
用于道路场景实时准确语义分割的深度双分辨率网络
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


语义分割是自动驾驶汽车了解周围场景的关键技术。对于实际的自动驾驶汽车来说,为了获得高精度的分割结果而花费大量的推理时间是不可取的。最近的方法使用轻量级架构(编码器、解码器或双通道)或对低分辨率图像进行推理,实现了非常快的场景解析,甚至在单个1080Ti GPU上运行超过100 FPS。然而,这些实时方法和基于膨胀骨架的模型在性能上仍然存在明显的差距。为了解决这一问题,作者提出了一种新型的深度双分辨率网络(DDRNets)用于道路场景的实时语义分割。此外,作者还设计了一种新的上下文信息提取器——深度聚合金字塔池模块(Deep Aggregation Pyramid Pooling Module, DAPPM),以扩大有效的接受域,融合多尺度上下文。作者的方法在城市景观和CamVid数据集的准确性和速度之间实现了最新的最先进的平衡。特别,在2080Ti GPU,DDRNet-23-slim收益率77.4% mIoU 109 FPS城市测试集和74.4%在230 FPS mIoU CamVid测试集,没有利用注意力机制,pretraining更大的语义分割数据集或推理加速度,DDRNet-39达到80.4%的测试mIoU在城市23 FPS。由于广泛使用的测试增强,作者的方法仍然优于大多数最先进的模型,需要更少的计算。守则和训练过的模型将向公众开放。
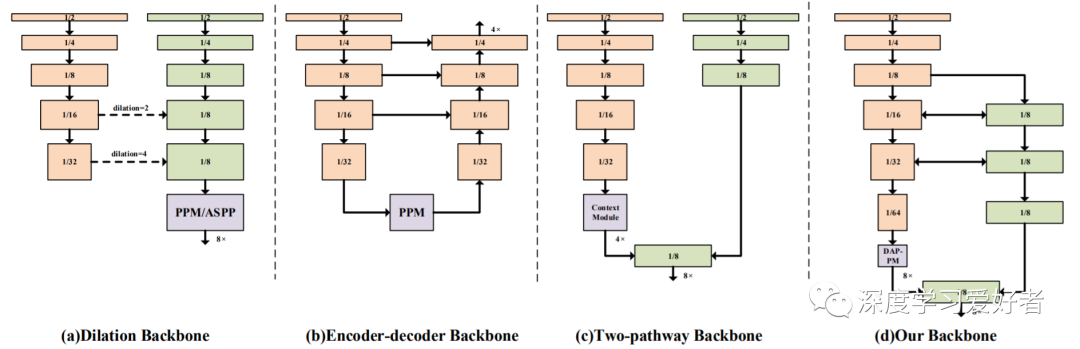
本文受HRNet的启发,提出了一种具有深度高分辨率表示能力的深度双分辨率网络,用于高分辨率图像的实时语义分割,特别是针对道路驾驶图像。作者的DDRNet从一个主干开始,然后分成两个不同分辨率的平行深分支。一个深度分支生成相对高分辨率的特征图,另一个通过多次下采样操作提取丰富的上下文信息。为了实现有效的信息融合,在两个分支之间建立了多个双边连接。此外,作者还提出了一种新的模块DAPPM,该模块比普通的PPM模块能更充分地增加接收域,提取上下文信息。在对语义分割数据集进行训练之前,首先在ImageNet上按照常见的范式对双分辨率网络进行训练。
根据在两个流行基准上的大量实验结果,DDRNet在分割精度和推理速度之间取得了很好的平衡,并且在训练过程中比HRNet占用更少的GPU内存。与其他实时算法相比,作者的方法在城市景观和CamVid上实现了新的最先进的mIoU,没有注意机制和任何额外的铃声或口哨。使用标准的测试增强技术,DDRNet可以与最先进的模型相媲美,但需要的计算资源要少得多。
其主要贡献总结如下:
提出了一种新的深度双分辨率双边网络用于实时语义分割。作者的网络获得新的最先进的性能考虑推理速度没有任何额外的铃声或哨子。
设计了一个新的模块,通过将特征聚合与金字塔池相结合来获取丰富的上下文信息。当它与低分辨率的特征映射集成时,推理时间几乎没有增加。
通过简单的增加网络的宽度和深度,DDRNet在现有的方法中实现了mIoU和FPS之间的最大权衡,在cityscape测试集上,从77.4%的mIoU在109 FPS到80.4%的mIoU在23 FPS。
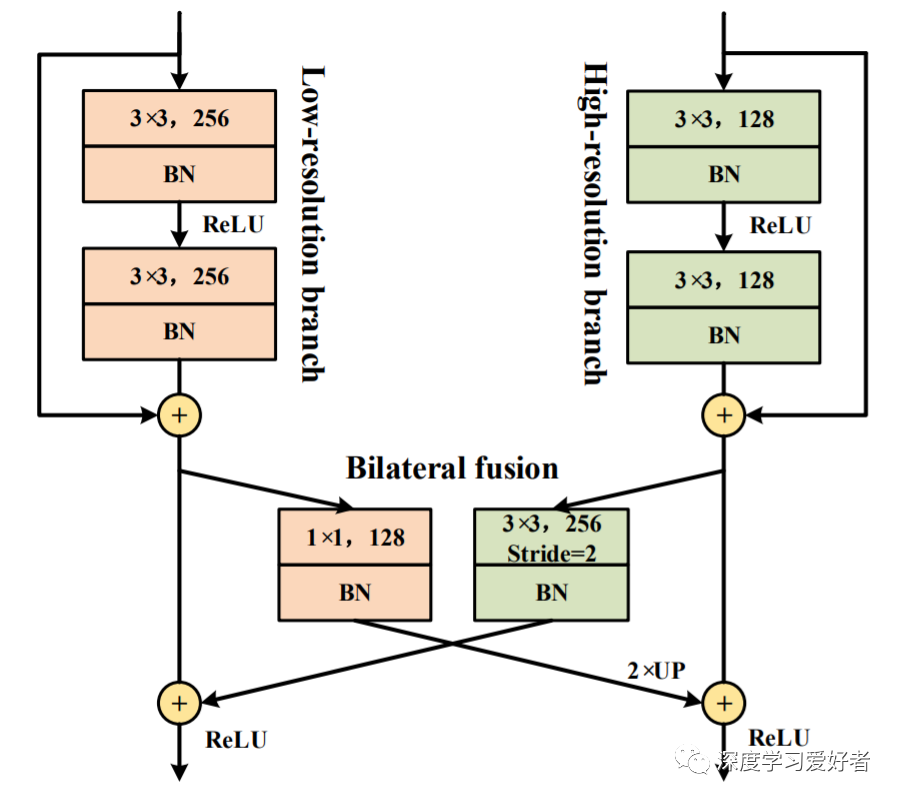
双侧融合细节在DDRNet中。在ReLU之前实现了求和融合。
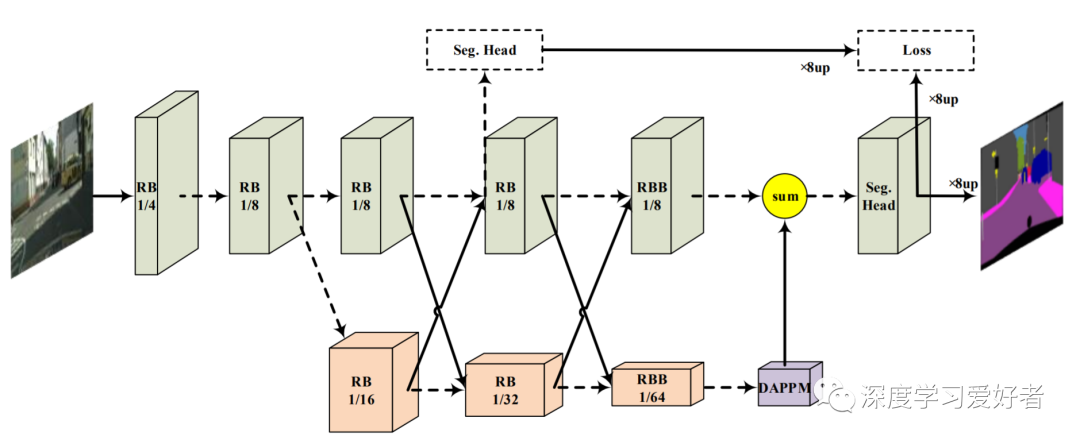
语义分割的DDRNets综述。RB表示顺序剩余基本块。RBB表示单个剩余瓶颈块。DAPPM表示深度聚合金字塔池化模块。赛格。Head表示分割头。黑色实线表示有数据处理的信息路径(包括上采样和下采样),黑色虚线表示没有数据处理的信息路径。sum表示逐点连接。虚线框表示在推理阶段被忽略的组件。

cityscape val set上的可视化分割结果。从左到右的四列分别为输入图像、ground truth、DDRNet-23-slim的输出、DDRNet-23的输出。前四行显示了两种模型的性能,后两行表示了一些分割失败。
本文提出了一种新的用于道路场景实时语义分割的深度双分辨率体系结构,并提出了一种新的多尺度上下文信息提取模块。据作者所知,作者是第一个将深度高分辨率表示引入实时语义分割的公司,作者的简单策略在两种流行基准上优于所有以前的模型,而不需要任何额外的附加功能。现有的实时网络大多是为ImageNet精心设计的或专门为ImageNet设计的高级骨干,这与广泛用于高精度方法的扩张骨干有很大不同。相比之下,DDRNet只利用了基本的残余模块和瓶颈模块,通过缩放模型的宽度和深度,可以提供更大范围的速度和精度权衡。由于作者的方法简单和高效,它可以被视为统一实时和高精度的语义分割的强大基线。
论文链接:https://arxiv.org/pdf/2101.06085.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~