
CVChain:搞通完整CV任务的计算机视觉工具链 | 训练有素、有备而来
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
本文作者团队在做项目和打比赛的过程中,总结出了一条计算机视觉工具链:CVChain,它纵向上涵盖了一个CV任务的完整生命周期,横向上则包含了3个CV基本任务,即分类、语义分割和目标检测。
我们这一年来做的一些工作(总结见文章最下方)现在差不多形成了一个较完善的计算机视觉工具链——CVChain。我们这一年来做的一些工作(总结见文章最下方)现在差不多形成了一个较完善的计算机视觉工具链——CVChain。
纵向上它涵盖了一个计算机视觉任务的生命周期:数据分析与模型选型、模型训练、发现模型存在的问题并优化、模型加速、模型SDK编写;横向上它包含了计算机视觉中三个基本任务:分类、语义分割、目标检测;与此同时它还总结了计算机视觉入门到进阶的学习框架。一言以蔽之:有了CVChain,妈妈再也不用担心我搞不定计算机视觉!
CVChain是我们平常做项目或者打比赛过程中打磨出来的,它们可以满足计算机视觉算法工程师日常大部分需求,比如:
1. 刚踏入计算机视觉领域,不知道从何学起,需要一张学习的地图:
https://github.com/mileistone/study_resources/blob/master/modeling/learning_framework/learning_framework_general.md
带着自己一步一步领略计算机视觉的风采;
2. 已经成为一名合格的计算机视觉算法工程师,开始接任务。当任务来了,需要分析数据分析数据以进行模型选型、模型超参的初步设定;
https://github.com/Media-Smart/volkscv/tree/master/volkscv/analyzer/statistics
3. 模型确定后,得训练模型(可能涉及到分类、语义分割、文字识别、目标检测等等),这个时候需要一个趁手的训练工具;
分类:
https://github.com/Media-Smart/vedacls语义分割
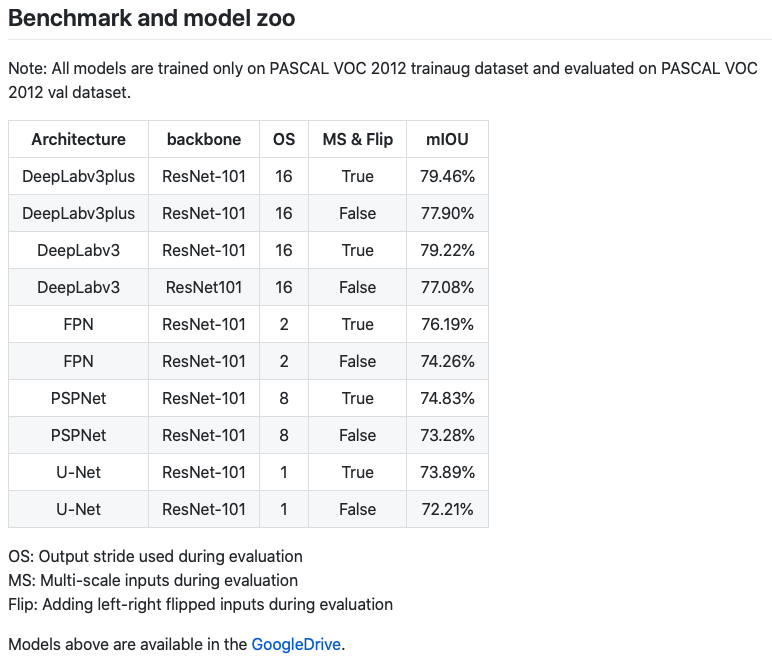
https://github.com/Media-Smart/vedaseg
文字识别
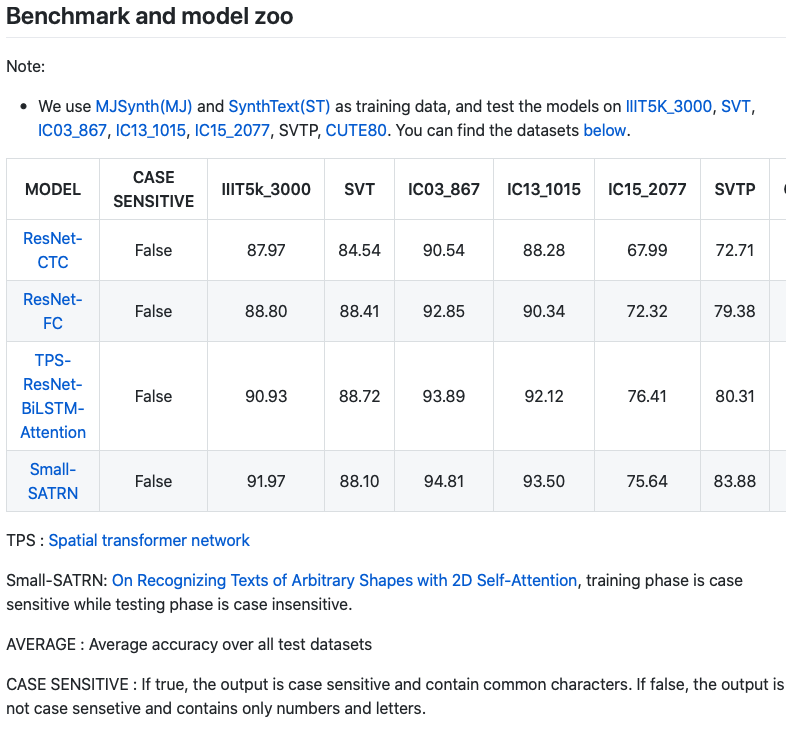
https://github.com/Media-Smart/vedastr
目标检测
https://github.com/Media-Smart/vedadet
4. 模型训练完之后,效果不够好,我们需要把FP、FN打印出来,分析模型存在的问题;
https://github.com/Media-Smart/volkscv/tree/master/volkscv/analyzer/visualization
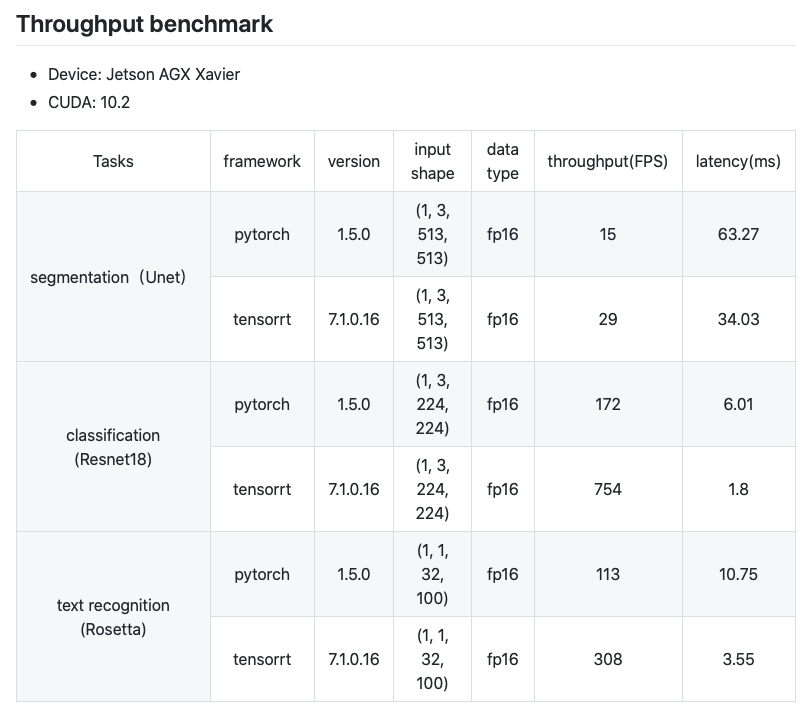
5. 模型训练好之后,需要将模型转换为应用并进行部署,这里需要用TensorRT对模型进行加速,然后根据业务需求编写Python前端或者C++前端的SDK;
加速
https://github.com/Media-Smart/volksdepPython前端
https://github.com/Media-Smart/flexinfer
C++前端
https://github.com/Media-Smart/cheetahinfer
6. 计算机行业竞争激烈,平常得抽空加强学习,无论是工程、模型还是算法方面,都需要持续不断学习,把自己训练为一名六边形战士。
工程
https://github.com/mileistone/study_resources/tree/master/engineering

模型
https://github.com/mileistone/study_resources/tree/master/modeling
算法
https://github.com/mileistone/study_resources/tree/master/modeling/optimization_and_generalization
上述的“2、数据分析”提供以下功能。
1、浏览图片和标注
比如分类、目标检测、语义分割等等,这可以帮助我们对数据有一个感性的认识,可以定性出来这个任务有哪些挑战。
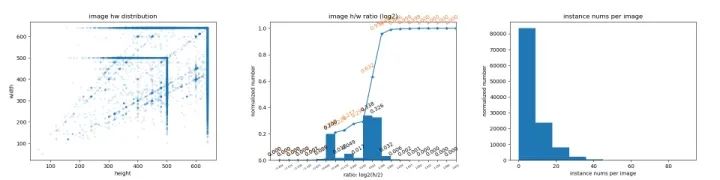
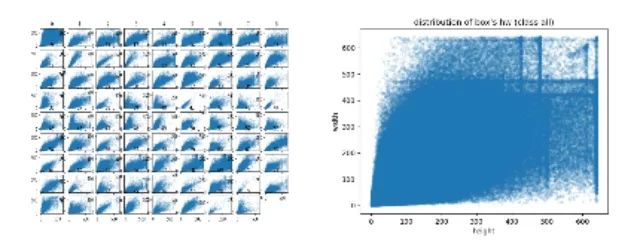
2、图片和标注分析
比如图片大小分布,图片长宽比分布,图片中GT框数量分布,GT框长宽分布等等,这可以让我们对数据有一些理性的认识,让我们可以定量这个任务存在的挑战。
3、打印模型预测结果中的FP、FN
比如分类。

比如目标检测。

比如语义分割。
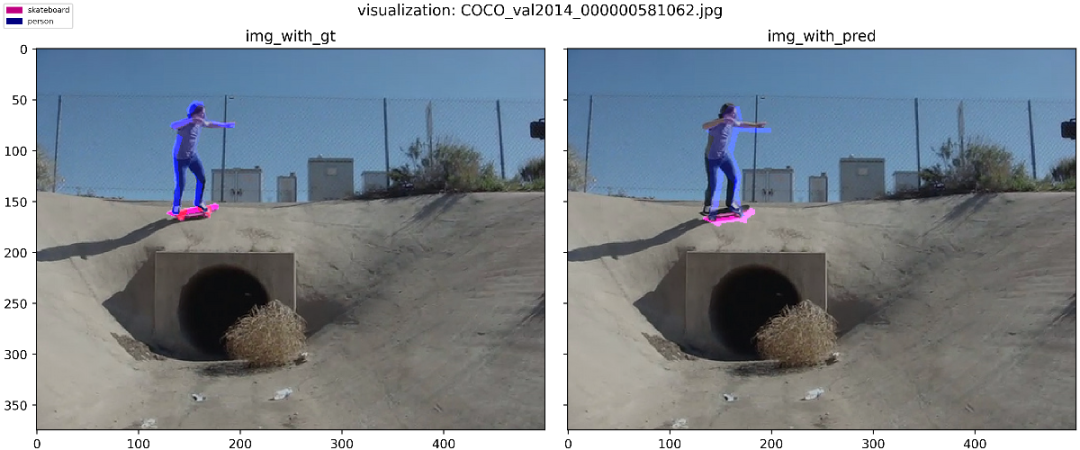
打印FP、FN可以让我们发现模型存在的问题,进而有助于我们分析问题、定位问题直至解决问题。
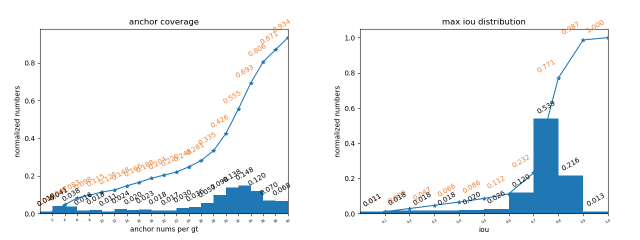
4、anchor分析
比如GT匹配上的anchor数量分布,GT与匹配上anchor的IoU分布等等。这有助于我们设计出更好的anchor策略,比如anchor应该放在哪几层,每一层anchor数量应该设置多少,对应的大小和长宽比是多少,以及label assignment该怎么做等等。
汇总
https://github.com/Media-Smart/vedaseg https://github.com/Media-Smart/vedastr https://github.com/Media-Smart/vedacls https://github.com/Media-Smart/vedadet Media-Smart/volksdep,https://github.com/Media-Smart/volksdep Media-Smart/flexinfer,https://github.com/Media-Smart/flexinfer https://github.com/Media-Smart/cheetahinfer https://github.com/Media-Smart/volkscv https://github.com/mileistone/study_resources
- 数据分析- [volkscv](https://github.com/Media-Smart/volkscv/tree/master/volkscv/analyzer/)- 数据浏览 -> 获取感性认识- 图片、标注- 数据统计 -> 获取理性认识- 图片统计- 大小- 长宽比- 等等- 标注统计- 类别- 各个类别有多少实例- 等等- GT框- 大小- 长宽比- 等等- anchor分析- GT挂上anchor的数量分布- GT与挂上anchor的IoU分布- 模型训练- [vedaseg](https://github.com/Media-Smart/vedaseg)- semantic segmentation- [vedastr](https://github.com/Media-Smart/vedastr)- scene text recognition- [vedacls](https://github.com/Media-Smart/vedacls)- classification- [vedadet](https://github.com/Media-Smart/vedadet)- object detection- 应用部署- [volksdep](https://github.com/Media-Smart/volksdep)- increase efficiency and decrease latency- convert PyTorch,ONNX model to TensorRT engine- [flexinfer](https://github.com/Media-Smart/flexinfer) -> Python front end SDK based on TensorRT engine- classification- semantic segmentation- scene text recognition- object detection- [cheetahinfer](https://github.com/Media-Smart/cheetahinfer) -> C++ front end SDK based on TensorRT engine- classification- semantic segmentation- object detection- 学习资源- [学习框架](https://github.com/mileistone/study_resources/tree/master/modeling/learning_framework)- 知识点- 相关课程与书籍- 基础- [工程](https://github.com/mileistone/study_resources/tree/master/engineering)- 编程语言- Python- C++- 软件工程- 设计模式- 操作系统- Linux- Bash- Vim- 编译工具链- [模型](https://github.com/mileistone/study_resources/tree/master/modeling)- 内容- 机器学习- 深度学习- 计算机视觉- 形式- 课程- 书籍- 论文- [算法](https://github.com/mileistone/study_resources/tree/master/modeling/optimization_and_generalization)- 凸优化- 数值优化
下载1:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载2 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得不错就点亮在看吧
