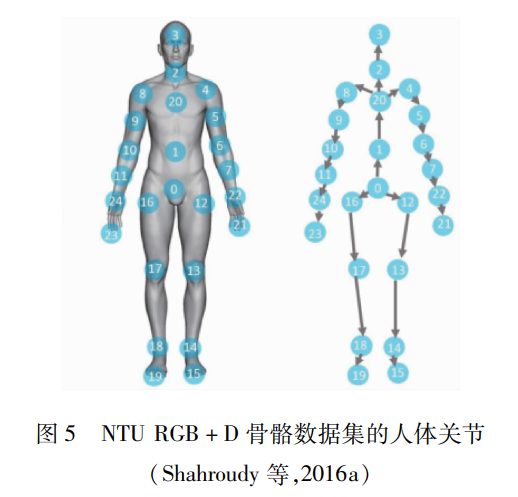


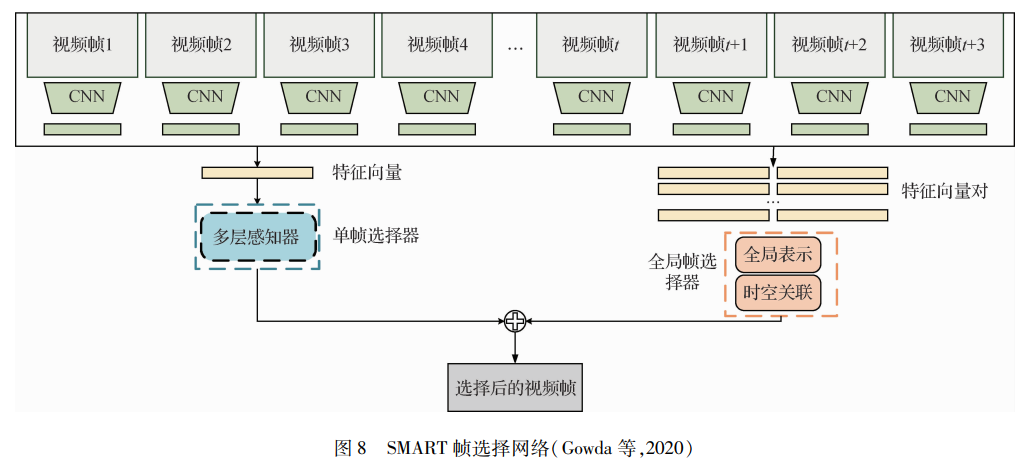
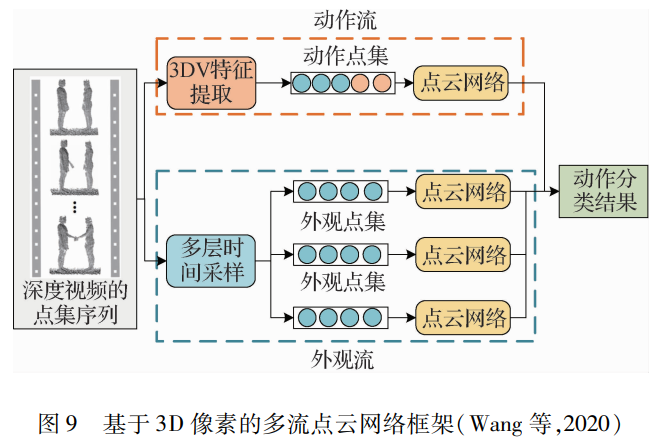


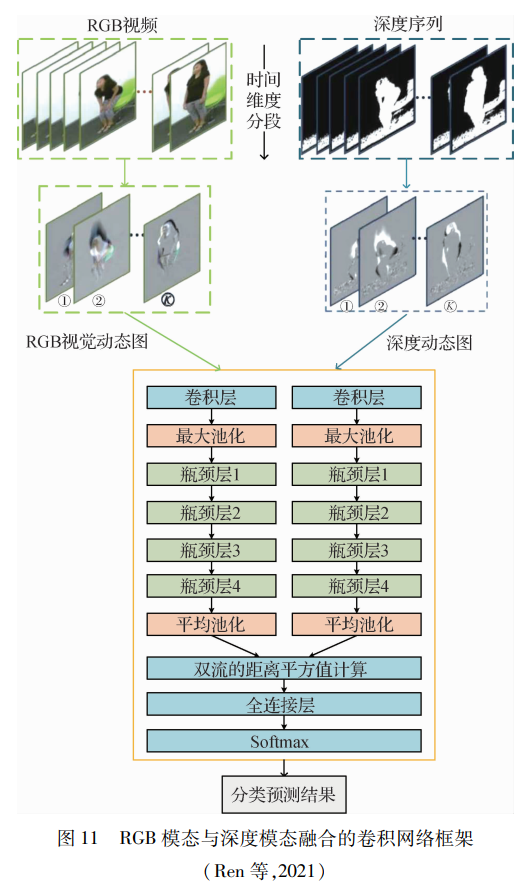

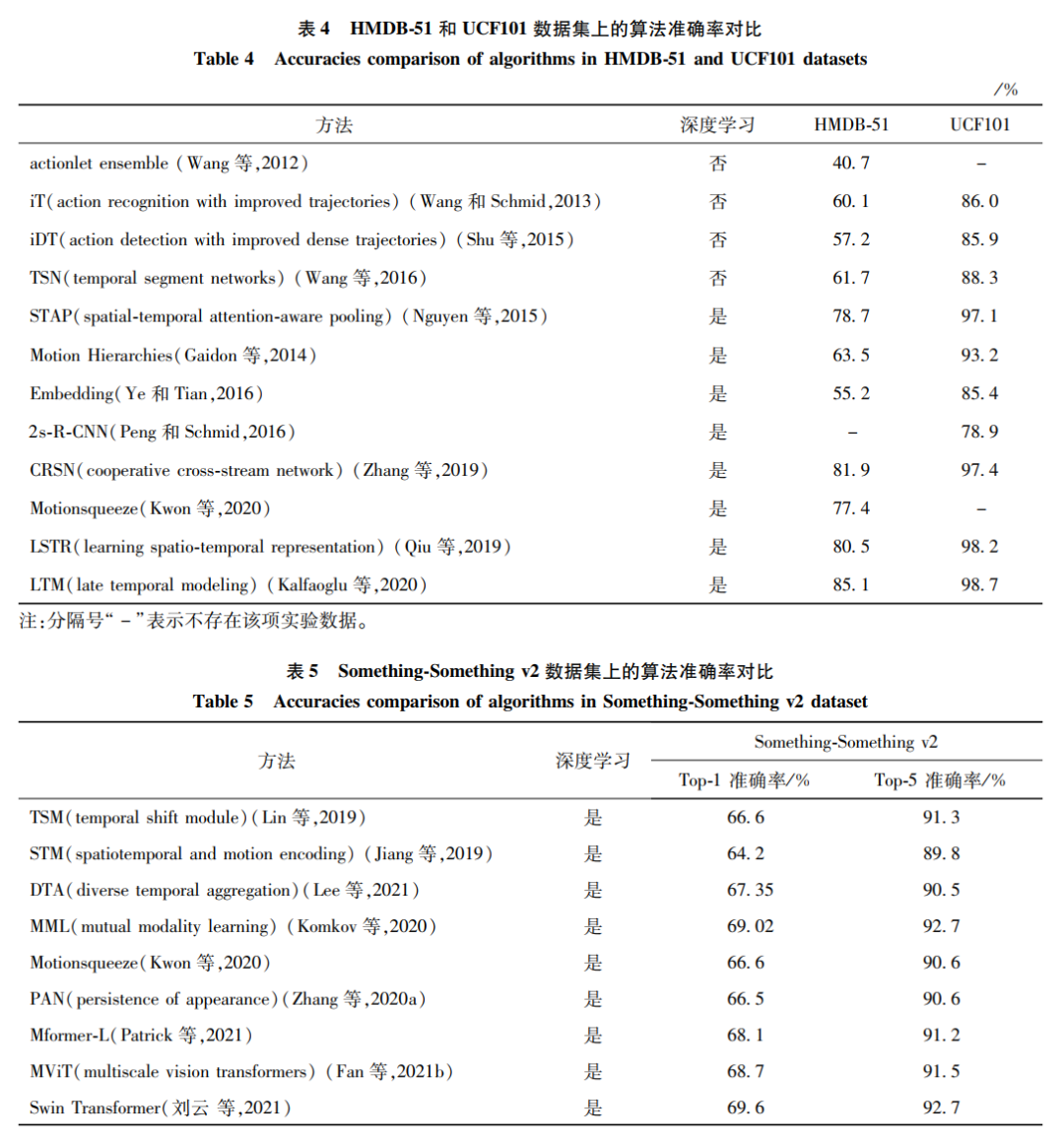


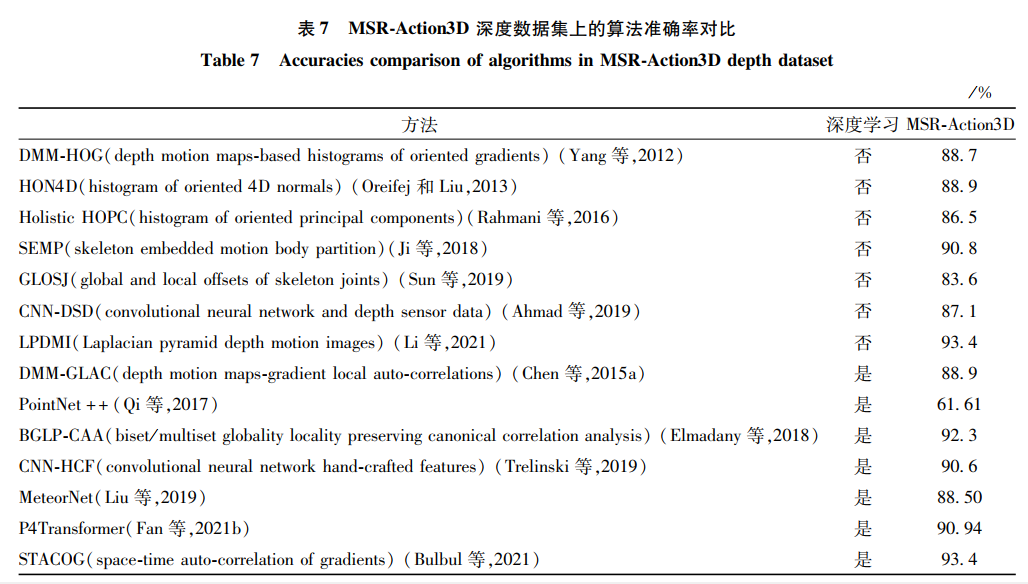
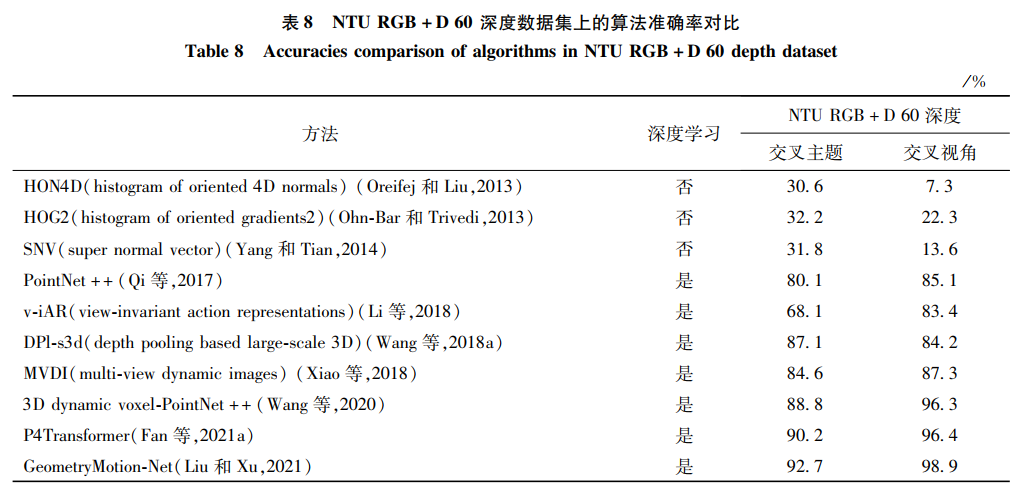
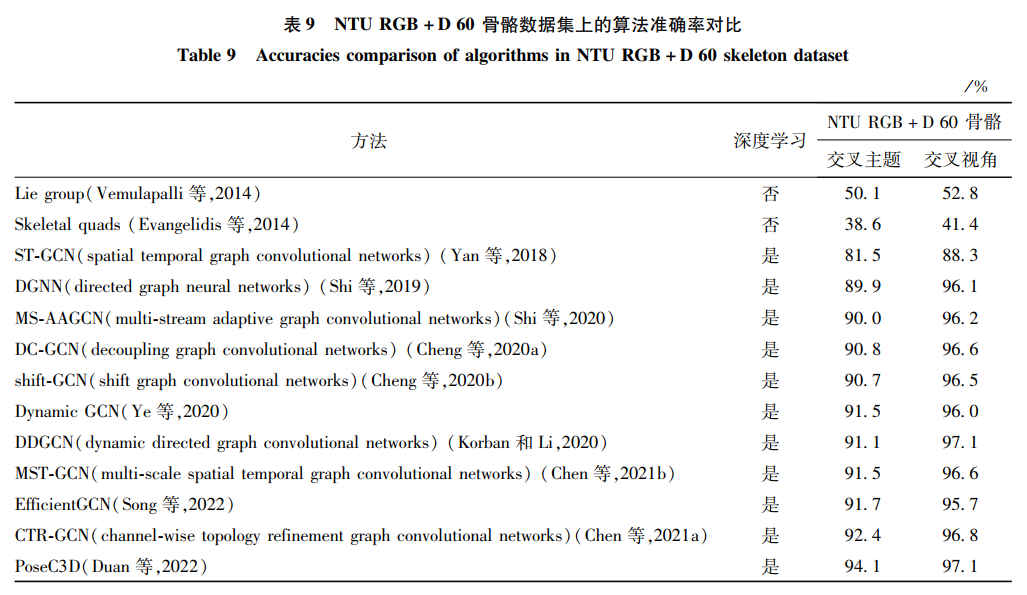
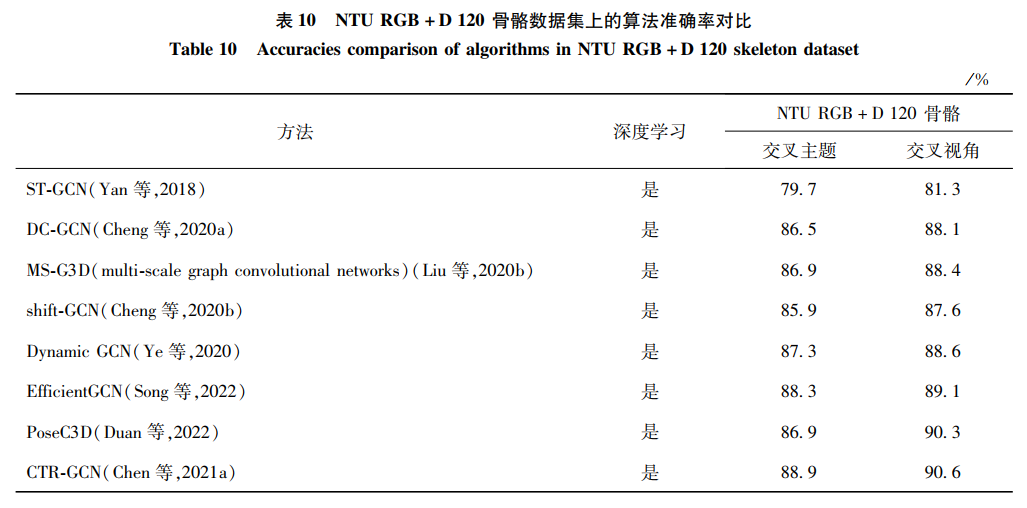
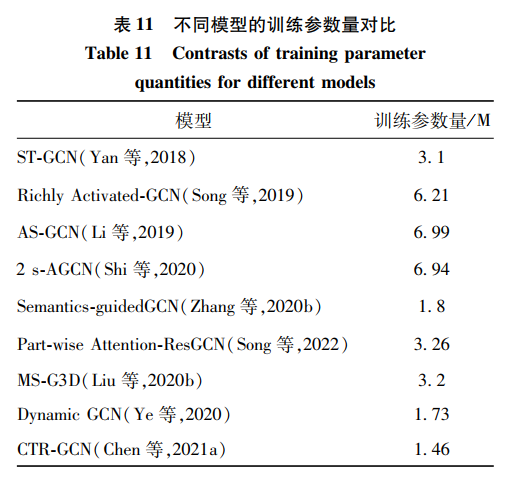

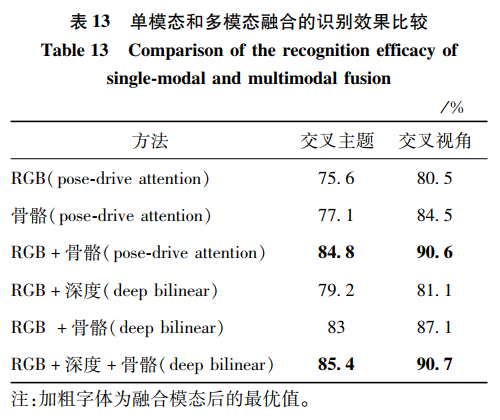
本文仅做学术分享,如有侵权,请联系删文。
评论
 下载APP
下载APP点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
王帅琛, 黄倩, 张云飞, 李兴, 聂云清, 雒国萃. 2022. 多模态数据的行为识别综述. 中国图象图形学报, 27(11): 3139-3159.
本文仅做学术分享,如有侵权,请联系删文。