
机器学习在组合优化中的应用(上)
运筹学自二战诞生以来,现已被广泛应用于工业生产领域了,比如交通运输、供应链、能源、经济以及生产调度等。离散优化问题(discrete optimization problems)是运筹学中非常重要的一部分,他们通常可以建模成整数优化模型进行求解,即通过决定一系列受约束的整数或者0-1变量,得出模型最优解。
有一些组合优化问题不是那么的“难”,比如最短路问题,可以在多项式的时间内进行求解。然而,对于一些NP-hard问题,就无法在多项式时间内求解了。简而言之,这类问题非常复杂,实际上现在的组合优化算法最多只能求解几百万个变量和约束的问题而已。
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。现在,有很多研究想将学习的方法应用与组合优化领域,提高传统优化算法的效率。
By the way,大家请原谅我,有些单词我真不知道咋翻译,就直接用英文了,所以你们阅读的时候看见中英混用,绝不是我在装13,而是有些情景用英文大家理解起来会更方便。
1 动机
在组合优化算法中使用机器学习的方法,主要有两方面:
(1)优化算法中某些模块计算非常消耗时间和资源,可以利用机器学习得出一个近似的值,从而加快算法的速度。
(2)现存的一些优化方法效果并不是那么显著,希望通过学习的方法学习搜索最优策略过程中的一些经验,提高当前算法的效果。(算是一种新思路?)
2 介绍
这一节简要介绍下关于组合优化和机器学习的一些概念,当然,只是粗略的看一下,详细内容大家还是去参照以往公众号的文章(指的组合优化方面)。因为之前做的一直是运筹优化领域,对机器学习一知半解,所以关于这部分的阐述则是从网上筛选过来的,出处我均已贴到参考那里了。
2.1 组合优化
组合优化相信大家都很熟悉了,因为公众号一直在做的就是这方面的内容。一个组合优化问题呢通常都能被建模成一个带约束的最小化问题进行求解,即将问题以数学表达式的形式给出,通过约束变量的范围,让变量在可行域内作出决策,使得目标值最小的过程。
如果决策变量是线性的,那么该问题可以称为线性规划(Linear programming);如果决策变量是整数或者0-1,那么可以称为整数规划(Integer programming);而如果决策变量是整数和线性混合的,那么可以称为混合整数规划(Mixed-integer programming)。可以利用branch and bound算法解决Mixed-integer programming问题,目前应用的比较多,也有很多成熟的求解器了,比如cplex、lpsolve、国产的solver等等。但是就目前而言,求解器在求解效率上仍存在着问题,难以投入到实际的工业应用中,现在业界用启发式比较多。
2.2 监督学习(supervised learning)
监督学习(supervised learning)的任务是学习一个模型,使模型能够对任意给定的输入,对其相应的输出做一个好的预测。监督学习其实就是根据已有的数据集,知道输入与输出的结果之间的关系,然后根据这种关系训练得到一个最优的模型。
2.3 强化学习(Reinforcement learning)
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。[百度百科]
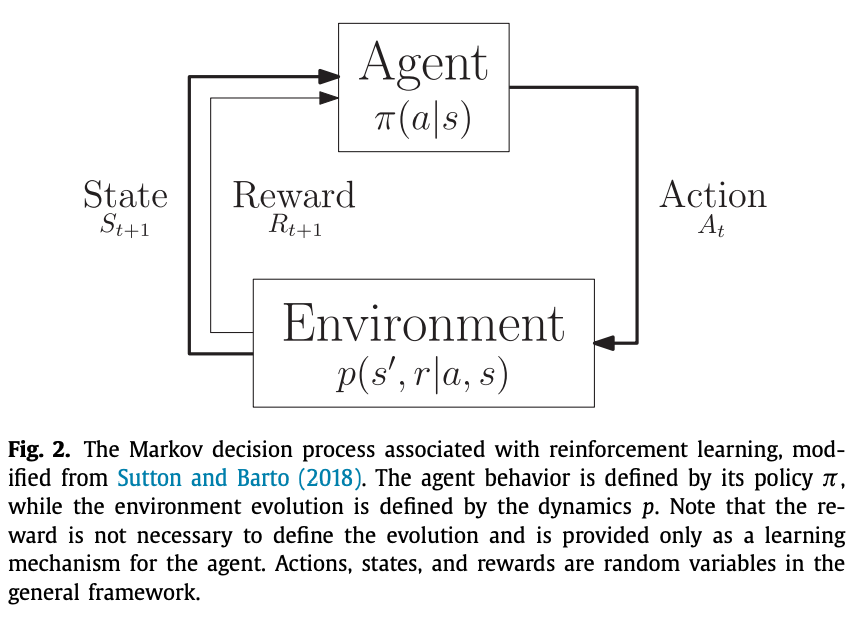
马尔可夫决策过程(Markov Decision Processes,MDPs)
MDPs 简单说就是一个智能体(Agent)采取行动(Action)从而改变自己的状态(State)获得奖励(Reward)与环境(Environment)发生交互的循环过程。
MDP 的策略完全取决于当前状态(Only present matters),这也是它马尔可夫性质的体现。
先行动起来,如果方向正确那么就继续前行,如果错了,子曰:过则勿惮改。吸取经验,好好改正,失败乃成功之母,从头再来就是。总之要行动,胡适先生说:怕什么真理无穷,进一寸有一寸的欢喜。
即想要理解信息,获得输入到输出的映射,就需要从自身的以往经验中去不断学习来获取知识,从而不需要大量已标记的确定标签,只需要一个评价行为好坏的奖惩机制进行反馈,强化学习通过这样的反馈自己进行“学习”。(当前行为“好”以后就多往这个方向发展,如果“坏”就尽量避免这样的行为,即不是直接得到了标签,而是自己在实际中总结得到的)
3 近来的研究
第1节的时候,我们提到了在组合优化中使用机器学习的两种动机,那么现在很多研究也是围绕着这两方面进行展开的。
首先说说动机(1),期望使用机器学习来快速得出一个近似值,从而减少优化算法中某些模块的计算负担,加快算法的速度。比如说在branch and price求解VRP类问题中,其子问题SPPRC的求解就是一个非常耗时的模块,如果利用机器学习,在column generation的每次迭代中能快速生成一些reduced cost为负的路径,那整个算法的速度就非常快了。不过这个难度应该会非常大,希望若干年后能实现吧~
而动机(2)则是尝试一种新的思路来解决组合优化问题吧,让机器学习算法自己去学习策略,从而应用到算法中。比如branch and bound中关于branch node的选取,选择的策略能够极大地影响算法运行的时间,目前常见的有深度优先、广度优先等。但这些方法效果远没有那么出众,所以寄希望于新兴的机器学习方法,期望能得到一些新的,outstanding的策略。
动机(1)和动机(2)下所使用的机器学习方法也是不同的,在开始介绍之前呢,大家先去回顾下第2节中介绍强化学习时提到的Markov链。假设environment是算法内部当前的状态,我们比较关心的是组合优化算法中某个使用了机器学习来做决策的函数,该函数在当前给定的所有信息中,返回一个将要被算法执行的action,我们暂且叫这样的一个函数为policy吧。
那么这样的policy是怎样给出相应的action呢?所谓机器学习,当然是通过学习!而学习也有很多方式,比如有些人不喜欢听老师口口相传,只喜欢不听地做题,上课也在不停的刷题刷题(小编我)。有些人就上课认认真真听课,课后重点复习老师讲的内容。所有的方式,目的都是为了获得知识,考试考高分。同样的,在两种动机下,policy学习的方式也是不一样的,我们且称之为learning setting吧。
动机(1)下使用的是demonstration setting,他是一种模仿学习,蹒跚学步大家听过吧~这种策略呢就是不断模仿expert做的决策进行学习,也没有什么reward啥的,反正你怎么做我也怎么做。他是通过一系列的“样例”进行学习,比如你把TSP问题的输入和最优解打包丢给他,让他进行学习,当他学有所成时,你随便输入一个TSP的数据,他马上(注意是非常快速的)就能给出一个结果。这个结果有可能是最优的,也有可能是近似最优的。当然,下面会举更详细的例子进行介绍。如下图所示,在demonstration setting下,学习的目标是尽可能使得policy的action和expert相近。

动机(2)意在发现新的策略,policy是使用reinforcement learning通过experience进行学习的。他是通过一种action-reward的方式,训练policy,使得它不断向最优的方向改进。当然了,这里为了获得最大的reward,除了使用reinforcement learning algorithms的方法,也可以使用一些经典的optimization methods,比如genetic algorithms, direct/local search。

简单总结一下,动机(1)中的模仿学习,其实是采用expert提供的一些target进行学习(没有reward)。而动机(2)中的经验学习,是采用reinforcement learning从reward中不断修正自己(没有expert)。在动机(1)中,agent is taught what to do。而在动机(2)中,agent is encouraged to quickly accumulate rewards。
3.1 demonstration setting
这一节介绍下目前使用demonstration setting的一些研究现状。(挑几个有代表性的讲讲,详情大家去看paper吧~)
我们知道,在求解线性规划时,通过添加cutting plane可以tighten当前的relaxation,从而获得一个更好的lower bound,暂且将加入cutting plane后lower bound相比原来提升的部分称之为improvement吧。Baltean-Lugojan et al. (2018) 使用了一个neural network去对求解过程中的improvement进行了一个近似。具体做法大家直接去看文献吧,毕竟有点专业。
第二个例子,就是我们之前说过的,使用branch and bound求解mixed integer programming的时候,如果选择分支的节点,非常重要。一个有效的策略,能够大大减少分支树的size,从而节省大量的计算时间。目前表现比较好的一个heuristic策略是strong branching (Applegate, Bixby, Chvátal, & Cook, 2007),该策略计算众多候选节点的linear relaxation,以获得一个potential lower bound improvement,最终选择improvement最大那个节点进行分支。尽管如此,分支的节点数目还是太大了。因此,Marcos Alvarez, Louveaux, and Wehenkel (2014, 2017)使用了一个经典的监督学习模型去近似strong branching的决策。He, Daume III, and Eisner (2014)学习了这样的一个策略--选择包含有最优解的分支节点进行分支,该算法是通过整个分支过程不断收集expert的behaviors来进行学习的。
3.2 experience
开局先谈谈大家非常熟悉的TSP问题,在TSP问题中,获得一个可行解是非常容易的一件事,我们只需要依次从未插入的节点中选择一个节点并将其插入到解中,当所有节点都插入到解中时,就可以得到一个可行解。在贪心算法中,每次选择一个距离上次插入节点最近的节点,当然我们最直接的做法也是这样的。但是这样的效果,并没有那么的好,特别是在大规模的问题中。具体可以参考下面这篇推文:
Khalil, Dai, Zhang, Dilkina, and Song (2017a)构建了一个贪心的启发式框架,其中节点的选择用的是graph neural network,一种能通过message passing从而处理任意有限大小graphs的neural network。对于每个节点的选择,首先将问题的网络图,以及一些参数(指明哪些点以及被Visited了)输入到neural network中,然后获得每个节点的action value,使用reinforcement learning对这些action value进行学习,reward的使用的是当前解的一个路径长度。
结尾
今天先介绍这么多了。以上内容都是小编阅读论文
Machine learning for combinatorial optimization: A methodological tour d’horizon
所得的,基本上翻译+自己理解。但是这个paper还没讲完哦,后面还有些许的内容,容我下篇推文再介绍啦。急不可耐的小伙伴可以直接去看原paper哦。
参考
监督学习(supervised learning)的介绍
https://zhuanlan.zhihu.com/p/99022922
强化学习(Reinforcement Learning)知识整理
https://zhuanlan.zhihu.com/p/25319023
强化学习(Q-Learning,Sarsa)
https://blog.csdn.net/qq_39388410/article/details/88795124
Baltean-Lugojan, R., Misener, R., Bonami, P., & Tramontani, A. (2018). Strong Sparse Cut Selection via Trained Neural Nets for Quadratic Semidefinite Outer-Approx- imations. Technical Report. Imperial College, London.
Applegate, D., Bixby, R., Chvátal, V., & Cook, W. (2007). The Traveling Salesman Prob- lem: A Computational Study. Princeton University Press.
Marcos Alvarez, A., Louveaux, Q., & Wehenkel, L. (2014). A supervised machine learning approach to variable branching in branch-and-bound. Technical Report. Université de Liège.
Marcos Alvarez, A., Louveaux, Q., & Wehenkel, L. (2017). A machine learning-based approximation of strong branching. INFORMS journal on computing, 29(1), 185–195.
He, H., Daume III, H., & Eisner, J. M. (2014). Learning to search in branch and bound algorithms. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, & K. Q. Weinberger (Eds.), Advances in neural information processing systems 27(pp. 3293–3301). Curran Associates, Inc.
Khalil, E., Dai, H., Zhang, Y., Dilkina, B., & Song, L. (2017a). Learning combinatorial optimization algorithms over graphs. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (Eds.), Advances in Neural Information Processing Systems 30 (pp. 6348–6358). Curran Associates, Inc..