
【学术前沿】基于贝叶斯网络的机器学习在桩基设计中的应用
点击上方“公众号”可订阅哦!
声明:本文只是针对个人学习记录,侵权可删。本人自觉遵守《中华人民共和国著作权法》和《伯尔尼公约》等法律,其他个人或组织等转载请保留此声明,并自负法律责任。论文版权与著作权等全归原作者所有。

01
文章摘要
02
文章导读
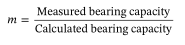
and Phoon[10]和Phoon and
Tang对世界上现有的桩荷载试验数据进行了全面的调查,也发现了类似的现象。在实际应用中,通常基于区域负荷试验数据库估计m的统计量,而不单独考虑站点间和站点间的变量。当使用这种方法时,与m相关的估计不确定度同时包含场地内可变性和跨场地可变性,这可能会使设计不具成本效益。
03
方法
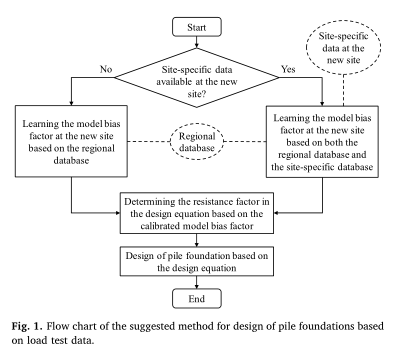
04
贝叶斯网络学习无负载测试数据的新站点
贝叶斯网络的结构
根节点的先验分布
贝叶斯网络学习与负载测试数据的新网站
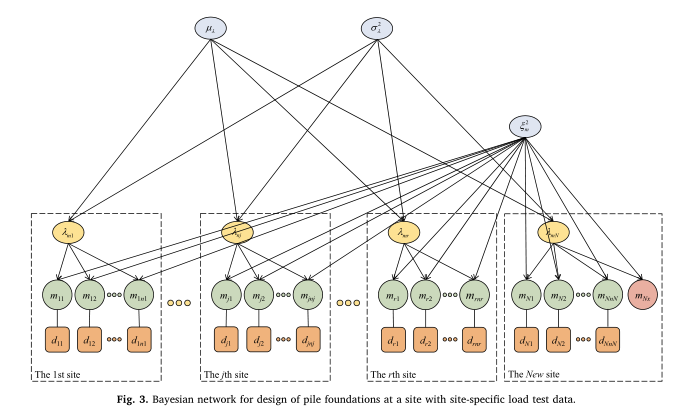
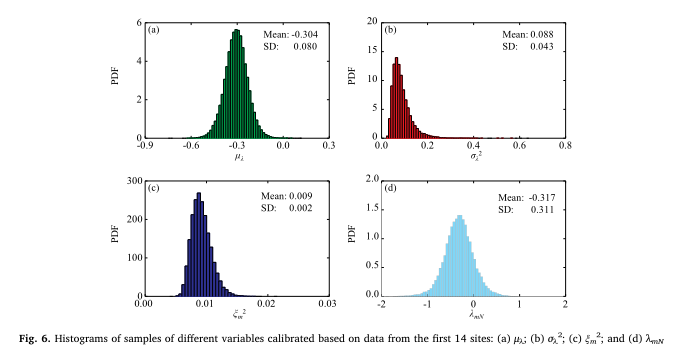
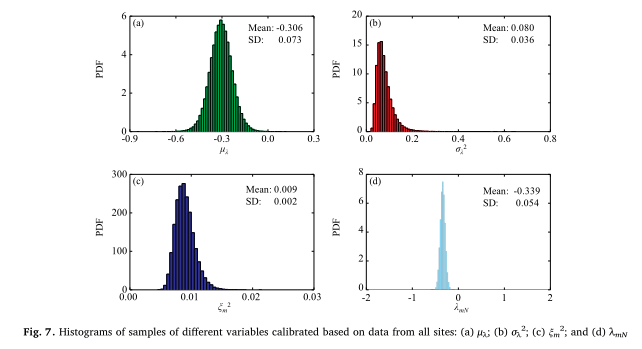
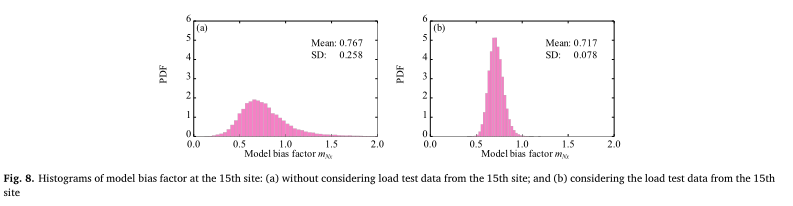
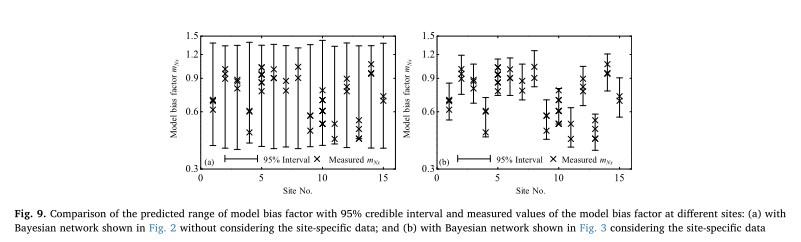
ξm2的分布绘制出mnxn的样本,并在区域数据库中学习。从本研究的举例说明中可以看出,单纯基于区域数据库进行桩基设计是可行的,但涉及的不确定性是很大的,设计可能不具有成本效益。另一方面,当特定站点负载测试数据是可用的,样品的mNxcan从图3所示的贝叶斯网络,通过相关的不确定性模型可以减少偏见的因素考虑到特定站点负载测试数据,和桩在这种情况下可以设计在一个更具成本效益的方式。
05
对建议方法的验证
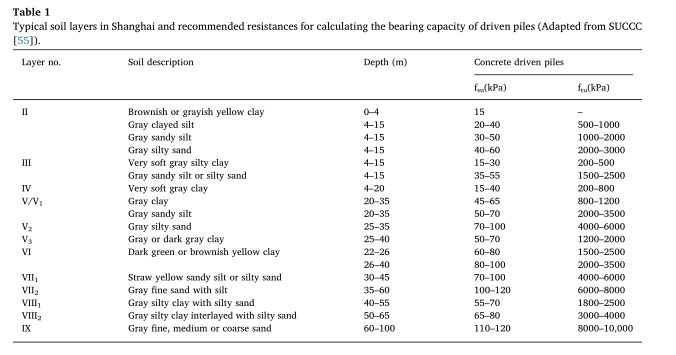
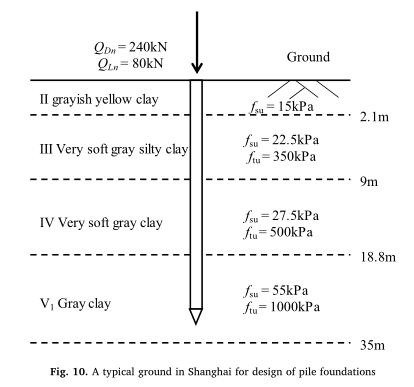
为了验证建议的机器学习方法的适用性,我们收集了中国上海的一个数据库。上海位于中国长江三角洲冲积平原。上海底土较为均匀,主要由粘土、粉砂、砂土等沉积物组成。上海市典型土层如表1所示。基岩的深度可达300-400米。
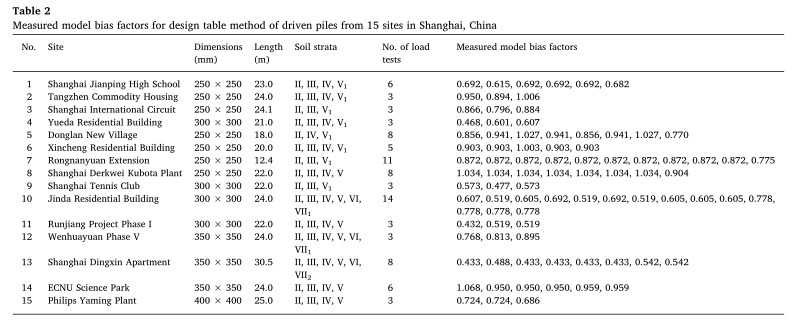
在对模型偏差系数进行校正时,校正数据库中的桩必须是同一类型、位于相似的土体剖面上,并采用相同的判据对桩的承载力进行解释。在模型偏差因子校正后,从校正数据库中所学到的知识也应应用到类似土壤剖面中同类型桩的设计中。在上海,混凝土方封闭端打入桩应用广泛。表2显示了基于15个场地87桩静载试验数据的设计表法模型偏差系数测量区域数据库。这些桩的空间分布如图4所示。由表2可以看出,这些桩的长度都在20-30
m范围内。由于上海地区地层较为均匀,这些桩所处的土体剖面相似。端部承载土层为第V层或第VII层,是打入桩可到达的较浅深度的强土层。所有桩均为摩阻桩兼端承桩。在上海,承载力定义为桩长不为>
40 m时,沉降达到40mm时的荷载。标定库中的桩承载力是根据上述准则确定的。

06
结论

END

深度学习入门笔记
微信号:sdxx_rmbj
日常更新学习笔记、论文简述
评论