
贝叶斯机器学习路线图
本文转自图灵人工智能
贝叶斯统计是统计的一个分支,它的特点是把我们感兴趣的量(比如统计模型的参数)看作随机变量. 给定观察数据后, 我们对这些量的后验分布进行分析从而得出结论. 虽然贝叶斯统计的核心思想已经历经很多年了, 但贝叶斯的思想在过去近20年对机器学习产生了重大影响, 因为它在对真实世界现象建立结构化模型时提供了灵活性. 算法的进步和日益增长的计算资源使得我们可以拟合丰富的, 高度结构化的模型, 而这些模型在过去是很棘手的.
这个路线图旨在给出贝叶斯机器学习中许多关键思想的指引. 如果您正考虑在某些问题中使用贝叶斯方法, 您需要学习"核心主题"中的所有内容. 即使您只是希望使用诸如 BUGS, Infer.NET, 或 Stan等软件包, 这些背景知识也对您很有帮助. 如果这些软件包不能马上解决您的问题, 知道模型的大致思想可帮助您找出问题所在.
如果您正考虑研究贝叶斯机器学习, 那么许多论文会假设您已经掌握了核心主题的内容以及部分进阶主题的内容, 而不再给出参考文献. 阅读本路线图时, 我们不需要按顺序学习, 希望本文可以在您需要时为您提供帮助.
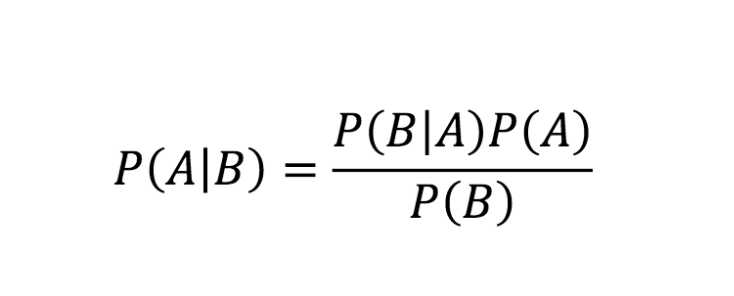
本文目录结构如下:
核心主题
贝叶斯信息准则(Bayesian information criterion)
拉普拉斯近似(Laplace approximation)
混合高斯
因子分析
隐马尔科夫模型(HMM)
MAP估计
Gibbs采样
马尔科夫链蒙特卡洛(MCMC)
变分推断(Variational inference)
最大似然
正则化
EM算法
参数估计
模型比较
中心问题
非贝叶斯方法
基本推断算法
模型
贝叶斯模型比较
进阶主题
无信息先验(uninformative priors)
最大似然的渐进(asymptotics of maximum likelihood)
Jeffreys prior
树结构图模型
非树结构图模型
Sum-product algorithm
Max-product algorithm
循环信念传播(Loopy belief propagation)
连接树算法(Junction tree algorithm)
变分贝叶斯(Variational Bayes)
平均场近似(Mean field approximation)
期望传播(expectation propagation)
折叠Gibbs采样(Collapsed Gibbs sampling)
哈密尔顿蒙特卡洛(Hamiltonian Monte Carlo)(HMC)
切片采样(Slice sampling)
可逆跳跃MCMC(reversible jump MCMC)
Sequential Monte Carlo(SMC)
粒子滤波器(Particle filter)
退火重要性采样(Annealed importance sampling)
高斯过程(Gaussian processes)
Chinese restaurant process(CRP)
Hierarchical Dirichlet process
Indian buffet process(IBP)
Dirichlet diffusion trees
Pitman-Yor process
逻辑回归(Logistic regression)
贝叶斯网络(Bayesian networks)
Latent Dirichlet allocation(LDA)
线性动态系统(Linear dynamical systems)
稀疏编码(Sparse coding)
模型
贝叶斯非参数
采样算法
变分推断
信念传播(Belief propagation)
核心主题
这一章覆盖了贝叶斯机器学习的核心概念. 如果您希望使用这些工具, 建议您学习本章的所有内容.
中心问题
什么是贝叶斯机器学习? 一般来说, 贝叶斯方法旨在解决下面给出的某一个问题:
参数估计(parameter estimation)
假设您已经建好了一个统计模型, 并且希望用它来做预测. 抑或您认为模型中的参数很有意义, 所以希望拟合这些参数来学习到某些东西. 贝叶斯方法是在给定观察数据后, 去计算或者近似这些参数的后验分布.
您通常会希望使用训练好的模型来作出一些决策行为. 贝叶斯决策理论(Bayesian decision theory)提供了选择行为的一个框架.
模型比较(model comparison)
您可能有许多个不同的候选模型, 那么哪一个是最贴切给定数据的呢? 一种常见的情形是: 您有一些形式相同但复杂度不同的模型, 并且希望在复杂度和拟合度间权衡.
与选择单个模型相比, 您可以先为模型定义先验, 并且根据模型的后验对预测进行平均. 这便是贝叶斯模型平均(bayesian model averaging).
此外, 贝叶斯网络(Bayesian networks) (Bayes nets)的基础知识也值得一学, 因为这些符号在讨论贝叶斯模型时会经常用到. 由于贝叶斯方法把模型参数也看作随机变量, 所以我们可以把贝叶斯推断问题本身表达为贝叶斯网络.
阅读本章内容会告诉您贝叶斯方法解决什么问题, 但是没告诉您一般情况下, 如何真正地解决这些问题. 这是本路线图剩余部分将讨论的内容.
非贝叶斯方法(Non-Bayesian techniques)
作为背景知识, 了解如何使用非贝叶斯方法拟合生成模型是有助于理解的. 这么做的其中一个理由是: 这些方法更易于理解, 并且一般来说结果已经足够好了. 此外, 贝叶斯方法跟这些方法存在一些相似性, 学习这些方法后, 通过类比可以帮助我们学习贝叶斯方法.
最基础的, 您需要明白 泛化(generalization)的符号, 或者知道一个机器学习算法在未知数据上表现如何. 这是衡量机器学习算法的基础. 您需要理解以下方法:
最大似然(maximum likelihood)
拟合模型参数的准则.正则化(regularization)
防止过拟合的方法.EM算法(the EM algorithm)
为每个数据点都有与之相关联的潜在变量(未观测变量)的生成模型拟合参数.
基本推断算法
一般来说, 贝叶斯推断需要回答的问题是: 给定观察数据后, 推断关于模型参数(或潜在变量(latent variables))的后验分布. 对于一些简单模型, 这些问题拥有解析解. 然而, 大多数时候, 我们得不到解析解, 所以需要计算近似解.
如果您需要实现自己的贝叶斯推断算法, 以下可能是最简单的选择:
MAP估计(MAP estimation)
使用最优参数的点估计来近似后验. 这把积分问题替换为了优化问题. 但这并不代表问题就很简单了, 因为优化问题本身也常常很棘手. 然而, 这通常会简化问题, 因为优化软件包比采样软件包更普适(general)也更鲁棒(robust).吉布斯采样(Gibbs sampling)
吉布斯采样是一种迭代的采样过程, 每一个随机变量都从给定其他随机变量的条件分布中采样得到. 采样的结果很有希望是后验分布中的一个近似样本.
您还应该知道下列常用的方法. 他们的一般公式大多数时候都过于宽泛而难以使用, 但是在很多特殊情形下, 他们还是很强大的
马尔科夫链蒙特卡洛(Markov chain Monte Carlo)
一类基于采样的算法, 这些算法基于参数的马尔科夫链, 该马尔科夫链的稳态分布是后验分布.
1.特别的, Metropolis-Hastings (M-H)算法是一类实用的构建有效MCMC链的方法. 吉布斯采样也是M-H算法的特例.变分推断(Variational inference)
尝试用易于处理的分布去近似难以处理的分布. 一般来说, 易处理分布的参数通过最小化某种度量指标来选择, 这个度量指标衡量了近似分布和真实分布之间的距离.
模型
以下是一些简单的生成模型, 这些模型常常运用贝叶斯方法.
混合高斯(mixture of Gaussians)
混合高斯模型中, 每个数据点属于若干簇或者群组中的其中一个, 每个簇中的数据点都服从高斯分布. 拟合这样一个模型可以让我们推断出数据中有意义的分组情况.因子分析(factor analysis)
因子分析中, 每个数据点被更低维度的线性函数近似表达. 我们的想法是, 潜在空间(latent space)中每个维度对应一个有意义的因子, 或者数据中变化的维度.隐马尔科夫模型(hidden Markov models)
隐马尔科夫模型适用于时间序列数据, 其中有一个潜在的离散状态随着时间的推移而演变.
虽然贝叶斯方法大多数时候与生成模型相联系, 但它也可以被用于判别模型的情况. 这种情形下, 我们尝试对已知观测数据时目标变量的条件分布直接进行建模. 标准的例子是贝叶斯线性回归(Bayesian linear regression).
贝叶斯模型比较
推断算法的小节为我们提供了近似后验推断的工具. 那么比较模型的工具是什么呢? 不幸的是, 大多数模型比较算法相当复杂, 在您熟悉下面描述的高级推理算法前, 您可能不想自己实现它们. 然而, 有两个相当粗略的近似模型比较是较为容易实现的.
贝叶斯信息准则(Bayesian information criterion )(BIC)
贝叶斯信息准则简单地使用MAP解并添加一个罚项, 该罚项的大小正比于参数的数量.拉普拉斯近似(Laplace approximation)
使用均值与真实后验分布MAP相同的高斯分布对后验分布进行近似.
进阶主题
本章将讨论贝叶斯机器学习中更进阶的主题. 您可以以任何顺序学习以下内容
模型
在"核心主题"一章中, 我们列出了一些常用的生成模型. 但是大多数的数据集并不符合那样的结构. 贝叶斯建模的强大之处在于其在处理不同类型的数据时提供了灵活性. 以下列出更多的模型, 模型列出的顺序没有特殊意义.
逻辑回归(logistic regression)
逻辑回归是一个判别模型, 给定输入特征后, 对二元目标变量进行预测.贝叶斯网络(Bayesian networks) (Bayes nets).
概括地说, 贝叶斯网络是表示不同随机变量间概率依赖关系的有向图, 它经常被用于描述不同变量间的因果关系. 尽管贝叶斯网络可以通过非贝叶斯方法学习, 但贝叶斯方法可被用于学习网络的 参数(parameters) 和 结构(structure)(网络中的边)
线性高斯模型(Linear-Gaussian models)是网络中的变量都服从联合高斯的重要特殊情况. 即使在具有相同结构的离散网络难以处理的情况下, 这些网络的推论都常易于处理.
latent Dirichlet allocation(LDA)
LDA模型是一个"主题模型", 其假定一组文档(例如网页)由一些主题组成, 比如计算机或运动. 相关模型包括非负矩阵分解(nonnegative matrix factorization)和 概率潜在语义分析(probabilistic latent semantic analysis)线性动态系统(linear dynamical systems)
一个时间序列模型. 其中, 低维高斯潜在状态随时间演变, 并且观察结果是潜在状态的噪声线性函数. 这可以被认为是HMM的连续版本. 可以使用卡尔曼滤波器(Kalman filter)和平滑器(smoother)来精确地执行该模型中的判断.稀疏编码(sparse coding)
稀疏编码中每一个数据点被建模为从较大的字典中抽取的少量元素的线性组合. 当该模型被应用于自然图像像素时, 学习的字典类似于主视觉皮层中的神经元的接受字段. 此外, 另一个密切相关的模型称为独立成分分析(independent component analysis).
贝叶斯非参数
上述所有模型都是参数化的, 因为它们是以固定的有限数量的参数表示的. 这是有问题的, 因为这意味着我们需要预先指定一些参数(比如聚类中的簇的数目), 而这些参数往往是我们事先不知道的.
这个问题可能对上述模型看起来并无大碍, 因为对于诸如聚类的简单模型, 我们通常可以使用交叉验证来选择好的参数. 然而, 许多广泛应用的模型是更为复杂的, 其中涉及许多独立的聚类问题, 簇的数量可能是少数几个, 也可能是数千个.
贝叶斯非参数是机器学习和统计学中不断研究的领域, 通过定义无限复杂的模型来解决这个问题. 当然, 我们不能明确地表示无限的对象. 但是关键的观点是, 对于有限数据集, 我们仍然可以在模型中执行后验推断, 而仅仅明确地表示它们的有限部分.
下面给出一些重要的组成贝叶斯非参数模型的构建模块:
高斯过程(Gaussian processes)
高斯过程是函数上的先验, 使得在任何有限集合点处采样的值是服从联合高斯的. 在许多情况下, 为在函数上赋予先验, 您需要假设后验推理是易于处理的.Chinese restaurant process(CRP)
CRP是无限对象集合的划分的先验
这常被用于聚类模型, 使得簇的数目无需事先指定. 推理算法相当简单且易于理解, 所以没有理由不使用CRP模型代替有限聚类模型.
这个过程可以等价于Dirichlet process.
Hierarchical Dirichlet process
包含一组共享相同base measure的Dirichlet process, baase measure本身也是从Dirichlet process中选取的.Indian buffet process(IBP)
IBP无限二进制矩阵的先验, 使得矩阵的每一行仅具有有限个1. 这是在每个对象可以拥有多个不同属性时最常用的模型. 其中, 矩阵的行对应于对象, 列对应于属性, 如果对象具有某属性, 对应列的元素为1.
最简单的例子可能是IBP linear-Gaussian model. 其中, 观察到的数据是属性的线性函数.
还可以根据beta process来看IBP过程. 本质上, beta process之于IBP正如Dirichlet process之于CRP.
Dirichlet diffusion trees
一个分层聚类模型. 其中, 数据点以不同的粒度级别聚类. 即可能存在一些粗粒度的簇, 但是这些簇又可以分解成更细粒度的簇.Pitman-Yor process
类似于CRP, 但是在聚类大小上有更重尾的分布(比如幂律分布). 这说明您希望找到一些非常庞大的簇, 以及大量的小簇. 比起CRP选择0的指数分布, 幂律分布对于许多真实数据有更好的拟合效果.
采样算法
从"核心主题"章节, 您已经学习了两个采样算法:Gibbs采样和Metropolis-Hastings(M-H)算法. Gibbs采样涵盖了很多简单的情况, 但在很多模型中, 您甚至不能计算更新. 即使对于适用的模型, 如果不同的变量紧密耦合(tightly coupled), 采样过程也会mix得非常缓慢. M-H算法是更一般的, 但是M-H算法的一般公式中没有提供关于如何选择提议分布(proposals)的指导, 并且为实现良好的mix, 通常需要非常仔细地选择提议分布.
下面是一些更先进的MCMC算法, 这些算法在特定情形中表现更为良好:
collapsed Gibbs sampling
变量的一部分在理论上被边缘化(marginalized)或折叠(collapsed)掉, 并在剩下的变量上进行Gibbs采样. 例如, 当拟合CRP聚类模型时, 我们通常将聚类参数边缘化掉, 并对聚类分配执行Gibbs采样. 这可以显著地改善mix, 因为聚类分配和簇参数是紧密耦合的.Hamiltonian Monte Carlo (HMC)
连续空间中M-H算法的实例, 其使用对数概率的梯度来选择更好的探索方向. 这是驱动 Stan的算法.slice sampling
一种从一维分布中采样的辅助变量方法. 其关键卖点是算法不需要指定任何参数. 因此, 它经常与其他算法(例如HMC)结合, 否则将需要指定步长参数.reversible jump MCMC
在不同维度的空间之间构造M-H提议分布的方式. 最常见的用例是贝叶斯模型平均
虽然在实践中使用的大多数采样算法是MCMC算法, 但Sequential Monte Carlo(SMC)算法值得一提. 这是从一系列相关分布中近似采样的另一类技术.
最常见的例子可能是粒子滤波器(particle filter), 通常应用于时间序列模型的推理算法. 它每次一步地考虑观察数据, 并且在每个步骤中, 用一组粒子表示潜在状态的后验
退火重要性采样(Annealed importance sampling) (AIS)是另一种SMC方法, 其通过一系列中间分布从简单的初始分布(比如先验)到难处理的目标分布(例如后验)逐渐"退火" 针对每个中间分布执行MCMC转换. 由于在初始分布附近mixing通常更快, 这应该有助于采样器避免困在局部模式中.
算法计算一组权重, 这些权重亦可被用于 估计边际似然(estimate the marginal likelihood). 当使用了足够多的中间分布时, 权重的方差会很小, 因此产生了一个精确的边际似然估计.
变分推断(Variational inference)
变分推断是基于优化而不是采样的另一类近似推断方法. 其基本想法是用一个易处理的近似分布来逼近难处理的后验分布. 选择近似分布的参数以使近似分布和后验分布之间的距离的某些度量(通常使用KL散度)最小化.
我们很难对变分推断和采样方法之间的折中作出任何一般性的陈述, 因为这些都是一个广泛的类别, 其中包括了许多特殊的算法, 既有简单的又有复杂的. 然而, 有一些一般的经验规则:
变分推断算法具有与采样方法不同的实现困难
变分推断算法更难, 因为它们需要冗长的数学推导来确定更新规则.
然而, 一旦实现, 变分贝叶斯方法可以更容易地被检验, 因为可以对优化代码采用标准检查(梯度检查, 局部最优测试等).
此外, 大多数变分推断算法收敛到(局部)最优解, 这消除了检查收敛诊断的需要.
大多数变分推理分布的输出是一个分布, 而不是样本.
为了回答许多问题, 例如模型参数的期望或者方差, 可以简单地检查变分分布. 相比之下, 采样方法通常需要收集大量采样样本, 这可能需要很大的开销.
然而, 使用变分法, 近似的精度受到近似分布族的表达能力的限制, 并且近似分布与后验分布有多大不同并不总是那么明显. 相反, 如果您运行一个采样算法足够长时间, 最终您会得到较为准确的结果.
这里给出一些变分推断算法的重要例子:
变分贝叶斯(variational Bayes)
贝叶斯模型的变分推断应用, 其中参数的后验分布不能精确地表示, 如果模型还包括潜在变量, 则可以使用变分贝叶斯EM算法(variational Bayes EM)平均场近似(mean field approximation)
近似分布具有特别简单的形式:假定所有变量是独立的.
平均场也可以根据 凸对偶性(convex duality)来观察, 这将导出与普通解释不同的拓展
期望传播(expectation propagation)
对循环置信传播(loopy belief propagation)的一种近似. 它发送近似消息, 这些消息仅代表相关变量的充分统计量的期望.
下面给出一些使用变分推断方法的经典例子. 尽管你可能不会直接使用这些模型, 但是它们给出了变分技巧如何更一般地用于贝叶斯模型的指引:
线性回归(linear regression)
逻辑回归(logistic regression)
混合高斯(mixture of Gaussians)
指数族模型(exponential family models)
信念传播(Belief propagation)
信念传播是用于如贝叶斯网络(Bayes nets) 和马尔科夫场(Markov random fields) (MRFs)等图模型的另一类推断算法. 模型中的变量相互"传递消息", 它们总结了关于其他变量的联合分布的信息. 信念传播有两种一般形式:
当应用于树结构图模型时, BP执行精确的后验推断. 有两种特殊的形式:
the sum-product algorithm
计算每个单独变量(以及每一对相邻变量)的边际分布.the max-product algorithm
计算所有变量的最可能的联合分配
还可以在不是树结构的图中应用相同的消息传递规则. 这没有给出确切的结果, 事实上甚至缺少基本的保证, 例如收敛到固定点, 但通常它在实践中能很有效. 这通常被称为循环信念传播(loopy belief propagation), 以区别于树结构的版本, 但令人困惑的是, 一些研究人员简单地将其称为"信念传播"。
连接树算法(junction tree algorithm)给出了通过定义粗糙的"超变量(super-variables)"来对非树结构图应用精确的BP的方法. 定义"超变量"后的图是树结构的.
树上的BP最常见的特殊情况是HMMs的前向-后向算法(forward-backward algorithm) .卡尔曼平滑(Kalman smoothing)也是前向-后向算法的一种特例, 因此也是一种BP.
BP在计算机视觉和信息论中被广泛使用, 在这两个领域中, 推断问题往往具有规则的结构. 在贝叶斯机器学习中, BP不常被单独使用, 但是它可以是基于变分或采样的算法中的强大组成部分.
理论
最后, 给出贝叶斯方法中的一些理论问题.定义贝叶斯模型需要指定先验. 如果对于参数没有较大的先验信念, 我们可能希望选择 无信息先验(uninformative priors). 一个常见的选择是Jeffreys prior.准确地估计模型中的参数需要多少数据?最大似然的渐进(asymptotics of maximum likelihood) 提供了对于这个问题的许多洞见, 因为对于有限模型, 后验分布具有与最大似然估计的分布相似的渐进行为。
往期精彩: